autoscaling

What is autoscaling?
Autoscaling provides users with an automated approach to increase or decrease the compute, memory or networking resources they have allocated, as traffic spikes and use patterns demand. Without autoscaling, resources are locked into a particular configuration that provides a preset value for memory, CPU and networking that does not expand as demand grows and does not contract when there is less demand.
Autoscaling is a critical aspect of modern cloud computing deployments. The core idea behind cloud computing is to enable users to only pay for what they need, which is achieved in part with elastic resources -- applications and infrastructure that can be called on as needed to meet demand.
Autoscaling is related to the concept of burstable instances and services, which provide a baseline level of resources and then are able to scale up -- or "burst" -- as memory and CPU use come under demand pressure.
How does autoscaling work?
Autoscaling works in a variety of ways depending on the platform and resources a business uses. In general, there are several common attributes across all autoscaling approaches that enable automatic resource scaling.
For compute, memory and network resources, users will first deploy or define a virtual instance type that has a specified capacity with predefined performance attributes. That setup is often referred to as a launch configuration -- also known as a baseline deployment. The launch configuration is typically set up with options determined by what a user expects to need for a given workload, based on expected CPU use, memory use and network load requirements for typical day-to-day operations.
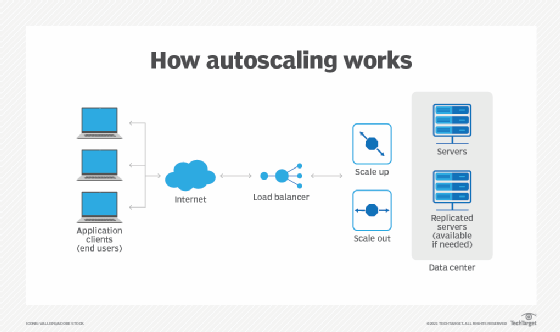
With an autoscaling policy in place and enabled by an autoscaling technology or service, users can define desired capacity constraints so more resources can be added as traffic spikes stress resources. For example, with network bandwidth autoscaling, an organization can set a launch configuration with a baseline amount of bandwidth and then set a policy that will enable the service to automatically scale it up to a specified maximum amount to meet demand.
The actual delivery of more resources in an autoscaling technology or service varies. In some cases, a service will automatically provide more capacity to a given resource. In other cases, the autoscaling policies will launch new resources that add to the total pool of virtual instances already deployed by a user to meet traffic spike demand.
What is the purpose of autoscaling?
Autoscaling enables cloud application workloads and services to deliver the optimum performance and accessibility service levels necessary under different conditions.
Without autoscaling, resources are strictly defined and constrained within a set configuration for a given set of resources. For example, if an organization has a large analytics workload that it needs to process, it might require more compute and memory resources than initially defined. With an autoscaling policy in place, compute and memory can automatically scale to process the data in a timely fashion.
Autoscaling is also necessary to help ensure service availability. For example, an organization could configure an initial set of instance types that it expects will be sufficient to handle traffic for a particular service. If a traffic spike occurs due to an event, such as Black Friday shopping, there can be a significant change from a typical use pattern for a service site. To maintain service availability in the event of a traffic spike, autoscaling can deliver the necessary resources for a service to continue executing operations efficiently while meeting customer demand.
Types of autoscaling
Fundamentally there are three types of autoscaling:
- Reactive. With a reactive autoscaling approach, resources scale up and down as traffic spikes occur. This approach is closely tied with real-time monitoring of resources. There is often also a cooldown period involved, which is a set time period where resources stay elevated -- even as traffic drops -- to deal with any additional incremental traffic spikes.
- Predictive. In a predictive autoscaling approach, machine learning and artificial intelligence techniques are used to analyze traffic loads and predict when more or fewer resources will be needed.
- Scheduled. With a scheduled approach, a user can define a time horizon for when more resources will be added. For example, ahead of a major event or for a peak time period during the day, rather than waiting for the resources to scale up as demand ramps up, they can be pre-provisioned in anticipation.
Benefits of autoscaling
There are many benefits that come with using an autoscaling technology or service, rather than having a statically configured instance type in a deployment that does not automatically scale. These benefits include:
- Lower cost. Without autoscaling, organizations and cloud users must provision more resources on an ongoing basis to be able to handle potential traffic spikes and changes in traffic patterns. Autoscaling enables resources to scale up only when needed and scale down when traffic subsides. It is one way for businesses to reduce cloud costs.
- Automation. Organizations can manually add resources when needed, but that is not a scalable or efficient approach. Because it is automated and policy-driven, autoscaling activates when needed, providing a more optimized approach than manual scaling.
- Reliable performance levels. By defining autoscaling policies, cloud administrators can define desired performance levels and ensure they are achieved and maintained.
- Improved fault tolerance. Services can go down for any number of reasons, including errors and problems with application logic or even faulty hardware. With autoscaling, the health and performance of a workload is constantly monitored to replace and automatically scale resources when needed.
- Service availability. Cloud services can become unavailable if they are overwhelmed with resource-intensive workloads or more traffic than the configured instances are set up to handle. Autoscaling can ensure service availability in the event of such a traffic spike.
Autoscaling vendors
Several vendors provide autoscaling services and technologies. Each of the major public cloud providers has its own services to enable autoscaling capabilities. Third-party services, often lumped under "cloud management platforms," enable organizations to optimize cloud deployments, including autoscaling policies that hook into a cloud provider platform.
Some cloud vendors that provide autoscaling capabilities include:
- Amazon Web Services (AWS). AWS has multiple autoscaling services, including AWS Auto Scaling and Amazon EC2 Auto Scaling. AWS Auto Scaling is a service for users who need to scale resources across multiple AWS services. In contrast, the Amazon EC2 Auto Scaling service is focused on providing autoscaling capabilities for Amazon EC2 instances that provide virtual compute resources.
- Google Compute Engine (GCE). GCE provides autoscaling capabilities as a feature for its cloud users running managed instance groups of virtual machine (VM) instances. Managed instance groups are an optional deployment approach on Google Compute Engine, where groupings of identical virtual machines are deployed across GCE in a managed approach to enable higher availability.
- IBM Cloud. IBM has a module known as cluster-autoscaler that can be deployed on IBM Cloud workloads. This autoscaler can increase or decrease the number of nodes in a cluster based on the sizing needed as defined by scheduled workload policies.
- Microsoft Azure. For users of the Microsoft Azure cloud platform, the Azure AutoScale service enables automatically scaling resources. Azure AutoScale can be implemented with VM, mobile and website deployments.
- Oracle Cloud Infrastructure. Oracle has multiple autoscaling services across its Oracle Cloud Infrastructure platform, including Compute Autoscaling and a flexible load balancer that enables elastic load balancing for network traffic.
Continue Reading About autoscaling
Dig Deeper on Cloud infrastructure design and management
-
![]()
Google GCP Solutions Architect Certification Exam Dump and Braindump
By: Cameron McKenzie
-
![]()
Google Professional Cloud Architect Sample Questions
By: Cameron McKenzie
-
![]()
CGP Certified Professional DevOps Engineer Sample Questions
By: Cameron McKenzie
-
![]()
Google Certified DevOps Engineer Exam Dumps and Braindumps
By: Cameron McKenzie



