What is a distributed database?
A distributed database is a database that consists of two or more files located in different sites on the same or different networks. Processing is distributed among multiple database nodes stored in multiple physical locations.
In effect, the data in a distributed database is stored across multiple computers (physical or virtual machines) so a version of the database runs on multiple locations. Each of these locations, which can be geographically separated, is known as a node or instance. To users, however, the database looks like one single database.
Distributed databases are scalable, highly available, deliver high performance, and can accommodate different data types. Data replication and fragmentation are two ways in which data is stored in multiple sites to create a distributed database and ensure its high availability.
Uses of distributed databases
Distributed databases are suitable for scenarios and applications that require the following:
- High performance.
- Data replication and redundancy.
- Load balancing.
- Resilience.
- Fault tolerance.
- Data backup.
- Continuous database monitoring and failure detection.
Distributed databases are ideal for applications that require high data availability and fault tolerance, such as e-commerce and corporate management information systems, financial transactions, online games, multimedia applications and more.
Distributed databases are particularly useful when users must access data remotely or from a variety of mobile devices. Applications that use large or diverse data sets can also benefit from distributed databases. These might include healthcare, military, and internet of things (IoT) applications.
How does a distributed database work?
In a distributed database, data is placed on multiple servers or computers consisting of individual nodes. The nodes might be physical systems or virtual machines, and they might be geographically separated from each other without sharing physical components. Each of these nodes stores a copy of the data set and runs on database management system (DBMS) software that provides centralized control and consistency across the distributed environment and manages tasks like data partitioning, replication, and updates. To ensure consistency between the replicas or copies of the data between multiple nodes, those nodes use an algorithm, such as the Raft consensus algorithm, to achieve consensus. This means that the replicas agree beforehand that the data being entered is correct before a write is committed.
Once the nodes are set up, they can receive read/write requests. Due to the consensus mechanism, they avoid consistency problems. The nodes communicate with each other using one of three communication methods:
- Unicast. This is when one node sends a message only to one other node.
- Broadcast. This happens when a node sends a message to all other nodes in the distributed database.
- Multicast. Here, a message is sent only to some nodes in the distributed database.
A distributed database improves data availability and sharing by spreading or "replicating" data across multiple locations. It supports distributed transactions with ACID (atomicity, consistency, isolation, durability) properties involving more than one node and also allows for horizontal scaling.
Data partitioning is essential for proper data distribution and optimal user access to that data. The database can either partition data horizontally or vertically. In horizontal data partitioning, the data tables are split into rows across multiple nodes. In contrast, vertical data partitioning involves splitting the tables into columns across all the nodes in the database. Either way, the resulting data sets are known as shards.
Features of distributed databases
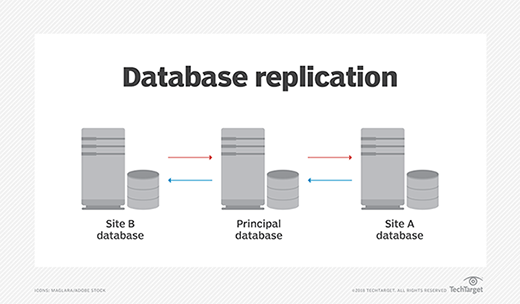
When in a collection, distributed databases are logically interrelated and often represent a single logical database. Data is physically stored across multiple sites and managed independently by the various nodes. This approach -- placing the same data on multiple servers or computers -- is called replication. This feature increases data availability and minimizes the potential for data loss.
Distributed databases also include these features:
- Distributed query processing. The presence of multiple nodes and replicated data supports distributed and faster query processing.
- Distributed transaction management. A single transaction can involve more than one node, with each site managing its transactions with other sites.
- Hardware- and OS-independent. Heterogeneous distributed databases use different machines or sites that use different hardware and operating systems (OSes). They might also contain different data schemas. While these differences can increase database complexity, they offer greater flexibility in the types of data that can be stored while yielding better performance and scalability.
- Support for ACID transactions. In distributed databases, all transactions are treated as single units (atomicity); data consistency is maintained by enforcing predefined rules and data constraints (consistency); transactions are isolated from each other to prevent data conflicts and maintain data integrity (isolation); and data is preserved even if a system fails (durability).
- Multiple communication means. Nodes can communicate with each other using unicast, broadcast or multicast communication.
- High fault tolerance. Distributed databases use numerous processes to increase tolerance to failures or operational interruptions. These processes include data replication, data backup, continuous failure detection and load balancing.
- Query optimization. Distributed databases use techniques like cost-based query optimization to efficiently distribute queries across nodes, execute queries and minimize data transfer traffic between nodes.
- Failure detection. Distributed database systems detect issues like failed nodes and data tampering through continuous monitoring techniques, such as data and watchdog timers. These issues might result from technical problems, cyberattacks or natural disasters.
A common misconception is that a distributed database is a loosely connected file system. It's actually much more complicated. Distributed databases incorporate multiple nodes to replicate data and software to facilitate communication between these nodes. They also incorporate transaction processing (ACID-compliant) but are not synonymous with transaction processing systems.
Distributed database vs. centralized database
A centralized database consists of a single database file located at one site using a single network. The database is stored, modified and managed from a single location, and the location is accessed via an internet connection. It's easy to access and coordinate data in a centralized database since all the data is stored at one location. Data redundancy is also minimal, and costs are quite low, since there's no need to manage multiple locations or data sets.
A centralized database requires a lot of management effort. Data traffic also tends to be high, which can reduce database performance and create latency issues for users. Another important drawback of centralized databases is that they are vulnerable to single points of failure. In case of a failure event, such as a cyberattack, the entire database goes down, and the data within it can also be destroyed permanently.
By contrast, a distributed DBMS consists of multiple nodes that store data and are spread across multiple physical locations. The nodes communicate with each other using the network to facilitate data querying and access. The database integrates data logically so it can be managed as if it were all stored in the same location. Also, the DBMS periodically synchronizes all the data and ensures that data updates and deletes performed at one location are automatically reflected in the data stored elsewhere.
Distributed databases are more flexible and scalable than centralized databases. The distribution of data across multiple nodes, plus built-in fault tolerance and continuous database monitoring, increases data availability, reduces latency, and improves database performance. The risk of a single point of failure is also much lower, providing greater resiliency and ensuring continuous operations.

Types of distributed databases
There are two main types of distributed databases: homogeneous and heterogeneous.
Homogeneous distributed database
A homogeneous distributed database encompasses different sites (nodes/machines) that all store the same data. They also have the following characteristics:
- Use the same data model.
- Work with the same OS.
- Use the same DBMS across all sites.
A homogeneous distributed database is easier to manage because the nodes in it are all similar and store data in an identical manner. It also offers significant protection from data loss due to built-in redundancy.
Other benefits include scalability, high availability and improved data residency control. They can offer high performance even when handling large data sets and high-volume transactions.
Homogeneous distributed database systems appear to the user as a single system, and they can be much easier to design and manage. For a distributed database system to be homogeneous, the data structures and database application at each location must be either identical or compatible. Homogeneous databases can be autonomous or nonautonomous.
An autonomous distributed database consists of numerous database instances or nodes that are physically separate and work independently with their own complete set of data. These nodes only need a single centralized managed layer for centralized provisioning and universal updates (across all nodes) and to provide a unified logical view to applications. Autonomous databases provide particularly high availability, improved performance, and enhanced scalability for large data sets and high-volume transactions.
Unlike autonomous distributed databases, nonautonomous homogeneous distributed databases rely on centralized control using a single DBMS. While data is distributed across multiple nodes, the DBMS coordinates data partitioning, distribution, storage and retrieval. The DBMS also handles various complexities related to updates, communications, replication and ensures consistency across all nodes.
Heterogeneous distributed database
The other main distributed database type is a heterogeneous database. In these databases, multiple sites or machines house different data sets. They also use different schemas, Oses and database applications. The sites might not even be aware of each other. Different nodes can have different hardware, software and data structure, or might be in locations that are not compatible. Users at one location might be able to read data at another location but not upload or alter it. These differences can create problems during query processing and transactions can require translations between sites. Heterogeneous distributed databases also can be difficult to use, with associated costs prohibitive for many businesses.
Despite these complexities, heterogeneous distributed databases offer several benefits, including greater flexibility in data models and schema choices. Multiple nodes can function independently but also work together to respond appropriately to and process a query. This data virtualization is a key feature of heterogenous distributed databases of the federated type. An unfederated heterogeneous distributed database also consists of nodes that operate independently. But unlike federated databases, unfederated databases rely on a centralized application to coordinate data distribution, access, control, and updates.
Types of data in distributed databases
Replicated data is used to create instances of data in different parts of the database. By using replicated data, distributed databases can access identical data locally, avoiding traffic. Replicated data can be divided into two categories: read-only and writable data.
Read-only versions of replicated data allow revisions only to the first instance; subsequent enterprise data replications are then adjusted. Writable data can be altered, but the first instance is changed immediately.
Horizontally fragmented data involves the use of primary keys that refer to one record in the database. Horizontal fragmentation is usually reserved for situations in which business locations only need to access the database pertaining to their specific branch.
Vertically fragmented data involves using copies of primary keys available in each section of the database and accessible to each branch. Vertically fragmented data is utilized when the branch of a business and the central location interact with the same accounts in different ways.
Reorganized data is data that has been adjusted or altered for decision support databases. Reorganized data is typically used when two different systems are handling transactions and decision support. Decision support systems can be maintenance-intensive and online transaction processing might require reconfiguration when many requests are being made.
Separate schema data partitions the database and the software used to access it to fit different departments and situations. There is usually an overlap between different databases in separate schema data.
Advantages of distributed databases
There are many advantages to using distributed databases.
Data replication across multiple nodes increases data availability and minimizes database failures.
Distributed databases accommodate modular development, meaning systems can be expanded by adding new computers and local data to the new site and connecting them to the distributed system without interruption.
Also, different data structures and schemas can be used. Such scalability and flexibility are critical for modern applications that rely on vast data volumes and different data types that change at high velocities.
Distributed databases incorporate multiple mechanisms to enable proactive and continuous failure monitoring and investigations. In addition, there is no single point of failure since the data is placed in multiple nodes, increasing resiliency. Even if a component fails, the distributed system will continue to function, albeit at reduced performance, until the error is fixed. In contrast, a single failure in a centralized database can halt the entire system.
Built-in load balancing improves database performance, minimizes system inefficiency, and reduces user wait times. Distributed databases also offer query optimization to speed up query processing and reduce data transfer traffic between nodes.
Disadvantages of distributed databases
An important disadvantage of a distributed database is cost. Multiple servers or computer clusters are needed to replicate and distribute data, creating a need for additional hardware and networking elements. This increases complexity and cost.
Data consistency is another concern. Maintaining data consistency requires additional effort with multiple sites and data schemas.
Latency can be an issue when users query the database from multiple nodes. It's important to consider these issues during database design and to manage the database carefully to ensure data restoration (in case of failure) and maintain data security (to prevent data loss and data integrity degradation).
Examples of distributed databases
Though there are many distributed databases to choose from, some prominent examples include the following:
- Apache Ignite.
- Apache Cassandra.
- Apache HBase.
- Couchbase Server.
- Amazon SimpleDB.
- FoundationDB.
Apache Ignite is a distributed database for high-performance applications. It offers multi-tier storage and supports distributed ACID transactions. Ignite can be used as a traditional Structured Query Language (SQL) database by leveraging Java Database Connectivity (JDBC) drivers or Open Database Connectivity (ODBC) drivers. Users can also use native SQL APIs for numerous programming languages (Java, Python, C# and more) to execute custom tasks across the database. Additionally, developers can deploy continuous queries in any of these languages and process streams of changes on both the database and application side. Ignite integrates with TensorFlow to allow users to build scalable machine learning models.
Apache Cassandra is an open source NoSQL distributed database that uses multiple identical nodes, making it ideal for mission-critical data and applications that cannot afford to lose data. It features a masterless and elastic architecture to minimize the possibility of data loss in case of a data center outage. In addition, data replication across multiple data centers eliminates single points of failure and ensures high fault tolerance and low latency. Even if nodes do fail, they can be easily replaced to minimize downtime. Cassandra offers both synchronous and asynchronous replication for updates, provides an audit logging feature for enhanced security and observability, and is highly scalable. It also provides a tool to capture and replay production workloads for analysis.
Apache HBase is a scalable, distributed Hadoop database modeled after Google's Bigtable (a distributed storage system for structured data). HBase runs on top of the HDFS (Hadoop Distributed File System) and supports structured data storage for very large tables that can contain billions of rows and millions of columns. This versioned, nonrelational database is ideal for applications that need random, real-time access (read/write) to big data. It offers both linear and modular scalability, automatic failover support, consistent reads and writes, and automatic table sharding. In addition, users get a Java API for client access, a block cache for real-time queries, and an extensible JRuby-based (JIRB) shell.
Couchbase Server is a multipurpose, distributed NoSQL database ideal for AI-powered applications and applications where data must be managed for user profiles and dynamic product catalogs. The database applies object modeling, provides flexible JavaScript Object Notation (JSON) documents and supports distributed ACID transactions for NoSQL applications. Global cross-data center replication (XDCR) ensures database availability across clouds and on-premises locations. Developers can write SQL queries for querying and transacting JSON data using Couchbase's AI-powered copilot called Capella iQ. Couchbase also provides many other features like vector and text search to build better user experiences, key-value access for improved agility and flexibility, multi-dimensional scaling (MDS) to independently scale database services in a cluster, and role-based access control for enterprise-grade security.
Amazon SimpleDB is a NoSQL distributed data store that simplifies data storage and access. Users need not manage database administration tasks like infrastructure provisioning, schema management and performance tuning. SimpleDB works with other Amazon web services like Amazon EC2 and Amazon S3. Ideal for uses such as online games and indexing Amazon S3 object metadata, SimpleDB creates multiple geographically distributed data replicas to provide high data availability, durability, and flexibility.
FoundationDB is an open source multimodel database that can store and distribute many different data types safely. All the data is replicated in the database's key-value store component. It acts as an ACID database and features a distributed, scalable, fault-tolerant architecture. This database is suitable for applications that need to support heavy loads without appreciably increasing costs.
Certain initiatives require specific considerations when choosing database software. For instance, with IoT initiatives, SQL vs. NoSQL is an issue, as is static vs. streaming. Find out what to assess when selecting a database for an IoT project.







