
Sergey Nivens - Fotolia
Use Amazon EMR with Apache Airflow to simplify processes
Explore Amazon EMR, looking at use cases such as MapReduce and integration with Hadoop. Then, see how it works with Apache Airflow and learn how to get started.

Amazon EMR is an orchestration tool used to create and run an Apache Spark or Apache Hadoop big data cluster at a massive scale on AWS instances. IT teams that want to cut costs on those clusters can do so with another open source project -- Apache Airflow.
Airflow is a big data pipeline that defines and runs jobs. It works on many tools and services, such as Hadoop and Snowflake, a data warehousing service. It also works with AWS products, including Amazon EMR, the Amazon Redshift data warehouse, Amazon S3 object storage and Amazon S3 Glacier, a long-term data archive.
Amazon EMR clusters can rack up significant expenses, especially if the supporting instances are left running while idle. Airflow can start and take down those clusters, which helps control costs and surge capacity.
Airflow, and its companion product Genie -- a job orchestration engine developed by Netflix -- run jobs by bundling JAR files, Python code and configuration data into metadata, which creates a feedback loop to monitor for issues. This process is simpler than using the spark-submit script or Yarn queues in Hadoop, which offer a wide array of configuration options and require an understanding of elements like Yarn, Hadoop's resource manager.
Therefore, while IT teams don't need Airflow specifically -- all the tools it installs are open source -- it might reduce costs if the organization uses Airflow to install and tear down those applications. Otherwise, Amazon EMR users would have to worry about charges for the idle resources, as well as the costs of a big data engineer and the time and effort required to write and debug scripts.
Let's take a closer look at Amazon EMR and Airflow to see if they fit your organization's big data needs.
EMR components
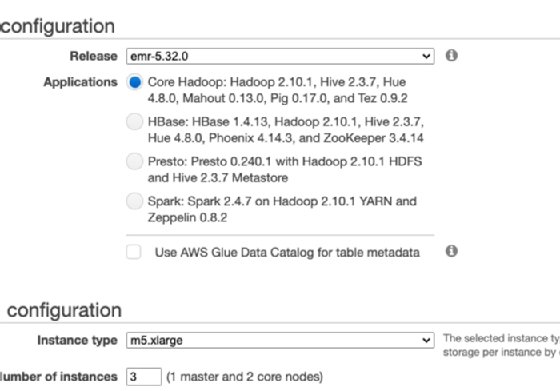
Figure 1 shows the configuration wizard for Amazon EMR. It installs some of the tools normally used with Spark and Hadoop, such as Yarn, Apache Pig, Apache Mahout (a machine learning tool), Apache Zeppelin and Jupyter.
What EMR does
The name EMR is an amalgamation of Elastic and MapReduce. Elastic refers to the elastic cluster hosted on Amazon EC2. Apache MapReduce is both a programming paradigm and a set of Java SDKs -- in particular, these two Java classes:
- org.apache.hadoop.mapreduce.Mapper
- org.apache.hadoop.mapreduce.Reducer
These run MapReduce operations and then optionally save the results to an Apache Hadoop Distributed File System.
Amazon EMR supports multiple big data frameworks, including newer options such as Apache Spark, which performs the same tasks as Hadoop but more efficiently.
MapReduce explained
Mapping, common to most programming languages, means to run some function or collection of data. Reduce means to count, sum or otherwise create a subset of that now reduced data.
To illustrate what this means, the first programming example for MapReduce that most engineers are introduced to is the WordCount program.
The WordCount program performs both mapping and reducing: The map step creates this tuple (wordX, 1), then counts the number of times a designated value appears. So, if a text contains wordX 10 times, then the map step (wordX,10) counts the occurrence of that word.
Figure 2 illustrates the process of the WordCount program. To begin, let's look at these three sentences:
- James hit the ball.
- James catches the ball.
- James lost the shoes.

The first step, map, lists the number of times a given word occurs, and the reduce step further simplifies that data until we are left with succinct tuples: (James, 3); (hit, 1); (ball, 2); and (the, 3).
The WordCount program is far from exciting, but it is useful. Hadoop and Spark run these operations on large and messy data sets, such as records from the SAP transactional inventory system. And because Hadoop and Spark can scale without limit, so can this WordCount approach -- meaning it can spread the load across servers. IT professionals can feed this new, reduced data set into a reporting system or a predictive model.
Other uses for EMR
MapReduce and Hadoop are the original use cases for EMR, but they aren't the only ones.
Java code, for example, is notoriously verbose. So, Apache Pig often accompanies EMR deployments, which enables IT pros to use SQL -- which is shorter and simpler to write -- to run MapReduce operations. Apache Hive, a data warehousing software, is similar.
EMR also can host Zeppelin and Jupyter notebooks. These are webpages in which IT teams write code; they support graphics and many programming languages. For example, admins can write Python code to run machine learning models against data stored in Hadoop or Spark.
Installing Airflow
Airflow is easy to install, but Amazon EMR requires more steps -- which is, itself, one reason to use Airflow. However, AWS makes Amazon EMR cluster creation easier the second time, as it saves a script that runs with the AWS command-line interface.
To install Airflow, source a Python environment -- for example source py372/bin/activate, if using virtualenv -- and then run this Python package:
export AIRFLOW_HOME=~/airflow pip install apache-airflow airflow db init
Next, create a user.
airflow users create \
--username admin \
--firstname walker \
--lastname walker \
--role Admin \
--email [email protected]
Then start the web server interface, using any available port.
airflow webserver --port 7777
Airflow code example
Shown below is an excerpt of an Airflow code example from the Airflow Git repository. It runs Python code on Spark to calculate the number Pi to 10 decimal places. This enables IT admins to package a Python program and run it on a Spark cluster.
In this snippet:
- EmrCreateJobFlowOperator creates the job;
- EmrStepSensor sets up monitoring via the webpage; and
- EmrTerminateJobFlowOperator removes the cluster.
cluster_creator = EmrCreateJobFlowOperator(
task_id='create_job_flow',
job_flow_overrides=JOB_FLOW_OVERRIDES,
aws_conn_id='aws_default',
emr_conn_id='emr_default',
)
step_adder = EmrAddStepsOperator(
task_id='add_steps',
job_flow_id="{{ task_instance.xcom_pull(task_ids='create_job_flow', key='return_value') }}",
aws_conn_id='aws_default',
steps=SPARK_STEPS,
)
step_checker = EmrStepSensor(
task_id='watch_step',
job_flow_id="{{ task_instance.xcom_pull('create_job_flow', key='return_value') }}",
step_id="{{ task_instance.xcom_pull(task_ids='add_steps', key='return_value')[0] }}",
aws_conn_id='aws_default',
)
cluster_remover = EmrTerminateJobFlowOperator(
task_id='remove_cluster',
job_flow_id="{{ task_instance.xcom_pull(task_ids='create_job_flow', key='return_value') }}",
aws_conn_id='aws_default',
)







