Different types of cloud load balancing and algorithms
Learn how load balancing in the cloud differs from a traditional network traffic distribution, and explore services from AWS, Google and Microsoft.

To understand the value and behavior of load balancing, consider a visit to your local bank. If only one teller is available, every customer must rely on the services of that one teller, which results in long waits for service and tremendous stress for the teller. With multiple tellers, waiting customers line up in a queue and are helped by the next available teller. The line goes much faster, and service is far less disrupted if one teller has problems.
In this simple example, each of the tellers is an identical instance of a workload, and the familiar roped queue serves as a load balancer to efficiently distribute user requests to those workload instances.
What is load balancing?
Load balancing is the process of distributing network traffic across two or more instances of a workload. In most cases, the network traffic is related to an enterprise application, such as a website or other high-utilization software, and each instance is a server upon which a copy of the application runs. IT teams use load balancing to ensure each instance performs at peak efficiency without any one instance becoming overburdened or failing due to excess network traffic.
Traditionally, a load balancer exists in a local data center as a dedicated physical network device or appliance. However, load balancing is more frequently performed by an application installed on a server -- sometimes called a virtual appliance --- in the form of a VM or virtual container and offered as a network service. Public cloud providers use the service paradigm and provide software-based load balancers as a distinct cloud feature.
This article is part of
What is cloud management? Definition, benefits and guide
Once a load balancer is introduced, it acts as a network front end and often uses a single IP address to receive all network traffic intended for the target workload. The load balancer evenly distributes the network traffic to each available workload instance or throttles traffic to send specific percentages of traffic to each instance.
For example, if there are two identical workloads, a load balancer ensures that each instance receives 50% of the incoming network traffic. However, the load balancer also can alter those percentages to, say, 60% and 40% or implement a "first available" rule or other rules to tailor the traffic flow to each workload instance's capabilities and strengths.
With a load balancer, the target workloads can be in different physical places and support activities such as distributed computing. Cloud load balancing provides similar benefits that enable users to distribute network traffic across multiple instances in the same region or across multiple regions or availability zones.
What are the benefits of cloud load balancing?
Load balancing provides the same set of benefits, regardless of whether it lives in a local data center or a cloud environment:
- Better workload scalability and performance. A single workload or application is fine as long as it handles the incoming traffic and requests in a timely manner, but sometimes, a business must add workload instances to handle higher network traffic volumes and sudden and unexpected spikes in traffic. A load balancer is critical here to queue and distribute that traffic across multiple instances so the overall application runs efficiently -- without annoying lags and delays -- and provides a satisfactory experience for the user.
- Better workload reliability. When a single workload handles 100% of incoming requests, the underlying hardware and software pose a single point of failure for the workload. If the workload hardware or software fails, the workload becomes entirely unavailable until the problem is remediated. Adding more workload instances and load balancing the traffic between them can dramatically enhance workload resiliency and availability. If one workload instance (node) fails, others continue to function and direct traffic to remaining instances. This is the heart of high availability workload deployments.
- Better business continuity (BC) and governance. For many businesses, application availability and related issues, such as disaster recovery, are central to business continuance, governance and regulatory compliance. The implementation of multiple workloads into a cluster and sharing traffic with load balancers is a primary means to boost workload reliability, which, in turn, benefits BC and helps the business meet compliance obligations.
- Cost savings. Load balancing can save money for the enterprise, enabling critical workloads to operate on multiple, less-expensive hardware platforms instead of a single, costly hardware server. When combined with the benefits of better performance and reliability, load balancing can provide significant cost savings, though such benefits can be challenging to quantify objectively.
What are the deployment options for load balancing in cloud computing?
Enterprises can implement load balancing in several different ways and tailor it to benefit or emphasize specific traffic goals. The following are the three most common deployment models:
- Hardware. This is a traditional physical box of circuitry connected to the physical network. A hardware load balancer can include chipsets that are designed specifically to handle traffic at full network line speeds. For that reason, these load balancers are typically installed in high-volume data centers where performance is a top priority.
- Software. Software installed on a regular enterprise server also can perform load balancing. This option is typically far less expensive than dedicated hardware load balancers, and upgrades are usually easier than with dedicated load-balancing devices.
- Virtual instances. An enterprise can package load-balancing software into a VM or virtual appliance and then deploy it on a virtualized server. This process is simpler because the load-balancing software is already installed and configured in the VM, and it can be migrated easily between virtual servers just like any other VM. Virtual instances are often deployed as services in data centers, as well as private cloud- and public cloud-based service offerings.
Cloud load balancing and network traffic Layer 3 vs. 4 and 7
Load-balancing types are defined by the type of network traffic, based on the traditional seven-layer Open Systems Interconnection (OSI) network model (see Figure 1). Cloud load balancing is most commonly performed at Layer 3 (network layer), Layer 4 (transport or connection layer) or Layer 7 (application layer).
Layer 3
Layer 3 (L3) is the lowest level where load balancing is performed. Since the balancing is done so close to the hardware, the emphasis is on recognizing and directing traffic based on IP addresses. That is, traffic is directed based on where it's going or where it's coming from rather than what each packet contains. L3 offers the fastest and most efficient solution for high-volume, enterprise-class traffic control. L3 load balancers often integrate easily and use venerable protocols, such as Border Gateway Protocol, and equal-cost multipath routing. L3 is an excellent choice for distributed computing because it can easily direct traffic between data centers in varied geographical locations.
Layer 4
Some cloud load-balancing services operate at Layer 4 (L4) to direct data from transport layer protocols, including TCP, User Datagram Protocol (UDP) and Transport Layer Security. L4 load balancers use IP addresses and port numbers for great versatility and granularity in traffic direction. Load balancing at this lower level of the network stack provides the best performance -- millions of network requests per second with low latencies -- and is a great option for erratic or unpredictable network traffic patterns. L4 load balancers can also evaluate and choose routing paths, enabling managed connections for persistent or stateful network communication. L4 load-balancing services include AWS Network Load Balancer, Google Cloud TCP/UDP Load Balancing and Microsoft Azure Load Balancer.
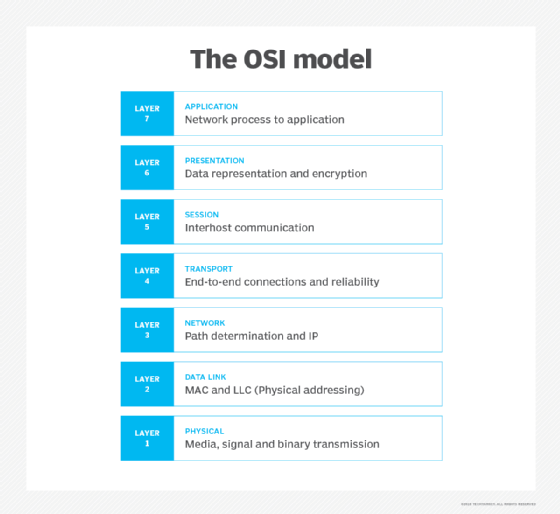
Layer 7
At the top of the network stack, Layer 7 (L7) handles some of the most complex network traffic, such as HTTP and HTTPS requests. Each of the major cloud providers has its own feature or service for this:
- AWS Application Load Balancer.
- Azure Application Gateway.
- Google Cloud HTTP(S) Load Balancing.
Since L7 traffic is much higher up the network stack, IT teams can use L7 load balancers to implement session persistence, as well as more advanced content-based or request-based routing decisions that are based on packet contents and application-specific requirements. These options work well with modern application instances and architectures, such as microservices and container-based workloads.
Other considerations in choosing load-balancer levels
The choice of a cloud load balancer should extend beyond traffic types alone. Cloud providers also differentiate load-balancing services based on scope and framework. For example, Google Cloud suggests global load-balancing services when workloads are distributed across multiple regions, while regional load-balancing services are a good fit when all the workloads are in the same region. Similarly, Google Cloud suggests external load balancers when traffic comes into the workloads from the internet and internal load balancers when traffic is intended for use within Google Cloud.
The broader features and capabilities available with providers' cloud load-balancing services can be valuable as well. They include support for a single front-end IP address, support for automatic workload scaling and integration with other cloud services, such as monitoring and alerting.
What are the different types of cloud load-balancing algorithms?
By default, load balancers distribute traffic equally using a balanced or round-robin type of distribution. For example, if a single network input is balanced to three servers, each server simply receives 33% of the incoming traffic. However, such simple algorithms are not always ideal for every situation, especially when there is a significant difference in server types and operating environments. Load balancers can often use several enhanced load-balancing algorithms, both in local data centers and in public cloud services, to distribute traffic to the different workload nodes based on more sophisticated criteria. These algorithms include the following:
- Round robin (balanced). This method divides incoming traffic requests evenly across all the workload instances (nodes). For example, if there are three workload instances, the load balancer rotates traffic to each instance in order: request 1 to server 1, request 2 to server 2, request 3 to server 3, request 4 to server 1 and so on. Round robin works well when all nodes are identical and have similar computing capabilities.
- Weighted round robin. Some workload instances use servers with different computing capabilities. Weighted round robin can shift the percentage of traffic to different nodes by assigning a weight to each node. More capable nodes receive higher weighting, and the load balancer sends more traffic to them.
- Least (busy) connection. Traffic is routed to workload instances with the fewest connections or shortest queue, which means they are the least busy instances. This dynamic approach eases demands on instances that have complex processing requests.
- Weighted least connection. This algorithm assigns a weight to each node so administrators can shift the distribution of traffic based on connection activity. It can end up like round robin or weighted round robin if all nodes are identical, but ideally, it compensates to give more traffic to idle or more powerful nodes and equipment.
- Resource-based. This adaptive approach uses a software agent on each node to determine the computing load and report its availability to the load balancer, which, in turn, makes dynamic traffic routing decisions. It can also employ information from software-defined networking controllers.
- Request-based. Load balancers, especially in the cloud, can distribute traffic based on fields in the request, such as HTTP header data, query parameters, and source and destination IP addresses. This helps to route traffic from specific sources to desired destinations (persistent connections) and maintain sessions that may have been disconnected.
Cloud load-balancing tools
Major public cloud providers offer native load-balancing tools to complement cloud service suites, but cloud users are not limited to these options. There are many powerful and full-featured software-based load balancers, which an enterprise can deploy to local data centers and cloud instances with equal ease. Popular cloud-native and third-party principal load balancers include the following:
- Akamai (formerly Linode) NodeBalancers.
- AWS Elastic Load Balancing.
- Azure Load Balancer.
- Cloudflare Load Balancing.
- DigitalOcean Load Balancers.
- F5 Nginx Plus.
- Fastly Load Balancer.
- Google Cloud Load Balancing.
- Imperva Global Server Load Balancing.
- Kemp LoadMaster.
- VMware Avi Load Balancer.
- Zevenet ZVA6000 Virtual Appliance Load Balancer.
It's worth noting that some web application firewall platforms include some load-balancing functionality, including Barracuda Networks Web Application Firewall and Citrix NetScaler Web App Firewall.
When selecting a load balancer, consider the complete suite of features and functions to ensure that the load balancer meets application and business demands well into the future. Such features include support for security and encryption, performance and scalability, support for hybrid cloud and multi-cloud environments, cost and more.
Stephen J. Bigelow, senior technology editor at TechTarget, has more than 20 years of technical writing experience in the PC and technology industry.







