Free DownloadData Storage Management: What is it and Why is it Important?
With this guide, explore what data storage management is, who needs it, advantages and challenges, key storage management software features, security and compliance concerns, implementation tips, and vendors and products.
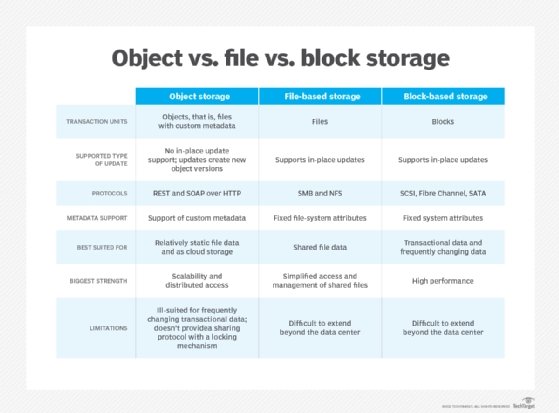
Block vs. file vs. object storage: Differences explained
Object storage has surged in popularity, but block and file still have clearly defined uses. Access, metadata and performance are among admins' key considerations.
Block, file and object storage are popular storage types, both in the cloud and on-premises. They all have benefits but also some clear drawbacks that admins need to consider.
In comparing block storage vs. file storage vs. object storage, explore their unique characteristics, and choose the appropriate one based on use.
What is block storage?
Block storage works by organizing storage media into a series of equally sized storage blocks.
These blocks can be anywhere from a few kilobytes to a few megabytes in size, depending on the storage hardware.
Many modern file systems, such as New Technology File System, work by overlaying a file system on top of block storage. As a result, many backup applications rely on changed block tracking. As the name implies, changed block tracking works by backing up newly created or recently modified storage blocks, as opposed to backing up data at the file level.
Benefits and challenges of block storage
Block storage enables precise control over the disk storage location. As a result, it is ideal for databases and other applications that require fine-grained control over storage operations. Some VM instances and high-performance computing environments can also benefit from using block storage.
On the negative side, block storage has limited support for metadata storage. It also has inefficiencies stemming from the way the file system interacts with storage media and the potential for file fragmentation.
What is file storage?
At its simplest, file storage refers to a system used to organize data into a collection of files and folders.
File storage and block storage have some overlap since file systems are often attached to underlying block storage. But some applications can use block storage directly without the need for file systems.
While some file storage environments are solely for local use, modern file storage systems are typically network-accessible. Windows environments, for example, enable network file storage access through the SMB protocol. Similarly, Linux environments use the NFS protocol. In contrast, a system or application that needs to access block storage directly, as opposed to using a file system, uses a lower-level protocol, such as iSCSI or Fibre Channel.
Benefits and challenges of file storage
File storage is familiar and easy to use. It is also versatile and compatible with a wide range of OSes and supports shared access to files.
Performance and lack of scalability are potential disadvantages. Performance bottlenecks tend to occur when reading or writing large files or in situations in which multiple users generate large numbers of IOPS. Additionally, file storage can be difficult to properly secure.
What is object storage?
On the surface, object storage appears to be similar to file storage since both are used to store files and folders. Object storage works differently, however.
Object storage is a nonhierarchical storage environment that stores files and folders as objects. These objects are referenced by a unique identifier, making it possible for an object storage system to scale to accommodate a nearly limitless number of objects. Each object is self-contained, meaning that a file, its metadata and the object storage identifier are all stored as a part of the object.
Benefits and challenges of object storage
The main advantage of using object storage is its scalability. Other advantages include rich metadata support and the ease of creating redundant data copies, which can help with data durability and data access across regions.
Users can't access data directly, but must access it through an API, typically using the HTTPS protocol. It can be difficult to migrate data from object storage to other storage types. In addition, accessing cloud-based object storage often comes with a cost.
Key differences between block vs. file vs. object storage
Users should analyze several differences, including access and performance, when deciding among the three storage types:
Storage access is quite different among the three types. Directly access block storage with iSCSI or Fibre Channel. Generally, access file storage through a file share, using protocols such as SMB or NFS. Access object storage programmatically through API calls.
The amount of metadata users can store is a key difference in comparing block vs. file vs. object storage. File storage and block storage have limited metadata storage capabilities. Object storage can store as much metadata as needed.
The storage types vary based on their performance characteristics. Block storage tends to have the lowest latency and least overhead. File storage is often based on block storage, but the file system and access protocols add additional overhead that weakens performance. Object storage can easily scale to meet performance demands, but latency can worsen it.
Data redundancy is also different. Block storage and file storage support redundancy through technologies such as RAID or erasure coding. Object storage includes built-in redundancy features and makes it easy for organizations to replicate their data to other regions.
It's best to align storage type selection to workload requirements.
Which one should I use?
It's best to align storage type selection to workload requirements.
Block storage is best for databases or other applications that require direct storage access. File storage is ideal for easy storage of unstructured data. Object storage is best for situations in which massive scalability is important.
Specifically, common use cases for block storage include the following:
Relational or transactional databases.
Time-series databases.
Mission- and business-critical applications requiring low latencies and response times.
General storage for virtualized and bare-metal servers.
Underlying storage media to file and object storage.
Hypervisor file systems, which also tend to use block storage because of its distribution across multiple volumes.
Geographically distributed global namespace edge filers using object storage as the centralized data lake.
Data lakes for large-scale analytics, such as data warehouses.
Editor's note: This article was originally published in 2023 and was updated in 2024 to improve the reader experience.
Brien Posey is a former 22-time Microsoft MVP and a commercial astronaut candidate. In his more than 30 years in IT, he has served as a lead network engineer for the U.S. Department of Defense and a network administrator for some of the largest insurance companies in America.
Marc Staimer is founder, president and CDS of Dragon Slayer Consulting in Beaverton, Ore. The 21-year-old consulting practice focuses on strategic planning, product development and market development.