What is data lineage? Techniques, best practices and tools
Organizations can strengthen data governance by mapping data lineage across systems. Learn how tools help to simplify tracking, compliance and lifecycle visibility.

Data lineage is the process of tracking, documenting and visualizing the journey of information over time. This methodology includes when and where data was generated, how it traveled between systems, how and why it was modified or transformed and where it surfaced. The process aims to convey the flow of data simply and provide deeper visibility and transparency into its lifecycle.
Why is data lineage important?
Data lineage provides advantages in several key areas:
Data management
Data lineage tools can simplify data management by automatically documenting data characteristics, including data type, structure, value, volume and timeliness. This makes it easier to assess data integrity, enhance data quality, fix errors and fill gaps in data sets.
Data lineage also tracks the data lifecycle from creation to archival, providing information to support change management, data processing and data transformation.
Analytics and business intelligence (BI)
Data lineage products can help business users find relevant data for analytics and BI tools. This improves data-driven decision-making by verifying the accuracy and reliability of data and providing additional context about its origins.
Data lineage visualizations can build trust in data by presenting it in a more digestible format to make it easier for non-technical users to understand.
Data governance and regulatory compliance
Data lineage can improve data governance by providing comprehensive data handling and usage records. Many lineage tools have intuitive tagging functionality and ownership monitoring, which adds a layer of accountability across the data ecosystem. These features simplify how to apply requirements, policies and standards, while streamlining audits and regulatory compliance.
Root cause and impact analysis
When problems occur in the data pipeline, they can cause cascading effects that create bottlenecks and downtime. Data lineage brings visibility to identify the origin of the issues and address their root cause.
This transparency can simplify impact analysis by highlighting relationships between data and across systems, making it easier for users to understand dependencies, flag downstream or upstream effects of changes and expedite resolution time.
Security and privacy
Data lineage provides a comprehensive metadata inventory for organizing data and providing context. This information can help organizations flag data subject to security standards and privacy policies, allowing more effective protection of sensitive data and ensuring user access control.
In the event of a breach, data lineage tools can identify affected data, determine when and where the breach occurred and even establish accountability for the breach.
Data lineage vs. data classification vs. data provenance vs. data governance
Data management covers a broad spectrum of data processes, which can create confusion around the specific terms. For example, data lineage and data provenance are often used interchangeably, but there are distinct differences between the two.
The following four data management terms often overlap in usage, but knowing how they differ can help teams improve how they manage and talk about data processes.
- Data lineage tracks, documents and visualizes the journey of information over time.
- Data classification categorizes information based on specific characteristics.
- Data provenance documents the historical record of information and validity of data sources.
- This process shares some overlap with data lineage; however, data lineage often provides a more high-level look at the data's journey, whereas data provenance determines the data origin and authenticity of the source.
- Data governance establishes the framework to ensure data is accurate, secure and complies with regulatory standards and requirements.
- Data lineage can help data governance by simplifying data directives and procedures to enforce proper access and handling by users.
Understanding the distinction between these processes assists organizations with their efforts to organize data flow and streamline data management.
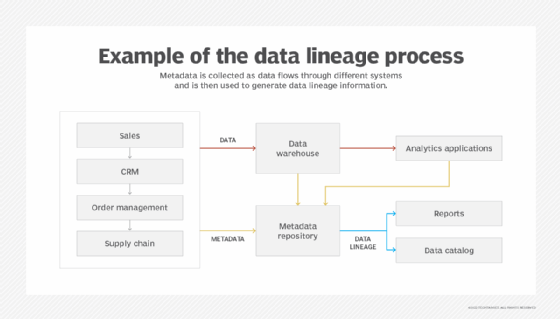
Key data lineage types and techniques
Data lineage tools can differ in the types of lineage they provide and the techniques they employ. Here are a few worth knowing:
- Business lineage gives context and relevance to information within an organizational framework. It defines how data flows to BI and analytics tools, how it's surfaced to business users and how it supports business processes to drive outcomes.
- Operational lineage focuses on the more technical aspects of data flow. It involves detailing the steps of data processing and data transformation, which can help optimize data pipelines and improve overall performance.
- Upstream lineage tracks data from its point of origin to its current state.
- Downstream lineage tracks data from its current state to its destination.
- Hybrid lineage combines upstream and downstream lineage to create a more comprehensive look at data flow.
- Pattern-based lineage identifies connections in data sets to uncover inconsistencies, gaps or transformations. This method is straightforward but may lack specificity, leading to inaccurate or incomplete conclusions.
- Parsing-based lineage traces data lineage by reverse-engineering the transformation logic of data sources to chart the flow of data. This method can be more accurate than pattern-based lineage but also more complex.
- Metadata management analyzes and organizes information about data. It's an essential part of data lineage, along with data tagging, which adds metadata labels to data.
- Data mapping defines the relationships between data across sources and systems to help clarify dependencies and ensure consistency during data transformations or migrations.
- Data visualization depicts the flow of data with visual elements -- such as graphs, flowcharts and diagrams -- to assist technical and non-technical users.
Data lineage examples and use cases
Here's a look at how data lineage can be applied in the real world:
- Root cause analysis. A cybersecurity company could quickly identify errors in the data pipeline with a data lineage tool and trace them back to the root cause to help mitigate security risks and shore up vulnerabilities in the perimeter.
- Data migrations. To minimize downtime during a data migration in a government organization, data lineage could be used to identify relationships between data elements and highlight dependencies, boosting efficiency and maintaining uptime.
- Data auditing. A financial services organization could use a data lineage tool to automate audits, identifying financial data attributes and highlighting transformations -- including when and where they took place -- to streamline and organize the compliance process.
- Predictive analytics. A marketing company could use data lineage tools to enhance data quality, then use predictive analytics algorithms with that data to track customer demand patterns and predict market trends.

Data lineage best practices
In the modern data landscape, there are some important considerations when charting data lineage. Best practices include:
- Define clear data governance policies. Establish standards for data quality, procedures to maintain security and privacy and document best practices and responsibilities to ensure consistent compliance and implementation.
- Establish strong user permissions and access controls. Protect data by controlling who can view, manage and interact with data lineage information with role-based permissions. Enhance security around sensitive data with encryption. Start log tracking to provide accountability for user actions.
- Implement data management processes to ensure data quality. Data cleanliness is key to operational efficiency. Keep data organized during its lifecycle, from collection to storage and beyond. Use consistent naming for data fields, establish clear data structures and assign data owners and stewards to oversee data management procedures and assure data quality.
- Standardize data collection and specifications. When new data is generated, it should fit seamlessly into the existing data ecosystem. Document data sources clearly and create templates that specify required characteristics to ensure accurate and complete data sets.
- Regularly update lineage information. Data lineage requires continuous maintenance. As the organization grows and integrates new data sources, revisit data structures, governance policies and data management procedures. This process ensures users interact with accurate and timely data.
Should data teams adopt data lineage?
Data lineage tools offer clear advantages for data teams, especially in complex or large-scale environments. For example, data lineage tools help organize data and ease the introduction of governance frameworks in enterprise ecosystems. Data lineage also supports responsible AI development by providing context behind data inputs to ensure outputs come from reliable information.
In addition, data lineage can improve data pipeline efficiency in environments of all sizes. Whether it's an enterprise looking to manage complexity at scale or a small business trying to understand data flow better, data lineage can provide much-needed visibility and control with intuitive functionality and digestible insights.
That said, data lineage can require some manual maintenance, both during setup and ongoing management. Organizations with a complex data landscape or a disorganized data ecosystem with a variety of raw, unstructured data can face integration hurdles. Complexity can also pose challenges with scale, especially if users disregard appropriate procedures and best practices.
However, when applied effectively, data lineage can be a critical tool for ensuring data quality and transparency.
What to look for in data lineage tools
Data lineage tools offer a range of capabilities that organizations may or may not need, depending on their goals. A feature-rich data lineage product will likely include the following:
- Master data management features, including metadata tagging and labeling.
- End-to-end visibility and traceability, including tracking and monitoring.
- Streamlined data flow mapping and transformation tracking.
- Comprehensive visualization options, such as logic graphs and reporting templates.
- Automated discovery, documentation and validation for compliance and governance.
- Impact and root cause analysis capabilities to track and document data history.
- Customizability to tailor the tool to unique organizational needs.
- Seamless integrations, including scalable API support.
Data lineage vendor list
Here are some of the top data lineage vendors, listed alphabetically:
- Alation: An agentic data intelligence platform recognized as a "Leader" in The Forrester Wave for Data Governance Solutions, Q3 2025 report.
- Astro by Astronomer: A unified data operations platform that provides data orchestration and data observability capabilities with end-to-end pipeline visibility.
- Atlan: An active metadata platform recognized as a "Leader" in The Forrester Wave for Data Governance Solutions, Q3 2025 report.
- Collibra: A unified governance platform for data and AI recognized as a "Leader" in the 2025 Gartner Magic Quadrant for Data and Analytics Governance Platforms report.
- Dataedo: A data governance and data quality platform with full-featured data lineage functionality designed for mid-sized organizations.
- IBM watsonx.data intelligence: An automated data lineage platform that enables full visibility and data traceability at scale.
- Informatica: An AI-powered intelligent data management cloud platform recognized in four Gartner Magic Quadrant reports.
- Octopai: An automated data lineage platform that can navigate cloud, on-premises and hybrid data environments.
- OpenLineage: An open platform for data lineage collection and analysis designed to support both single consumer and enterprise-wide deployments.
- Precisely: A data catalog that features automated metadata gathering and interoperability with a variety of enterprise APIs and data sources.
- Secoda: An AI platform for data and analytics that can apply enterprise data governance and context across the data stack.
- Talend: A modern data management platform recognized in the 2024 Gartner Magic Quadrant for Data Integration Tools report.
These vendors were identified based on several criteria, including feature offerings, niche application, customer ratings and satisfaction, industry recognition and independent evaluations.
When implemented effectively, the data lineage process visualizes the flow of data in an organization, illustrates the journey of data throughout its lifecycle, provides much-needed context about data, and reinforces data quality and reliability at scale.
Jacob Roundy is a freelance writer and editor specializing in a variety of technology topics, including data centers and sustainability.







