HubStor adds continuous data protection, version control

HubStor added continuous data protection and version control to its cloud storage platform.
The continuous data protection (CDP) provides agentless monitoring of specific file system directories to detect new files and capture them, according to Canadian-based HubStor. Uses include backup with a short recovery point objective (RPO) or as a write-once read-many archive for compliance.
Enabling the CDP is a checkbox option with no additional charge or software to deploy it. The default timeframe is 30 seconds.
HubStor, which provides cloud-based data management software, had customers who wanted a “very short” RPO, said co-founder and CEO Geoff Bourgeois. The product previously could run scheduled scans every 30 minutes.
Version control, also a checkbox, goes hand-in-hand with continuous data protection. HubStor introduced version control now because CDP can produce many versions, Bourgeois said.
As HubStor captures incremental changes, the product builds out a version history for each file. Point-in-time awareness in the cloud enables an organization to restore data at a known healthy time, for example the moment before a ransomware attack hit.
Over time, an organization can prune its versions and phase them out — for example through a setting of one version per month — which can help “control the storage growth in the cloud,” Bourgeois said.
HubStor at ‘a neat stage’
HubStor, founded in 2015, claims nearly 100 customers and expects to hit the century mark by the end of the year.
“We’re at a neat stage in the company’s history,” Bourgeois said, noting HubStor does not have any venture capital funding and does not carry debt, making money through a consumption-based business model.
Typical customers are medium to large enterprises, with hundreds of terabytes under management. Customers are starting to get into the multi-petabyte range, as a new one is moving 5 PB into HubStor, Bourgeois said.
HubStor is closely tied to Microsoft and uses Azure for its back end. Its software-as-a-service approach provides a fully managed product for customers, Bourgeois said.
In addition to backup and recovery, HubStor offers tiering and retention capabilities.
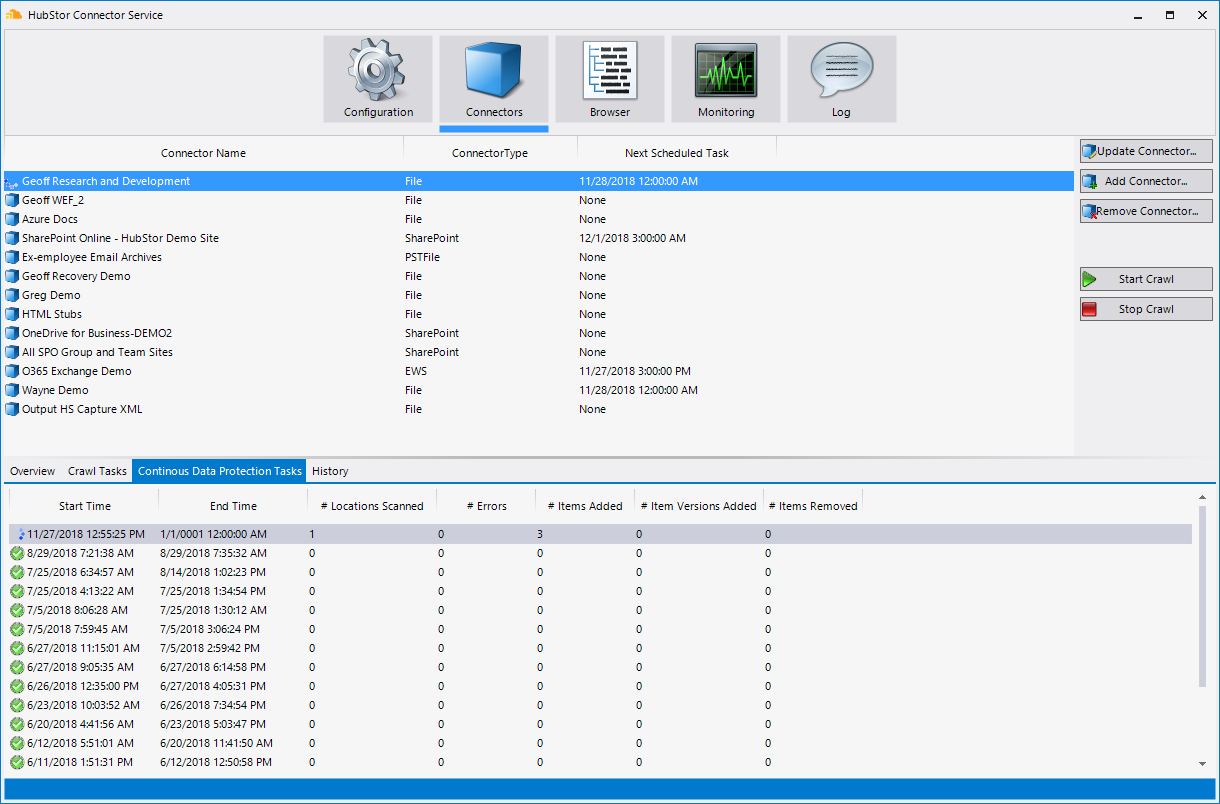
A file system runs the HubStor continuous data protection. (Screenshot courtesy of HubStor)
KUKA, a global robotics manufacturing and implementation company, had a lifecycle problem with its file retention. It had nearly 75 TB of archived data with retention requirements.
After looking at a few vendors, including Nasuni and NetApp, KUKA found that HubStor handled archive tiering the best, said systems administrator Troy Dieter.
Since implementing HubStor six months ago, KUKA has recouped about 60 TB of SAN storage. That data is tiered and stored in HubStor’s tenant, Dieter said. Both HubStor and Veeam helped KUKA shift off of tape for archiving.
KUKA uses the search feature often. The company has about 75 million files just in archives, so being able to search quickly is valuable.
Dieter said he would demo the new CDP and version control features, but noted that he is satisfied with his company’s use of Veeam for backup.
“I’m eager to see what they’ve built in for their backup and retention,” he said of HubStor.
Dieter said a user experience refresh in the HubStor Connector Service — the storage transit agent — would be helpful, as it can get a little confusing.
HubStor aims to add continuous data protection support for Office 365 in early 2019, as customers require short RPOs for that data, Bourgeois said. Version control settings are available for Office 365.
Bourgeois said Veeam and SkyKick offer similar technologies and HubStor also sees startups Cohesity and Rubrik competing for some similar deals. HubStor has a leg up because of its consumption pricing model, with nothing owed upfront, Bourgeois said.