Examining the state of PaaS in the year of ‘big data’
Either more vendors are offering ‘big data’ capabilities or they have creative marketing teams. Which PaaS provider’s big data cloud is the real deal?
This year has already been marked as the year of “big data” in the cloud, with major PaaS players, such as Amazon, Google, Heroku, IBM and Microsoft, getting a lot of publicity. But which providers actually offer the most complete Apache Hadoop implementations in the public cloud?
It’s becoming clear that Apache Hadoop, along with HDFS, MapReduce, Hive, Pig and other subcomponents, are gaining momentum for big data analytics as enterprises increasingly adopt Platform as a Service (PaaS) cloud models for enterprise data warehousing. To indicate Hadoop has matured and is ready for use in production analytics cloud environments, the Apache Foundation upgraded to Hadoop v1.0.
The capability to create highly scalable, pay-as-you-go Hadoop clusters in providers’ data centers for batch processing with hosted MapReduce processing allows enterprise IT departments to avoid capital expenses for on-premises servers that are used sporadically. As a result, Hadoop has become de rigueur for deep-pocketed PaaS providers -- Amazon, Google, IBM and Microsoft -- to package Hadoop, MapReduce or both as prebuilt services.
AWS Elastic MapReduce
Amazon Web Services (AWS) was first out of the gate with Elastic MapReduce (EMR) in April 2009. EMR handles Hadoop cluster provisioning, runs and terminates jobs and transfers data between Amazon EC2 and Amazon S3 (Simple Storage Service). EMR also offers Apache Hive, which is built on Hadoop for data warehousing services.
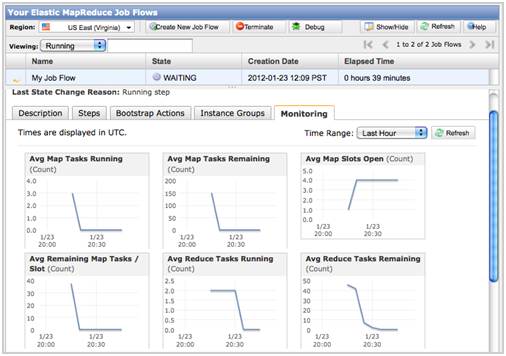 Figure 1 (Click to enlarge.)
Figure 1 (Click to enlarge.)Sample CloudWatch job workflow metrics for Amazon Web Services’ ElasticMapReduce feature. (Image courtesy of AWS.)
EMR is fault tolerant for slave failures; Amazon recommends running only the Task Instance Group on spot instances to take advantage of the lower cost while still maintaining availability. However, AWS didn’t add support for spot instances until August 2011.
Amazon applies surcharges of $0.015 per hour to $0.50 per hour for EMR to its rates for Small to Cluster Compute Eight Extra Large EC2 instances. According to AWS: Once you start a job flow, Amazon Elastic MapReduce handles Amazon EC2 instance provisioning, security settings, Hadoop configuration and set-up, log collection, health monitoring and other hardware-related complexities, such as automatically removing faulty instances from your running job flow. AWS recently announced free CloudWatch metrics for EMR instances (Figure 1).
Google AppEngine-MapReduce
According to Google developer Mike Aizatskyi, all Google teams use MapReduce, which it first introduced in 2004. Google released an AppEngine-MapReduce API as an “early experimental release of the MapReduce API” to support running Hadoop 0.20 programs on Google App Engine. The team later released low-level files API v1.4.3 in March 2011 to provide a file-like system for intermediate results for storage in Blobs and improved open-source User-Space Shuffler functionality (Figure 2).
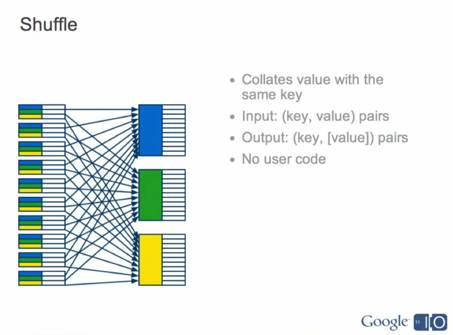 Figure 2 (Click to enlarge.)
Figure 2 (Click to enlarge.)Google AppEngine-MapReduce’s Shuffle process in an I/O 2012 session.
The Google AppEngine-MapReduce API orchestrates the Map, Shuffle and Reduce operations via a Google Pipeline API. The company decribed AppEngine-MapReduce’s current status in a video presentation for I/O 2012. However, Google hadn’t changed the “early experimental release” description as of Spring 2012. AppEngine-MapReduce is targeted at Java and Python coders, rather than big data scientists and analytics specialists. Shuffler is limited to approximately 100 MB data sets, which doesn’t qualify as big data. You can request access to Google’s BigShuffler for larger data sets.
Heroku Treasure Data Hadoop add-on
Heroku’s Treasure Data Hadoop add-on enables DevOps workers to use Hadoop and Hive to analyze hosted application logs and events, which is one of the primary functions for the technology. Other Heroku big data add-ons include Cloudant’s implementation of Apache CouchBase, MongoDB from MongoLab and MongoHQ, Redis To Go, Neo4j (public beta of a graph database for Java) and RESTful Metrics. AppHarbor, called by some “Heroku for .NET,” offers a similar add-on lineup with Cloudant, MongoLab, MongoHQ and Redis To Go, plus RavenHQ NoSQL database add-ins. Neither Heroku nor AppHarbor host general-purpose Hadoop implementations.
IBM Apache Hadoop in SmartCloud
IBM began offering Hadoop-based data analytics in the form of InfoSphere BigInsights Basic on IBM SmartCloud Enterprise in October 2011. BigInsights Basic, which can manage up to 10 TB of data, is also available as a free download for Linux systems; BigInsights Enterprise is a fee-based download. Both downloadable versions offer Apache Hadoop, HDFS and the MapReduce framework, as well as a complete set of Hadoop subprojects. The downloadable Enterprise edition includes an Eclipse-based plug-in for writing text-based analytics, spreadsheet-like data discovery and exploration tools as well as JDBC connectivity to Netezza and DB2. Both editions provide integrated installation and administration tools (Figure 3).
Figure 3 (Click to enlarge.)IBM’s platform and vision for big data. (Image courtesy of IBM.)
My Test-Driving IBM’s SmartCloud Enterprise Infrastructure as a Service: Part 1 and Part 2 tutorials describe the administrative features of a free SmartCloud Enterprise trial version offered in Spring 2011. It’s not clear from IBM’s technical publications what features from downloadable BigInsight versions are available in the public cloud. Their Cloud Computing: Community resources for IT professionals page lists only one BigInsights Basic 1.1: Hadoop Master and Data Nodes software image; an IBM representative confirmed the SmartCloud version doesn’t include MapReduce or other Hadoop subprojects. Available Hadoop tutorials for SmartCloud explain how to provision and test a three-node cluster on SmartCloud Enterprise. It appears IBM is missing elements critical for data analytics in its current BigInsights cloud version.
Microsoft Apache Hadoop on Windows Azure
Microsoft hired Hortonworks, a Yahoo! spinoff that specializes in Hadoop consulting, to help implement Apache Hadoop on Windows Azure, or Hadoop on Azure (HoA). HoA has been in an invitation-only community technical preview (CTP or private beta) stage since December 14, 2011.
Before joining the Hadoop bandwagon, Microsoft relied on Dryad, a graph database developed by Microsoft Research, and a High-Performance Computing add-in (LINQ to HPC) to handle big data analytics. The Hadoop on Azure CTP offers a choice of predefined Hadoop clusters ranging from Small (four computing nodes with 4 TB of storage) to Extra Large (32 nodes with 16 TB), simplifing MapReduce operations. There’s no charge to join the CTP for prerelease compute nodes or storage.
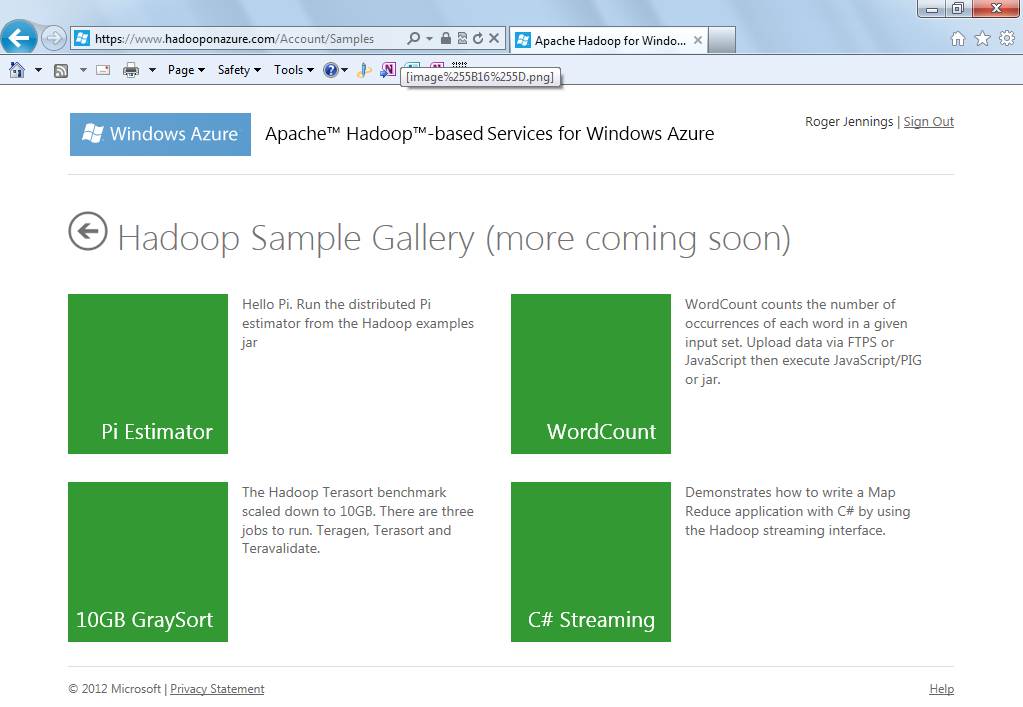 Figure 4 (Click to enlarge.)
Figure 4 (Click to enlarge.)Microsoft offers four sample Hadoop/MapReduce projects: Calculating the value of pi, performing Terasort and WordCount benchmarks, and demonstrating how to use C# to write a MapReduce program for streaming data.
Microsoft also provides new JavaScript libraries to make JavaScript a first-class programming language in Hadoop. This means JavaScript programmers can write MapReduce programs in JavaScript and run these jobs from Web browsers, which reduces the barrier to Hadoop/MapReduce entry. The CTP also includes a Hive add-in for Excel that lets users interact with data in Hadoop. Users can issue Hive queries from the add-in to analyze unstructured data from Hadoop in the familiar Excel user interface. The preview also includes a Hive ODBC Driver that integrates Hadoop with other Microsoft BI tools. In a recent blog post on Apache Hadoop Services for Windows Azure, I explain how to run the Terasort benchmark, one of four sample MapReduce jobs (Figure 4).
HoA is due for an upgrade in the “Spring Wave” of new and improved features scheduled for Windows Azure in mid-2012. The upgrade will enable the HoA team to admit more testers to the CTP and probably include a promised Apache Hadoop on Windows Server 2008 R2 for on-premises or private cloud and hybrid cloud implementations. Microsoft has aggressively reduced charges for Windows Azure compute instances and storage during late 2011 and early 2012; pricing for Hadoop on Azure’s release version probably will be competitive with Amazon Elastic MapReduce.
Big data will mean more than Hadoop and MapReduce
I agree with Forrester Research analyst James Kobielus, who blogged, “Within the big data cosmos, Hadoop/MapReduce will be a key development framework, but not the only one.” Microsoft also offers its Codename “Cloud Numerics” CTP for the .NET Framework, which allows DevOps teams to perform numerically intensive computations on large distributed data sets in Windows Azure.
Microsoft Research has posted source code for implementing Excel cloud data analysis in Windows Azure with its Project “Daytona” iterative MapReduce implementation. However, it appears open source Apache Hadoop and related subprojects will dominate cloud-hosted scenarios for the foreseeable future.
PaaS providers who offer the most automated Hadoop, MapReduce and Hive implementations will gain the greatest following of big data scientists and data analytics practitioners. Microsoft provisioning the Excel front end for business intelligence (BI) applications gives the company’s big data offerings a head start among the growing number of self-service BI users. Amazon and Microsoft currently provide the most complete and automated cloud-based Hadoop big data analytics services.
Roger Jennings is a data-oriented .NET developer and writer, a Windows Azure MVP, principal consultant of OakLeaf Systems and curator of the OakLeaf Systems blog. He's also the author of 30+ books on the Windows Azure Platform, Microsoft operating systems (Windows NT and 2000 Server), databases (SQL Azure, SQL Server and Access), .NET data access, Web services and InfoPath 2003. His books have more than 1.25 million English copies in print and have been translated into 20+ languages.







