Top 32 big data interview questions to prep for in 2026
Get insight into the technical and strategic topics that hiring managers focus on with the questions that reveal how organizations assess modern big data skills.
Organizations worldwide are embracing big data. As they race to expand their big data capabilities and skills, the demand for qualified candidates continues to grow.
A world of opportunity awaits people pursuing a career path in this field. Careful analysis and synthesis of massive data sets provide invaluable insights and help organizations make informed, timely strategic business decisions. For example, big data analytics can reveal which products to develop based on customer behaviors, preferences and buying patterns. Analytics can also identify untapped opportunities, such as new territories or nontraditional market segments.
Today's most challenging -- yet rewarding and in-demand -- big data roles include data analysts, data scientists, database administrators, big data engineers and Hadoop specialists. Knowing what big data questions an interviewer is likely to ask -- and how to answer them -- is essential to success.
Whether you're a recent data science graduate or have experience in big data-related roles or other technology fields, this article highlights some of the most common big data interview questions prospective employers might ask.
How to prepare for a big data interview
Before diving into the specific big data interview questions and answers, candidates should first understand the basics of interview preparation.
- Create a tailored and compelling resume. Ideally, candidates tailor their resume and cover letter to the role. These documents demonstrate qualifications and experience, and show the prospective employer that you've researched the organization, including its history, leadership, culture and vision. Don't be shy about highlighting strong soft skills that support big data work.
- Remember, an interview is a two-way street. It's essential to provide correct and articulate answers to an interviewer's technical questions. But don't overlook the value of asking your own questions. Build a shortlist of questions before the appointment to ask at appropriate moments.
- Preparation is key. Invest time in researching the most commonly asked questions, then rehearse your answers before the interview. Be yourself! Look for ways to show your personality and give authentic and thoughtful answers. Monosyllabic, vague or bland answers won't do.
Top 35 big data interview questions and answers
Each of the following 35 big data interview questions includes an answer. Many of these focus on the widely-adopted Hadoop framework, given its ability to solve difficult big data challenges and deliver on core business requirements. Don't rely solely on these answers for interview preparation. Instead, use them as a starting point for digging deeper into each topic.
1. What is big data?
As basic as this question is, your answer demonstrates your understanding of this term and its full scope. A clear and concise answer explains that big data includes just about any type of data from many sources, including the following:
- Emails.
- Server logs.
- Social media.
- User files.
- Medical records.
- Temporary files.
- Databases.
- Machinery sensors.
- Automobiles.
- Industrial equipment.
- IoT devices.
Big data includes structured, semi-structured and unstructured data -- in any combination -- collected from a range of heterogeneous sources. Once collected, it requires careful management so it can be mined and transformed into actionable insights. When mining data, professionals often use advanced technologies, such as machine learning (ML), deep learning and predictive modeling to gain a deeper understanding of the data.
2. How can big data analytics benefit business?
There are numerous ways that big data benefits organizations. As long as they can extract value from data, gain actionable insights and put those insights to work, big data is useful. No interviewer expects a list of every possible outcome of a big data project, but be ready to cite several examples of where big data adds value, including the following:
- Improve customer service.
- Personalize marketing campaigns.
- Increase worker productivity.
- Improve daily operations and service delivery while reducing operational expenses.
- Improve products and services.
- Gain a competitive advantage in your industry with deeper insight into customers and markets to identify new revenue streams.
- Optimize supply chains and delivery routes.
Big data analytics also helps organizations within specific industries. For example, a utility company might use big data to better track and manage electrical grids. Governments might use it to improve emergency response, reduce crime and support smart city initiatives.
3. What are your experiences in big data?
If you have had previous roles in the big data field, outline your title, functions, responsibilities and career path. Include any specific challenges and how you met them. Highlight achievements related either to a specific big data project or to big data in general. Be sure to include any programming languages you've worked with, especially as they pertain to big data.
4. What are some of the challenges that come with a big data project?
No big data project is without its challenges, some of which might be specific to the project itself or to big data in general. Demonstrate awareness of those challenges, even if you haven't experienced them. Below are some of the most common challenges:
- Many organizations don't have the in-house skills they need to plan, deploy, manage and mine big data.
- Managing a big data environment is complex and time-consuming. Organizations must consider both the infrastructure and data, while ensuring that all the pieces fit together.
- Securing data and protecting personally identifiable information can get complicated due to the type, amount and diverse origins of data.
- Scaling infrastructure to meet performance and storage requirements can be complex and costly.
- Ensuring data quality and integrity can be difficult to achieve when working with large quantities of heterogeneous data.
- Analyzing large sets of heterogeneous data can be time-consuming and resource-intensive, and doesn't always lead to actionable insights or predictable outcomes.
- Ensuring all the right tools are in place and work together brings its own challenges.
- The cost of infrastructure, software and personnel quickly adds up and can be difficult to keep under control.
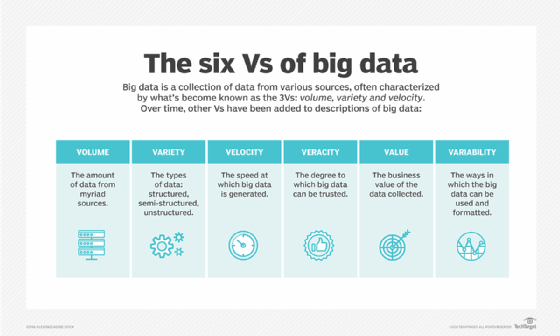
5. What are the five Vs of big data?
The following five Vs are a core characteristics of big data. During the interview, you should be able to discuss what they are and how they relate to big data:
- Volume. Organizations collect vast amounts of data from multiple sources.
- Variety. Big data comes in various forms -- structured, semi-structured and unstructured -- from sources such as social media, IoT devices, database tables and machinery, among others.
- Velocity. Data generation and collection is speeding up on all fronts in all industries.
- Veracity. Data's accuracy varies significantly from one source to another.
- Value. The data that organizations collect should have potential business value.
Sometimes, interviewers might ask for only four Vs. In this case, they're usually looking for the first four: volume, variety, velocity and veracity. If this happens in your interview, you can always mention that there is sometimes a fifth V: value. To impress your interviewer even further, mention a another V: variability, which refers to how the data can be used and formatted.
6. What are the key steps in deploying a big data platform?
There is no single formula for implementing a big data platform. However, most big data platforms follow these three basic steps:
- Data ingestion. Begin by collecting data from multiple sources, such as social media, log files or business documentation. Data ingestion can be ongoing to support real-time analytics or done at defined intervals to meet specific business requirements.
- Data storage. After extracting the data, store it in a database. Common databases include the Hadoop Distributed File System (HDFS), Apache HBase or another NoSQL database.
- Data processing. The final step is to prepare the data for analysis. Implement one or more frameworks that have the capacity handle massive data sets, such as Hadoop, Apache Spark, Flink, Pig or MapReduce, to name a few.
7. What is Hadoop, and what are its main components?
Hadoop is an open source distributed processing framework for handling large data sets across computer clusters. It can scale up to thousands of machines, each supporting local computation and storage. Hadoop processes large volumes of diverse data types and distributes workloads across multiple nodes, making it a good fit for big data initiatives.
The Hadoop platform includes the following four primary modules, sometimes referred to as components.
- Hadoop Common. A collection of utilities that support the other modules.
- HDFS. This key component serves as the platform's primary data storage system, providing high-throughput access to application data.
- Hadoop YARN. This resource management framework schedules jobs and allocates system resources across the Hadoop ecosystem.
- Hadoop MapReduce. A YARN-based system for parallel processing large data sets.
8. Why is Hadoop so popular in big data analytics?
Hadoop is effective at handling large amounts of structured, unstructured and semi-structured data. Analyzing unstructured data isn't easy, but Hadoop's storage, processing and data collection capabilities make it more manageable. Hadoop is open source and runs on commodity hardware, making it less costly than systems relying on proprietary hardware and software.
One of Hadoop's biggest selling points is that it scales horizontally to support thousands of hardware nodes. HDFS facilitates rapid data access across all nodes in a cluster, and its inherent fault tolerance enables applications to run even if individual nodes fail. Hadoop also stores raw data without imposing any schemas, so each team can decide how to process and filter the data based on its specific requirements.
9. Can you define these terms in the context of Hadoop?
As a follow-on from the previous question, you should be able to define the following four terms, specifically in the context of Hadoop.
- Open source. Hadoop is an open-source platform, so users can access and modify the source code to meet their specific needs. Its wide implementation has created a large and active user community that helps resolve issues and improves the product. Hadoop is licensed under Apache License 2.0.
- Scalability. Hadoop can scale out or up to support thousands of hardware nodes using only commodity hardware. Organizations can begin with smaller systems and add more nodes to their clusters, as well as add resources to individual nodes. This makes it possible to ingest, store and process vast amounts of data typical in big data initiatives.
- Data recovery. Hadoop replication provides built-in fault tolerance that protects against system failure. Even if a node fails, applications keep running while avoiding data loss. HDFS stores files in blocks, which are replicated to ensure fault tolerance, helping improve reliability and performance. Administrators can configure block sizes and replication factors on a per-file basis.
- Data locality. Hadoop moves the computation close to where data resides, rather than moving large data sets to computation. This reduces network congestion and improves overall throughput.
10. What are some vendor-specific distributions of Hadoop?
Several vendors now offer Hadoop-based products. Some of the notable products include the following:
- Cloudera.
- MapR.
- Amazon EMR (Elastic MapReduce).
- Microsoft Azure HDInsight.
- IBM InfoSphere Information Server.
11. What are some of the main configuration files used in Hadoop?
The Hadoop platform provides multiple configuration files for controlling cluster settings, including the following:
- hadoop-env.sh. Set site-specific environmental variables to control Hadoop scripts in the bin directory.
- yarn-env.sh. Set site-specific environmental variables to control YARN scripts in the bin directory.
- mapred-site.xml. Configuration settings specific to MapReduce, such as the MapReduce.framework.name setting.
- core-site.xml. Core configuration settings, such as the I/O configurations common to HDFS and MapReduce.
- yarn-site.xml. Configuration settings specific to YARN's ResourceManager and NodeManager.
- hdfs-site.xml. Configuration settings specific to HDFS, such as the file path where the NameNode stores the namespace and transaction logs.

12. What is HDFS, and what are its main components?
HDFS is a distributed file system serving as Hadoop's default storage environment. It runs on low-cost commodity hardware while providing high fault tolerance. HDFS stores various data types in a distributed environment and offers high throughput to applications with large data sets. HDFS is deployed in a primary/secondary architecture. Each cluster supports two primary node types:
- NameNode. A single primary node manages the file system namespace, regulates client access to files and processes metadata information for all data blocks in HDFS.
- DataNode. A secondary node that manages the storage attached to each node in the cluster. A cluster typically contains many DataNode instances, but there is usually only one DataNode per physical node. Each DataNode serves read/write requests from the file system's clients.
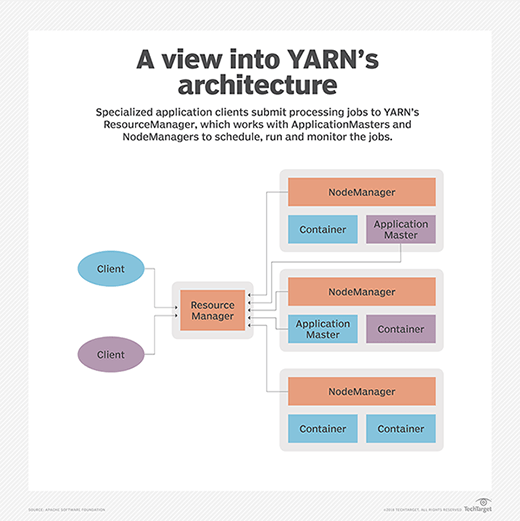
13. What is Hadoop YARN, and what are its main components?
Hadoop YARN manages resources and provides an execution environment for required processes while allocating resources for applications running in the cluster. It also schedules and monitors jobs. YARN decouples resource management and scheduling from MapReduce's data processing component.
YARN separates resource management and job scheduling into the following daemons:
- ResourceManager. This daemon arbitrates resources for the cluster's applications. It includes two main components: Scheduler and ApplicationsManager. The Scheduler allocates resources to running applications. The ApplicationsManager handles tasks, including accepting job submissions, negotiating the execution of the application-specific ApplicationMaster and providing a service for restarting the ApplicationMaster container on failure.
- NodeManager. This daemon launches and manages containers on a node and runs specified tasks. NodeManager also runs services that determine node health, such as disk checks. Moreover, NodeManager executes user-specified tasks.
14. What are Hadoop's primary operational modes?
Hadoop supports three primary operational modes.
- Standalone. Also known as Local mode, Standalone mode is the default mode. It runs as a single Java process on a single node using the local file system and requires no configuration changes. Standalone mode is primarily used for debugging.
- Pseudo-distributed. Also known as a single-node cluster, Pseudo-distributed mode runs on a single machine, though each Hadoop daemon runs in a separate Java process. This mode uses HDFS rather than the local file system and requires configuration changes. It is often used for debugging and testing.
- Fully distributed. This is the full production mode, with all daemons running on separate nodes in a primary/secondary configuration. Data is distributed across the cluster, which ranges from a few to thousands of nodes. This mode requires configuration changes but offers the scalability, reliability and fault tolerance expected of a production system.
15. What are three common input formats in Hadoop?
Hadoop supports multiple input formats, which determine the shape of the data when collected. While you should maintain a good understanding of all input formats, the following are three of the most common:
- Text. This is the default input format. Each line within a file is treated as a separate record. The records are saved as key/value pairs, with the line of text treated as the value.
- Key-value text. This input format is similar to the text format, breaking each line into separate records. Unlike the text format -- which treats the entire line as the value -- the key-value text format breaks the line itself into a key and a value, using the tab character as a separator.
- Sequence file. This format reads binary files that store sequences of user-defined key-value pairs as individual records.
16. What makes an HDFS environment fault-tolerant?
HDFS replicates data across different DataNodes by breaking files down into blocks that are distributed across nodes in the cluster. Each block is also replicated to other nodes. If one node fails, others take over, giving applications access to data through replicated copies.
17. What is rack awareness in Hadoop clusters?
Rack awareness is one of Hadoop's mechanisms that helps optimize data access when processing client read/write requests. When a request comes in, the NameNode identifies and selects the nearest DataNodes, preferably those on the same or nearby rack. Rack awareness improves performance and reliability while reducing network traffic, and plays a role in fault tolerance. For example, the NameNode distributes data block replicas across separate racks to ensure continued access if a network switch fails or a rack becomes unavailable.
18. How does Hadoop protect data against unauthorized access?
Hadoop uses the Kerberos network authentication protocol to protect data from unauthorized access. Kerberos uses secret-key cryptography to provide strong authentication for client-server applications. A client must undergo the following three basic steps -- each involves message exchanges with the server -- to prove its identity to that server:
- Authentication. The client sends an authentication request to the Kerberos authentication server. The server verifies the client and sends a ticket granting ticket (TGT) and a session key.
- Authorization. Once authenticated, the client requests a service ticket from the ticket granting server (TGS). It includes its TGT with the request. If the TGS authenticates the client, it sends the necessary service ticket and credentials to access the resource.
- Service request. The client sends its request to the Hadoop resource it wants to access. The request must include the service ticket issued by the TGS.
19. What is speculative execution in Hadoop?
Speculative execution is an optimization technique Hadoop uses when it detects that a DataNode is executing a task too slowly. There can be many reasons for a slowdown, making it difficult to determine the cause. Rather than trying to diagnose and fix the problem, Hadoop identifies the task in question and launches an equivalent task -- the speculative task -- as a backup. If the original task completes before the speculative task, Hadoop kills the speculative task.
20. What is the purpose of the JPS command in Hadoop?
JPS, short for Java Virtual Machine Process Status, is a command that checks the status of Hadoop daemons. Specifically, it checks NameNode, DataNode, ResourceManager and NodeManager. Administrators can use the command to verify whether the daemons are up and running. The tool returns the process ID and process name of each Java Virtual Machine running on the target system.
21. What commands can you use to start and stop all the Hadoop daemons at one time?
You can use the following command to start all the Hadoop daemons:
./sbin/start-all.sh
You can use the following command to stop all the Hadoop daemons:
./sbin/stop-all.sh
22. What is an edge node in Hadoop?
An edge node is a computer acting as an end-user portal for communicating with other nodes in a cluster. It's an interface between the Hadoop cluster and an outside network. For this reason, it is also referred to as a gateway node or edge communication node. Edge nodes are often used to run administration tools or client applications. They don't typically run any Hadoop services.
23. What are the key differences between NFS and HDFS?
Network File System (NFS) is a widely implemented distributed file system protocol used extensively in network-attached storage (NAS) systems. It is one of the oldest distributed file storage systems and is well-suited to smaller data sets. NAS makes data available over a network and accessible like files on a local machine.
HDFS is a more recent technology designed to handle big data workloads. It provides high throughput and capacity far beyond an NFS-based system's capabilities. HDFS also offers integrated data protection, safeguarding against node failures.
NFS is typically implemented on single systems, which lack inherent fault tolerance, unlike HDFS. However, NFS-based systems have less complicated deployment and maintenance than HDFS-based systems.
24. What is commodity hardware?
Commodity hardware is a device or component that is widely available, relatively inexpensive and typically interchangeable with other components. Commodity hardware is sometimes known as off-the-shelf hardware because it's readily available and easy to acquire.
Organizations often choose commodity hardware over proprietary hardware because it's cheaper, simpler and faster to acquire. It's also easier to replace individual components when hardware fails. Commodity hardware includes servers, storage systems, network equipment and other components.
25. What is MapReduce?
MapReduce is a software framework in Hadoop for processing large data sets across a cluster of computers, in which each node has its own storage. MapReduce processes data in parallel on these nodes, distributing input data and collating the results. In this way, Hadoop runs jobs split across a massive number of servers.
MapReduce also provides its own level of fault tolerance, as each node periodically reports its status to a primary node. Additionally, it offers native support for writing Java applications, although you can also write MapReduce applications in other programming languages.
26. What are the two main phases of a MapReduce operation?
A MapReduce operation can be divided into the following two primary phases:
- Map phase. MapReduce processes input data, splits it into chunks and maps them in preparation for analysis. Then, it runs these processes in parallel.
- Reduce phase. MapReduce processes the mapped chunks, aggregating the data based on the defined logic. The output of these phases is then written to HDFS.
Sometimes, this operation is further divided. For example, the Reduce phase might be split into the Shuffle phase and the Reduce phase. In some cases, you might see an optional Combiner phase, which optimizes operations.
27. What is feature selection in big data?
Feature selection is the process of extracting specific information from a data set, reducing the amount of data that must be analyzed while improving data quality. Feature selection lets data scientists refine the input variables they use to model and analyze data. This leads to more accurate results while reducing computational overhead.
Data scientists use sophisticated algorithms for feature selection, which usually fall into the following categories:
- Filter methods. A subset of input variables is selected during a preprocessing stage by ranking the data based on factors such as importance and relevance.
- Wrapper methods. This resource-intensive operation uses ML and predictive analytics to determine which input variables to keep. This approach usually provides better results than filter methods.
- Embedded methods. This method combines attributes of the filter and wrapper methods. It uses fewer computational resources than wrapper methods, while providing better results than filter methods. However, embedded methods aren't always as effective as wrapper methods.
28. What is an "outlier" in the context of big data?
An outlier is a data point abnormally distant from others in a random sample group. The presence of outliers can mislead the ML process, resulting in inaccurate models or substandard outcomes. In fact, an outlier can potentially bias an entire result set. That said, outliers can sometimes contain valuable information.
29. What are two common techniques for detecting outliers?
Analysts often use the following two techniques to detect outliers:
- Extreme value analysis. This is the most basic form of outlier detection, limited to one-dimensional data. Extreme value analysis determines a data distribution's statistical details. The Altman Z-score is a good example of extreme value analysis.
- Probabilistic and statistical models. The models determine the unlikely instances from a probabilistic model of data. Data points with a low membership probability are marked as outliers. However, these models assume data adheres to specific distributions. A common example of this type of outlier detection is the Bayesian probabilistic model.
These are only two core methods for detecting outliers. Other approaches include linear regression models, information theoretic models and high-dimensional outlier detection methods.
30. What is the FSCK command used for?
File system consistency check (FSCK) is an HDFS filesystem checking utility that generates a summary report of the file system's status. However, the report merely identifies the presence of errors; it doesn't correct them. You can execute the FSCK command against an entire system or subset of files.

31. Are you open to gaining additional learning and qualifications that could help you advance your career with us?
Here's your chance to demonstrate your enthusiasm and career ambitions. Your answer will depend on your current academic qualifications and certifications, as well as your personal circumstances, which include family responsibilities and financial considerations. Therefore, give a forthright and honest response.
Bear in mind that many courses and learning modules are readily available online. Moreover, analytics vendors have established training courses aimed at those seeking to upskill themselves in this domain. You can also inquire about the company's policy on mentoring and coaching.
32. Do you have any questions for us?
A good rule of thumb is to go to interviews with a few prepared questions. Depending on how the conversation unfolds during the interview, you might choose not to ask them. You might have already received an answer, or the discussion may have sparked more pertinent queries, so you can put your original questions aside.
Be aware of your timing when asking your questions. Take your cue from the interviewer. Depending on the circumstances, asking questions during the interview is acceptable, although it's generally more common to hold them until the end. That said, you should never hesitate to ask for clarification on a question the interviewer asks.
A final word on big data interview questions
Remember, the process doesn't end after an interview is over. After the session, send a note of thanks to the interviewer(s) or your point(s) of contact. Follow this up with a message if you haven't received any feedback within a few days.
The big data world is constantly expanding. If you're serious and passionate about the topic -- and prepared to work hard -- the sky's the limit.
Editor's note: This article was updated in February 2026.
Robert Sheldon is a freelance technology writer. He has written numerous books, articles and training materials on a wide range of topics, including big data, generative AI, 5D memory crystals, the dark web and the 11th dimension.
Elizabeth Davies is a technology writer and content development professional with more than two decades of experience in consulting, strategizing and collaborating with C-suite and other senior information and communication technology experts.






