
Getty Images
How to survive a cloud service outage
Outages might be rare, but they are rarely cheap -- any amount of downtime can cost you money. Learn how to minimize the risks and survive a cloud service outage.

One of the key benefits of the cloud is that it rarely goes down. Cloud data centers are built in earthquake-safe areas where flooding and natural disasters are not common. While it's unlikely to have an external issue that takes out a cloud, a configuration or service issue that causes an outage is possible.
Typically there are many safeguards against hardware failure, meaning the odds are extremely low. But being down for even a few minutes is hard to deal with. Especially when you're in the middle of an outage and you don't know when you will be back online. Follow these tips to survive a cloud service outage.
Understand your SLA
First, check what's in the service-level agreement (SLA) for the product or service you're using. A published SLA won't be for everything; it's typically done by each service so the cloud vendor can advertise the services with the higher SLA and push the ones with a lower SLA to the bottom of the marketing pile.
When presented with a collection of SLA values from providers, base your overall SLA at the lowest SLA value of all your services. This becomes the baseline for your application stack. Keep in mind if one service in your environment is offline, your application can be offline completely. It doesn't really matter that only "one" service has gone offline and everything else is still up and running because if your application needs that service to be complete, you are offline.
Uptime
In SLAs, you often see something is 99%, 99.9% or 99.95% online. While this may not seem like a big value difference, the actual time of these values adds up.
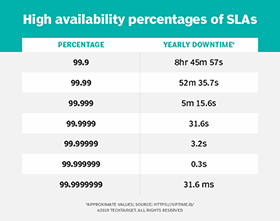
An SLA of 99.9% averages to 1 minute and 26 seconds per day. Yearly, this averages to 8 hours and 41 minutes. These outages will most likely occur on a critical day when you can least afford it. For example, if you're a retail business, an outage on Black Friday can have a detrimental impact.
When you go from 99.9% to 99.99% online, the outage time goes down to 8.6 seconds a day and 52 minutes a year. This difference in outage time comes with a huge difference in cost. Management and accounting teams might push for a lower SLA in the 99% or 98% range to save money, not realizing the outage windows for those might not save money in the long run. Balance costs with the knowledge of how much outage time you will eliminate.
What do you get when the outage violates your SLA?
You will not get your losses for the outage time covered. However, you will get service credit. For example, if your service is down for 8 hours, you may get a percentage of that money credited back. That means if the service in question was $20 an hour and it's covered at 50% you would get back $80 for that outage. This is going to be dependent on what service you are using and that is where reading and understanding the SLA will come in handy. If you lost millions of dollars in sales during the outage time, you are still walking away with $80. This is often overlooked as people think they will get a percentage of what they lost in that time period, which is not the case.
What you lose will depend on what you're doing in the cloud and what the impact of losing a system might be. Some companies are fine with losing email for a day, and for others, it can be a disaster that they might not be able to recover from. The impact is personalized to the client which is difficult to put a number on.
What can you do to minimize the impact of an outage?
There are several options to minimize the impact of an outage, but you may run into trouble implementing these practices.
You could do a multi-cloud deployment where your application or needs are spread across two different cloud instances. While it's possible to split an application between two clouds that doesn't really give you redundancy, what you need is the same full application stack in both clouds which costs money. This is like having a hot site data center, which many avoid due to hardware costs and commitments.
Having reliable backups is critical to ensure data is protected, but it won't help prevent outages. Unfortunately, you have little control over these outages since it's not your data center or a place where you have a say in the operations. In this scenario, you are a customer and not the manager and have to wait in line like everyone else.
Since it's doubtful you will get the money to do a replicated cloud instance, be aware of what can happen. Outages will occur, nothing is 100% all the time. You can have a critical system outage in a cloud but if you're aware of the risk, you will have plans and procedures on how to deal with it. It might be a manual process that isn't efficient, but it will work. If you can't prevent it or afford to prevent it, create the policies and procedures to adjust to it.
Brian Kirsch, an IT architect and MATC instructor, has been in IT for more than 20 years, holds multiple certifications, and sits on the VMUG Board of Directors.






