

The world of data protection is changing rapidly. After many years witnessing these changes as a vendor, and now as an analyst, I have developed a maturity model: the backup data transformation model. This model will help both end-users and vendors evaluate their current position and their journey from data backup to autonomous data intelligence and whether they can cross the data management chasm. Did I get your attention? Please read on.
The data protection market, which includes backup and recovery, disaster recovery, and replication, amongst others, is changing and is on the cusp of a major evolution.
There are four stages to my model: the baseline and cloud-enabled stages which are separated by what we coined the data management chasm, an obstacle towards the other 2 stages: the data intelligent and autonomous stages.
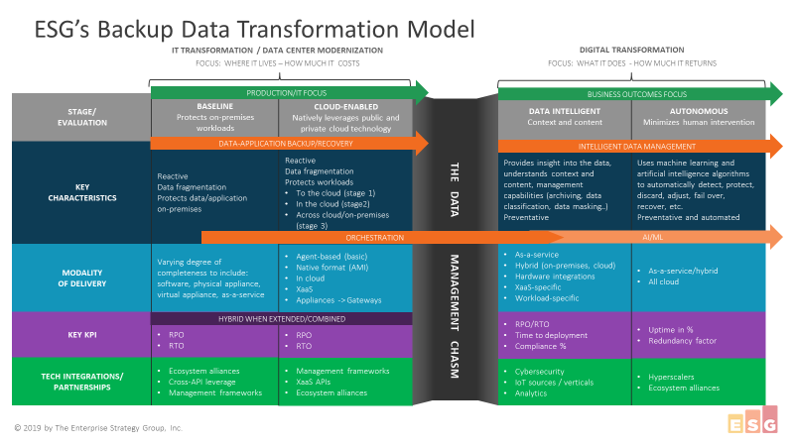
Let’s review the baseline stage, which corresponds to on-premises workloads protection. It is the traditional backup and recovery space, one in which software, appliances – physical or virtual- and some services – support the desired KPIs which are the RPOs and RTOs of organizations that leverage these technologies. In this stage, we see a complex and go-to-market-focused ecosystem of alliances and technical integrations, which has taken many years to evolve. Data is also typically fragmented, or organized in “silos.”
The market is changing rapidly with the rapid adoption of cloud-based technologies to extend the traditional on-premise environments. In the context of backup and recovery, it means solutions and technologies that, in time, will seamlessly and natively leverage public and private cloud infrastructures, protecting workloads to the cloud, in the cloud and across cloud and on-premises infrastructure.
All of this requires significant orchestration to coordinate data movements, application and virtual machine failover or restarts, disaster recovery runbooks, etc. This cloud stage is in constant evolution and still offers many opportunities for vendors to improve their capabilities to help end-users achieve coherent RPOs and RTOs in what has become a hybrid infrastructure. I predict that these 2 stages will merge in the next few years, in other words, technology and solutions will evolve to make on-premises and cloud-enabled data protection more seamless. There is still plenty of work ahead, in particular for the protection of SaaS-based applications, for example.
As you can see, the stages on the left of the chasm are still evolving and offering many challenges to IT leaders to deliver coherent and predictable service levels. The infrastructure tends to evolve as a reaction to changes in other parts of the environment, such as the adoption of new platforms that now need to be backed up.
Hybrid data protection, even when fully and natively cloud-enabled, still deals with “dumb” data. What I mean here is that while there is some granular level of understanding of what data is backed up, where it went, how old it is, etc., backup data is not really portable across solutions, is not easily re-usable, and offers very little insight into the data itself.
This is where a fundamental change is happening.
The requirement for context and content about the data is becoming more acute as new regulations and the need for use of data to support digital transformation are changing the role of data in the enterprise. Data has to be more intelligent. It’s really about business outcomes and the notion of data as a true asset that can be leveraged to create a return on investment, or avoid costs and risks.
Many vendors talk about data management but no one has truly defined what this means. It really should be called “Intelligent Data Management,” meaning that beyond backup and recovery use cases, the solutions or systems performing these operations can also provide insight into the data, understand the context and the content of it, and deliver management capabilities. One simple example is the classification of data, for example, knowing what you have, where it lives, performing masking operations on it, etc.
In this new stage, we expect to see some new players with specialized solutions and new approaches to solving customer problems, thinking more in terms of data processes rather than data movement and storage only. We expect the modalities of delivery to be workload-specific originally, and probably vertically-focused.
We also expect to see artificial intelligence and machine learning integrations enrich the management and quality of the management process.
This takes us to our fourth and last stage, one that I call autonomous intelligent data management. Just like intelligent data management, the solutions are designed to be preventative rather than reactive. In this stage, the acceleration of AI and ML allows for processes to be highly automated and minimize human intervention, offering significant opportunities for operational efficiencies, and higher uptime and service levels.
This model can be used by end-users and vendors alike to establish their levels of maturity in each of the stages, and their strategic objectives on this journey to autonomous and intelligent data management.




