
Andrea Danti - Fotolia
Construct a better build-deploy pipeline with these 6 measures
Developers can launch code to production faster than ever, and still do it safely, with careful attention to the build-deploy pipeline, tests and monitoring metrics.

In the early 2000s, daily builds were the norm in the software development world. Almost two decades later, the build is continuous, kicked off with every commit. Rather than create a single Windows executable or a virtual install disk, developers push software updates through a build-deploy pipeline that can run all the way to production.
An operations team and system administrators can manage change control requests and schedule pushes to production, keeping development and operations siloed. However, a build-deploy pipeline with continuous code delivery fits the modern demands on software agility, and can require fewer resources.
Here's how to build a modern end-to-end pipeline quickly, then extend it over time.
1. Start with the build
Continuous integration (CI) starts when users pull the code together, compile it and put it in a place where someone can pick it up. Open source tools like Apache Ant or even shell scripts can poll a version control system for changes, perform a compile and then wait. Modern CI systems can listen to version control and kick off a build every push, which is a change sent into version control.
It's helpful for the build-deploy pipeline engine to trace each commit to a build, along with the duration of each build. Measure the delay from commit to completed build over time; after all, you don't want the continuous system to stop being continuous. You can also track failures and successes over time to see if the build becomes more stable or less so.
It's a good start to get builds up and running, but before you select a tool, consider some other factors.
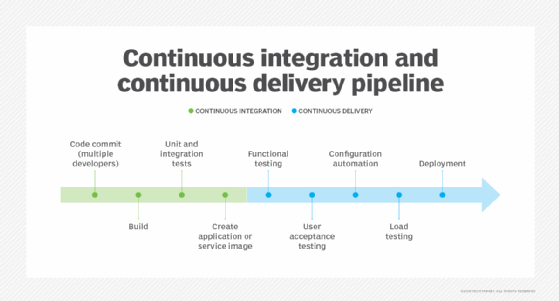
2. Add reporting and notifications
Modern CI systems provide reporting and logging around builds, through a simple web-based interface. Add data visualization to take full advantage of the pipeline monitoring efforts.
For example, let's say a build fails. If the pipeline engine traces each build back to a single commit, the software can determine who broke the build with what action. The CI system can then notify that person or team, including a lead developer or supervisor.
Once the builds and reporting are in place, extend the build-deploy pipeline to catch more problems earlier.
3. Loop in unit tests
Test-driven development produces unit tests, which can quickly check whether a change to one component broke an expectation for that component. Testers must run unit tests frequently and maintain them. Code doesn't rust, but it can evolve with updates to the software, so some failed tests may be false failures; unit test owners should recognize and remove these failures in outdated tests, a process sometimes called greening.
Program the build system to run the unit tests as part of the pipeline. Some teams may decide to tolerate a small amount of unit tests failing, as long as the end-to-end tests continue to pass, but qualify these builds as being yellow (in the traffic light sense). If the team does not accept unit test failures, these builds would come up as red. The goal is to reach the point where test failures are exceedingly rare. Some complex, multiteam builds run unit tests then, only after all tests pass, merge the code into a master branch.
At this stage of your build-deploy pipeline journey, run tests and measure statement coverage to ensure that it increases over time. Tests should generally pass, and failures should send a notification to the programmer who made the commit that caused the failure. If possible, track the mean time to recovery -- the time from when a build fails to when it's fixed.
4. Provision the test environment
Modern web and mobile apps produce a large number of files, everything from static web pages to JavaScript, API code and SQL database changes. That code might live in a web server, application server or database. Additionally, there is often third-party code included in a build. So, what might be a good build on one version of an OS, could fail on another version or with different database drivers.
So, build the web server to fit in and run in a container or virtual machine (VM). The database typically does not need to be virtualized. Container-based application delivery enables a tester to work locally and ensure the application will run the same way in production. Containers also spin up quickly. The CI system can store the containers as artifacts, or even directly in version control.
5. Add integration and system tests
If you choose to adopt a microservices- or API-based approach to software development, you should also adopt integration or API tests in the build-deploy pipeline. These tests define how the API will act in production. Separate the API from the GUI, and the different APIs from each other, to make it possible to deploy individual pieces instead of the entire system.
As long as these individual pieces and APIs maintain the aforementioned tests, the team will have confidence that the entire system will remain stable when updates deploy. Combine this testing rigor with monitoring and rollback in production, and you have a highly resilient system.
6. Move onward to deployment
Depending on the risks involved in a production push, the development team might want to do continuous delivery. The code could deploy changes to staging or a test server, where it undergoes a formalized review and vetting process before deployment. Most CI systems only deliver a build. Getting the notifications and handoffs might require custom code or integration with a system like Atlassian Jira.
Alternatively, you can push changes directly to production, known as continuous deployment. Early-stage startups that chase customers, not dollars, might want to push updates out as soon as the code passes all tests. Twitter, for example, was initially famous for its Fail Whale. But, as the social media network became commercially viable with more advertisements and customers, the company took an increasingly conservative approach to testing and deployment.
Configuration flags. Use of configuration flags, also known as feature flipping, flags or toggles, could provide a way to create a continuous deployment pipeline without as much risk.
Imagine a simple file sitting on disk that is read in -- i.e., a system deciphering and presenting inputted data -- at run time. The file is a list of features, with each feature name followed by a type of user, followed by the letter Y or N for yes or no. Here's a bit of code that might run inside a profile page to show a preview of houses, for example, a new beta feature that might be turned on or off:
if $permissions->{"preview_screen"} {
show_preview_screen();
}
This sort of code makes it possible to deploy changes to production that can only be viewed by authorized users, such as testers, members of a team or the company's employees. It also enables a form of rolling deployment, as the types of users with the feature enabled can extend to friends and family, beta users or people in different geographic regions. If the application periodically reloads this file, then it's as simple as copying a file from version control to the production servers for deployment.
Blue/green and rolling deployment. The cloud enables another possibility. For every change, create a new identical set of virtual servers for the live production environment, which represents the blue (new) line. Switch the traffic to the new servers, but keep the old servers (green) around for some time. This makes it possible to revert changes with the flip of a network connection if there is a problem.
The QuickBooks online team at Intuit uses a similar approach to blue/green deployment, but they roll one server at a time to the updated code and monitor production statistics. If the servers become slow, overloaded, leak memory or throw a large number of 500 status code errors, the system can send alerts and roll back to the previous setup automatically. An advanced build-deploy pipeline enables this kind of monitoring strategy.
There is a great deal more to CI than creating a build. Treat it as a first-class software engineering artifact to deliver the sort of fast test-release cadence that startups, advanced IT departments and enterprises undergoing digital transformation need. Not only does a good build-deploy pipeline shorten time to market, it can reduce risk at the same time.







