
What is data masking?
Data masking is a security technique that modifies sensitive data in a data set so it can be used safely in a non-production environment. Masking allows software developers, software testers, software application trainers and data analysts to work with an organization's data without putting confidential information at risk or violating compliance regulations designed to protect personally identifiable information (PII).
Data masking is most often used to protect structured data in software development environments and in situations where data sets that contain confidential information need to be shared between systems or with third-party partners. To be used effectively, masked data should be able to pass validation checks and maintain consistent relationships across tables, but not be able to be reverse-engineered.
Data masking uses data obfuscation techniques like scrambling and substitution to change confidential data values, while still preserving data types and file formats. This allows the masked data to behave just like the original data in non-production environments but prevents it from being used for identity theft, fraud or other malicious reasons.
Masked data is considered to be a pseudonymized data de-identification technique because the altered data does not replace the true data values. Under compliance regulations in many parts of the world, pseudonymized data remains within the scope of privacy laws. This means that masked data is still subject to compliance requirements and organizations must still apply access controls, maintain audit trails and report a breach if masked data is compromised.
This article is part of
What is data security? The ultimate guide
How does data masking work?
The process of data masking typically involves discovering and classifying sensitive data fields in a structured data set and then determining how to alter the data while still preserving its format, data type and relationships.
To facilitate the process, organizations often rely on data discovery and data classification tools that use pattern matching, regular expressions or natural language processing (NLP) to locate sensitive values like credit card numbers or health insurance claim codes. Once identified, those values can be altered in a way that disguises the original content but keeps the document or file usable in non-production environments.
Masked values can be created manually, but to handle large data sets, organizations usually rely on curated pools of realistic data or format-preserving generators. After masking, the data set is checked to make sure it still works correctly, and the process is monitored closely to ensure it doesn't create new risks.
Types of data masking
Data masking can be carried out statically, dynamically or on-the-fly. Static masking is completed in batches ahead of time, dynamic masking masks query results in real time and on-the-fly masking alters data as it moves between environments.
- Static masking involves making a copy of the original data and replacing sensitive values in the copy with realistic-looking stand-ins. Static masking allows sensitive data to be used safely in development, testing, training or analytics environments because it retains the original data structure but no longer contains values that can be exploited.
- Dynamic data masking leaves the original data unchanged in the production system and applies masking rules in real time whenever the data is queried. Dynamic masking can be permission-based and allow some users to see the original values in query results while others see realistic-looking stand-in values.
- On-the-fly data masking modifies sensitive data in motion. This approach is especially useful when provisioning test databases in the cloud because it ensures the destination environment -- which is usually a nonproduction system -- only receives masked values and never has access to the original data.
| Different types of data masking |
|||
| Type of masking |
Use case |
Advantages |
Limitations |
| Static data masking (SDM) |
Creating safe, permanent copies of production data for development, testing or training. |
Provides realistic data sets for non-production use; safe to share across teams. |
Requires making and maintaining copies; not suitable for live systems. |
| Dynamic data masking (DDM) |
Producing different views of the same live production data. |
Protects sensitive fields at query time; supports permission-based access; no changes to production data. |
Can affect performance; can be complex to manage at scale. |
| On-the-fly data masking (OFM) |
Transferring data between environments. |
Ensures sensitive data never leaves the source unmasked; reduces risk for data in transit. |
Requires integration with data transfer processes. |
Data masking techniques
A variety of data management techniques can be used to disguise sensitive data while still keeping data sets functional in non-production environments. Popular methods include the following:
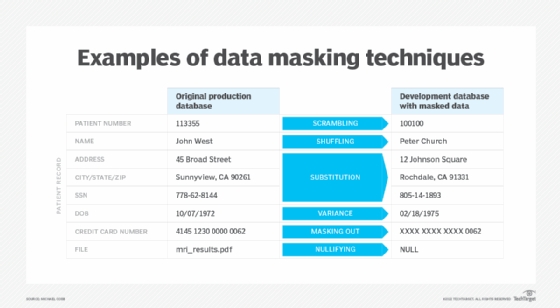
Scrambling
Scrambling is a masking technique that obfuscates data by reordering alphanumeric characters. For example, customer ID number 3A429 in a production database might be replaced with 293A4 in a scrambled test environment. Scrambling is easy to implement, but because scrambled data can still reveal patterns that could be reverse-engineered, many organizations use it alongside stronger masking techniques such as substitution.
Substitution
This masking technique replaces some (or all) sensitive data values with similar values that have the same characteristics. For example, valid credit card numbers might be replaced with different numbers that could still pass the card provider's validation rules. Substitution is one of the strongest masking techniques because it produces realistic-looking data that cannot be linked back to the original values, while still preserving the integrity, usability and format of the original data set.
Shuffling
Shuffling protects structured information by rearranging the order in which values appear in a database column. This approach preserves data formats and keeps data sets functional for testing or analysis, but it weakens the connection between individual records and their original values. Shuffling is considered a lightweight masking technique, so it is often used in combination with other masking techniques, such as substitution and scrambling.
Nulling
Nulling is a data masking technique that allows sensitive fields in a relational database to be replaced with a null value (or sometimes a zero-length blank). For example, a customer record's Social Security number field might be set to null so that no value appears at all. This approach can only work if the database management system recognizes null as a placeholder. Nulling is often considered to be one of the weakest forms of data masking because it removes values entirely rather than replacing them with realistic stand-ins, and this can limit the usefulness of the data in certain testing or analytics environments.
Variance
Variances are often used to mask financial values and transactional values. In this approach, an algorithm is used to modify each number by a random percentage of its real value. For instance, a column of sales figures could have a variance of plus or minus 5% applied to it. Variances are often used to protect sensitive numerical data values while still maintaining the overall range, distribution and statistical usefulness of the data set.
Data aging
Data aging is a specific type of variance that involves shifting date values forward or backward in time while keeping the format and logical sequence intact. For example, a customer's date of birth 07/14/1985 might be aged to 09/02/1984, or a transaction timestamp might be moved ahead by 90 days. Data aging is useful when data sets include sensitive information that is tied to actual events or timelines. By aging the dates, organizations can protect data privacy while still allowing developers, testers, or analysts to work with realistic time-based data.
Deterministic masking
Deterministic masking is a type of pseudonymized data masking in which the same input value is always replaced with the same masked output value, every time it appears in the data set. This approach is often used in non-production environments that need to preserve relationships but don't need to know the true underlying values. Because it's possible to reverse engineer deterministic replacements, however, this type of masking is usually enhanced by strong substitution rules and typically uses large replacement pools designed to reduce predictability.
Masking out
Masking out hides part of a sensitive value with a placeholder. This approach to data masking is commonly used for PCI DSS compliance.
Why is data masking important?
Masking plays an important role in risk management because it transforms sensitive data into a safe form that maintains functionality but removes any value the data might have to attackers. Even if a masked data set is stolen or leaked, it cannot be used for fraud, identity theft, or other malicious purposes.
Masking also plays an important role in reducing compliance risks. Various data protection laws and standards require organizations to safeguard personally identifiable information and protected health information (PHI) and keep it confidential. Compliance with these frameworks is not optional; failure to comply can result in financial penalties and reputational damage.
- California Consumer Privacy Act. CCPA gives consumers rights over how their personal information is collected, sold, and disclosed. Masking supports compliance by reducing the risk that personal information is exposed when data is used for development, testing, training or analytics.
- General Data Protection Regulation. GDPR applies to all organizations that process personal data in the European Union or European Economic Area. Masking supports GDPR compliance by reducing the risk that personal data is exposed when it is used outside production systems.
- Health Insurance Portability and Accountability Act. HIPAA requires covered entities and their business associates in the U.S. to implement safeguards that preserve personal health information confidentiality, integrity and availability. Masking helps organizations use realistic health data sets for research, testing or training while still protecting patient privacy.
- Payment Card Industry Data Security Standard. PCI DSS is a global standard created by the PCI Security Standards Council to protect cardholder data. PCI DSS requires merchants and service providers to limit access to sensitive payment information, including the primary account number (PAN), expiration date, and card validation value (CVV).
What types of data should be masked?
Masking is used to obfuscate data values that could be used to determine a person's identity, finances or health if leaked. Common types of data that are often masked include the following:
- Personally identifiable information. This includes names, addresses, Social Security numbers, license numbers, passport numbers, and other data types that can be used to specifically identify an individual.
- Protected health information. This includes medical records, diagnoses, test results, treatment outcomes and other health data that can be traced back to a specific individual.
- Financial data. In finance, developers, analysts, and third-party vendors often need access to realistic data for testing or modeling. Masking allows institutions to use functional data sets while reducing the risk of regulatory violations and data breaches.
- Payment card information. PCI DSS requires merchants and service providers to protect cardholder data and ensure that primary account numbers are rendered unreadable anywhere they're stored, unless there is a strict business need for the full value.
- Internal corporate data. Masking is often used to protect sensitive data in vendor and employee records. For example, masking allows HR systems to be tested or integrated with other tools safely while protecting employees' privacy.
- Intellectual property. Sensitive data that is included in trade secrets, inventions, patents or other types of intellectual property documents can be masked to prevent unnecessary exposure during testing, collaboration or data sharing. Many organizations use encryption and role-based access controls (RBAC) in addition to masking to protect their IP.
Data masking challenges
Data masking is not a simple, one-step process because sensitive fields need to be transformed to prevent re-identification while still preserving the structure, data types and statistical properties of the original data set. If this balance is not maintained, the masked data won't be useful in non-production environments.
In fact, maintaining referential integrity for masked data can be a major challenge. Masked values need to remain consistent across related tables and systems so that primary key and foreign key relationships are preserved. While this might sound straightforward, most databases are normalized for performance, and masking sensitive data stored in a distributed database can quickly become a complicated process.
Data governance is another challenge because masked data still needs to comply with business rules and validation requirements. For example, account numbers must retain their correct length and credit card numbers must pass a Luhn check. Without this, applications in non-production environments might crash during testing, and analytics might yield distorted results.
To overcome these challenges, database administrators (DBAs) need to conduct a detailed review of the data that needs to be masked and include stakeholders who will be using the masked data in the review. This will help ensure that appropriate masking techniques are used for each use case and that data being masked actually maintains the characteristics of the original data.
Data masking best practices
Data masking allows organizations to comply with privacy regulations and still use data sets that contain sensitive data in non-production environments. To be used effectively, masking should follow these best practices:
- Identify what data should be masked. Enterprise data is often spread across multiple databases, tables and storage locations. To ensure sensitive information is consistently protected, the first thing organizations need to do is locate and identify which data elements should be masked.
- Consider masking unstructured data. Images, PDFs and text-based files that contain sensitive information must also be protected. Organizations should consider using optical character recognition to locate sensitive data in data lakes and other unstructured storage repositories.
- Include data masking in policies. Best practices for data masking should be included in an organization's data management and security policies.
- Adopt the principle of least privilege. Access to masked data should comply with an organization's security policies. A recommended best practice is to apply the principle of least privilege, i.e., POLP.
- Test the usefulness of masked data. It's important to assess the outputs of data masking techniques to verify that they are comparable with those made from the original data.
- Maintain referential integrity. Masked values should remain consistent across related systems and tables. This will ensure that data joins, queries and analytics will work properly, even though the original values have been altered.
Data masking vs. other obfuscation techniques
Masking prevents sensitive information from being exposed in contexts where real data is not needed. Other obfuscation techniques -- like data anonymization, encryption or the use of synthetic data -- serve related but different purposes.
For example, anonymization irreversibly removes identifiers so data can never be linked back to a specific individual. Once anonymized, the data set is no longer considered personal data under frameworks such as GDPR because there is no realistic way to re-identify individuals. The tradeoff, however, is that anonymized data often loses some of its utility for detailed analysis or testing because the links to real-world individuals are permanently broken.
Encryption secures data at rest or in transit by making it unreadable without the right encryption key. While encryption can protect sensitive information from unauthorized access, it does not provide realistic stand-ins for testing or training environments like masking does.
Synthetic data is created from scratch by algorithms or generative AI models. Because synthetic data is not directly tied to real records, it is often considered a safe alternative to masking.
Data masking use cases
Data masking is widely used across a wide variety of industries to drive innovation and improve services without putting sensitive information at risk. In banking and finance, for example, masking can support the development of new fraud detection systems while ensuring that regulated data such as account numbers and payment details remain protected. Healthcare, retail and government agencies also rely on masking to balance functionality with regulatory compliance.
Currently, the main drivers behind data masking revolve around security and privacy regulations. By replacing sensitive values with realistic-looking stand-ins, masking allows businesses to work with data sets that contain sensitive information while reducing the likelihood of exposing confidential information.
Masking can also help reduce the impact of a data breach. If an attacker exfiltrates a masked copy, and the masking was done effectively, sensitive information cannot be associated with specific individuals.
It's also worth noting that many tasks in non-production environments require partial access to records rather than full visibility. Dynamic masking can help ensure employees are able to do their jobs without unnecessary access to sensitive data. To streamline masking and reduce manual effort, masking tools can be integrated with extract, transform, load and DevOps pipelines
Masking tools
There are several well-known tools that can help make the data masking process much faster, easier and more reliable. Here are some popular options that can make data discovery, classification, rule definition, masking execution and mask auditing easier and faster:
- Informatica. Known for offering strong discovery, static/ dynamic masking and its ability to be integrated with other data management platforms.
- Delphix. Known for facilitating automated masking in non-production environments.
- IBM InfoSphere Optim Data Privacy. Good for enterprises that have complex masking needs. Includes features for data discovery, classification, transformation and compliance reporting.
- Microsoft / Azure SQL Server / Azure Dynamic Data Masking. Useful especially in Microsoft/Cloud-heavy environments; offers built-in dynamic masking features.
- Oracle Data Masking and Subsetting. Many options also support masking in non-Oracle databases.
- K2View. Provides masking and synthetic data generation in enterprise settings, with attention to maintaining referential integrity and scaling across systems.
To understand the pros and cons of data masking, it can be helpful to learn more about data governance tools and how they help organizations strike a balance between data utility and data protection.







