
Alex - stock.adobe.com
When to use Amazon RDS vs. Redshift
Amazon RDS and Redshift are effective data warehousing services, but there are key differences that separate the two. Let's compare Amazon RDS vs. Redshift to find their use cases.

Providing secure and reliable data storage is one of the most vital responsibilities of any IT team. If you select the wrong data warehousing service, business performance, budgets and security can suffer. AWS offers many services for storing, managing and analyzing data in a scalable and reliable way. The following are two well-known examples:
- Amazon Relational Database Service (RDS). Manages full database deployments in the cloud and supports widely used database engines, such as MySQL, PostgreSQL, MariaDB, SQL Server, Oracle Database and Db2.
- Amazon Redshift. Manages compute and storage cloud infrastructure to support data warehouse and data lake approaches -- enables Redshift to access and analyze large amounts of data stored internally or remotely.
Essentially, Amazon RDS and Redshift equip application owners with a programmatic way to store and access data and make it available to end users. While these two AWS database services share similarities, they were built to solve different problems. Learn about the key differences in structure, scalability, data access and cost to find out which one to use.
Structure and design
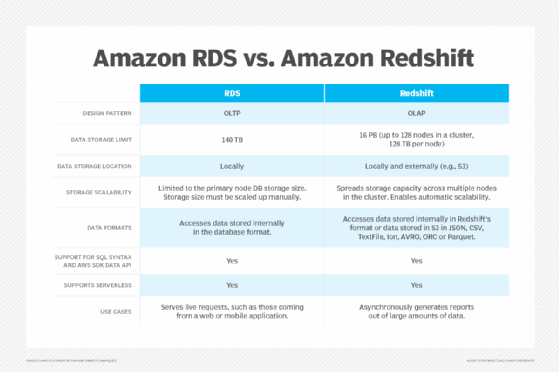
The most important difference between RDS and Redshift is their data processing design.
RDS
As a relational database service, RDS follows an online transaction processing design. OLTP programs follow a transactional process that protects data from concurrent changes and corruption from failed processes. RDS is meant to serve online, real-time transactions that require an immediate response.
Redshift
Redshift follows an online analytical processing (OLAP) approach that organizes data from data warehouses into structured data cubes to prepare it for queries. Redshift suits jobs with longer and heavier data analysis that can be executed asynchronously on much larger data sets than RDS.
Key takeaway
RDS is optimized for real-time transactions, while Redshift focuses on large-scale data analysis.
Data access
RDS databases are not designed to access live data stored outside their local storage system, within the same region and AZ as the database node, and in a predefined format. Redshift can access data stored either locally in the cluster or using Redshift Spectrum data in S3. It also supports a feature that imports data from external sources, such as S3, EMR or DynamoDB, into Redshift storage. Data stored in S3 can also be imported into an RDS database.
For external data, Redshift Spectrum supports multiple formats, such as the following:
- ORC.
- Parquet.
- JSON.
- TextFile.
- Ion.
- AVRO.
- CSV.
Amazon Redshift Spectrum and Serverless also support tables in Apache Iceberg format.
Redshift can store many large data sets, up to 128 TB per node, potentially reaching petabytes of data in a cluster. Most RDS engines have a storage limit of 70 TB, while Aurora has a limit of 140 TB. Redshift is limited only by external data storage limitations. In the case of S3 cloud storage, limits are virtually nonexistent.
Key takeaway
Redshift is designed and optimized to store and access much larger data sets than RDS.
Pricing
Regarding cost, comparing these two services isn't so straightforward.
RDS pricing
RDS pricing is driven by the database engine, instance family, instance size, storage size, I/O usage, multi-Availability Zone (AZ) availability, replication and backups. Features such as multi-AZ or provisioned IOPS can have a significant effect on cost; therefore, it's recommended to evaluate if they're critical in a deployment.
The main cost item is typically the hourly rate for a specific engine and instance type. The most expensive RDS instance, which is Microsoft SQL Server Enterprise db.x2iedn.32xlarge, can reach close to $57,000 per month in a single-AZ deployment. But there are production-ready options that customers can deploy for less than $1,000, such as an RDS MySQL r5.2xlarge.
In the case of Amazon Aurora Serverless, costs are mainly driven by the amount of Aurora Capacity Units (ACUs).
Redshift pricing
Factors that determine Redshift pricing are deployed compute capacity, storage, backups and data transfer across different regions. Like RDS, nodes incur an hourly fee depending on the deployed node type and size.
If left running nonstop, the most expensive Redshift node, ra3.16xlarge, can incur approximately $9,400 per month without counting storage fees. This could make a multinode cluster reach $50,000 to $100,000 monthly. There are also node types, such as ra3.large, that cost approximately $400 per month.
Cost management strategies, such as node and cluster right-sizing, can alleviate costs in both products. Frequent resizing is not always feasible since data is stored inside a Redshift cluster. However, if the application requirements enable data storage in S3, Redshift Spectrum can be a more flexible service enabling cost management depending on usage patterns and the amount of data scanned. Serverless cost is driven by the amount of used Redshift Processing Units (RPUs).
Pricing considerations
The serverless option is an alternative that can lower costs in both services, depending on usage patterns. For applications with unpredictable usage, long idle periods or steep spikes in compute requirements, serverless could be a lower-cost option. For applications with predictable and constant compute requirements, deployed instances could result in lower costs compared to serverless. It is important to evaluate serverless depending on an application's usage patterns and requirements.
For provisioned nodes, both RDS and Redshift support Reserved Instances (RIs). Depending on the commitment term and upfront payment, these can deliver cost savings of approximately 20%-60%. A three-year commitment with a full upfront payment delivers the highest savings in both services. RI savings also vary by instance family and, in the case of RDS, by database engine. Depending on the usage patterns and requirements, RIs are an option to consider in both services as a cost-saving strategy.
Key takeaway
While a Redshift cluster costs more than its equivalent in RDS, Redshift enables significantly higher compute and storage capacity than an RDS deployment.
Provisioning and scalability
RDS
Provisioning an RDS database consists of several steps:
- Launch a database instance.
- Select one of the over 20 RDS instance families, such as T3, M5 or R5.
- Determine the instance size, such as large, xlarge, 4xlarge or others, depending on the family.
- Choose a storage type, either general-purpose SSD or provisioned IOPS.
- Set the storage capacity.
In the case of Amazon Aurora, a MySQL- and PostgreSQL-compatible database within Amazon RDS, the customer must launch a database within an RDS cluster. This cluster consists of a single primary node, an optional number of read replicas and multi-AZ or regional backup alternatives. RDS stores all the source data in a single node. Amazon Aurora allows storage that auto scales, but for other engines, the only way to scale storage is to increase disk capacity in the RDS instance. Adding more read replicas can offload the primary node, but the primary node still stores and manages the source data.
Amazon Aurora also supports a serverless option, for which it's necessary to configure a minimum amount of compute capacity using ACUs.
Redshift
To provision a Redshift cluster, you select the following:
- Node type, such as RA3 or DC2.
- Node size, such as large, xlarge, 8xlarge or others, depending on the node type.
- Number of nodes.
Redshift also supports a serverless option that configures compute and storage capacity using RPUs. In the case of provisioned RA3 nodes, Redshift users can specify the amount of storage per node. Otherwise, node size predefines the storage capacity. Application owners can increase the cluster storage capacity by adding nodes or updating managed storage settings. Data is distributed evenly across provisioned nodes, which delivers scalability to application owners. Compute and storage are distributed across multiple nodes.
Key takeaway
Scalability for a Redshift cluster is much higher than with an RDS deployment.
Real-world use cases
Both RDS and Redshift can solve complex infrastructure and data storage management problems for application owners. However, these are different services that solve different problems. When applied to the right use case, both platforms are powerful and should be considered part of the tool set for deploying modern applications in the cloud.
RDS use case
Consider using RDS to manage relational databases that receive requests coming from a web or mobile application, such as user login, a product catalog search or user details.
For example, an online sales platform could use RDS to access a specific customer profile and retrieve relevant user information during the product checkout process, such as delivery addresses and payment methods, in real time.
Redshift use case
A Redshift cluster is best for generating reports from large amounts of data, such as site traffic reports, user activity, log analysis, market or business reports, billing analysis for large platforms and public data set analysis. Redshift reports can be exported to a format that can be accessed by other application components, such as data visualization tools, internal reports and online applications.
For example, a large-scale online store can use historical data stored in Redshift -- i.e., products, order history or user profiles -- to predict user behavior and recommend certain products in real time, increasing the sales conversion rate on its platform.
Machine learning use case
Both RDS and Redshift can integrate with Amazon SageMaker and serve as data sources for machine learning (ML) training or inference tasks. Redshift ML can also be used to train ML models based on data available in the cluster and to execute internal ML inference tasks through SQL statements.
Editor's note: This article was updated to include additional information on Amazon RDS and Redshift.
Ernesto Marquez is owner and project director at Concurrency Labs, where he helps startups launch and grow their applications on AWS. He enjoys building serverless architectures, building data analytics solutions, implementing automation and helping customers cut their AWS costs.




