
kran77 - Fotolia
Know the tools needed to bake cloud HA into apps
The cost for HA might outweigh the benefit for many cloud apps. But, before you can debate the need to architect a highly redundant system, you need to know the tools at your disposal.

High availability is vital to mission-critical enterprise applications, but it isn't free or easy.
Enterprises use resiliency and redundancy technologies to ensure their workloads remain available in the face of internal and external disruptions. The public cloud offers a range of services to implement and manage critical workloads, but HA adds cost and complexity.
So, how much HA is too much? Today's public clouds have global reach and incredible scalability, which enterprises can use to achieve dramatic levels of workload availability. But HA isn't about more resources; it's about applying the right amount of resources to a given workload. Thus, knowing where to stop with cloud HA can sometimes be more important than knowing where to start.
The implications of cloud HA
Highly availability infrastructure involves several key elements, so organizations need a firm understanding of the tools at their disposal -- before they conduct any cost-benefit analysis. Let's start with an overview of those components in a public cloud such as AWS, Google Cloud or Microsoft Azure.
Physical locations
IT teams find and eliminate single points of failure (SPOFs) to improve reliability and availability. A cloud region itself can be one of those failure points, since those regions can be temporarily compromised -- typically, due to a networking problem.
Thus, organizations usually achieve HA in the public cloud by distributing redundant instances across cloud regions or availability zones (AZs) -- typically, two or more distinct cloud data centers within a region. Specific AZs may be selected to guard against simple physical incidents, such as fire or flood, or to host the workload closer to the desired user base.
Networking
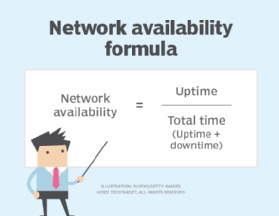
Although public cloud users have no influence over a particular cloud's networking infrastructure, network connectivity is acutely important when data needs to be transferred between the cloud and local storage or apps. High-bandwidth internet connections are usually adequate, but bandwidth- or latency-sensitive workloads may require dedicated connectivity, such as Azure ExpressRoute or AWS Direct Connect. Such connection options are not highly resilient in and of themselves, but they are resistant to internet traffic congestion and other network access issues.
Compute instances
When HA is applied to an application, two or more redundant servers are used to protect the application. In public clouds, servers take the form of compute instances, such as Amazon EC2 instances, Azure VMs and Google Compute Engine instances. Containers are also viable for an increasing variety of workloads. Compute instances can be organized into a cluster, or backup instances can be configured for failover. Each additional instance will add cost and complexity to the cloud HA infrastructure.
Storage instances
Applications need data, and data is typically committed to storage instances, such as Amazon S3, Azure Blob Storage or Google Persistent Disk. Cloud storage services are typically designed to be highly available, so data won't necessarily need to be replicated to multiple regions or AZs. However, workloads where HA spans regions may also need to replicate storage resources in each location to guard against a location failure and ensure adequate performance.
For example, it's possible for a single storage resource in one region to serve workloads in different regions. But, if that region should fail, none of the other workload instances can function. Don't let storage become a SPOF for the application.
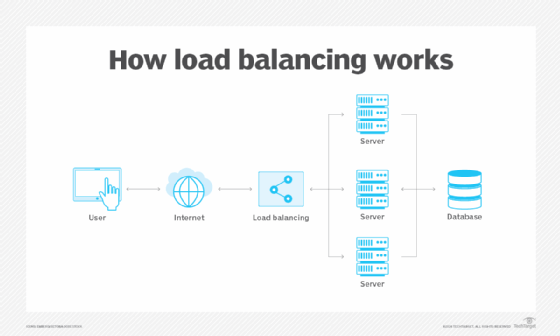
Load balancing
Redundancy requires a means of managing traffic to multiple compute instances -- a service called load balancing. If one instance fails, the load balancer can redirect traffic to other instances, even if those instances span across AZs. Cloud providers offer load-balancing services, such as AWS Elastic Load Balancing, Azure Load Balancer or Google Cloud Load Balancing. Load balancers are often a core element of a workload's health monitoring and diagnostics system. They're typically the first component to detect, report and adjust to an instance failure.
IP cutover
Not all cloud HA strategies use clusters. Organization can rely on a standby instance that's waiting and ready to run, or they can use a replacement instance. Regardless, the IP address of the failed instance must be remapped to the alternate instance to successfully redirect traffic. Services such as AWS Elastic IP addresses and static public IPs in Azure provide public IP addresses that can be mapped between instances. This redirects traffic to various instances programmatically.
Monitoring
Proper monitoring ensures adequate performance under regular conditions. Monitoring can help to validate uptime availability for service-level agreement purposes, such as when the workload carries an SLA for its users -- not a cloud provider's. It can also reveal availability problems and track cloud resource usage. Tools such as Amazon CloudWatch are capable of collecting data and metrics around workload deployments.
Let business needs decide
Applying HA to a workload can be thought of as a kind of insurance -- the business is spending extra money to protect itself and its workloads from certain risks. As with everyday insurance, it is possible to insure against almost anything.
But how much protection does the workload really need, and does the business really benefit from the protection being purchased? Every application owner needs to answer these hard questions and apply the right protection to each workload in the cloud.
Editor's note: Click here to read the second part of this tip, which will cover the fundamental questions organizations need to ask themselves before they deploy HA techniques for their cloud apps.
Dig Deeper on Cloud infrastructure design and management
-
![]()
Google GCP Solutions Architect Certification Exam Dump and Braindump
By: Cameron McKenzie
-
![]()
Google Professional Cloud Architect Sample Questions
By: Cameron McKenzie
-
![]()
Google Cloud Architect Certification Practice Exams
By: Cameron McKenzie
-
![]()
Google Cloud Data Engineer Practice Exam Questions
By: Cameron McKenzie



