
data catalog

What is a data catalog?
A data catalog is a software application that creates an inventory of an organization's data assets to help data professionals and business users find relevant data for analytics uses. It also aids in data governance by incorporating governance policies and controls, data quality rules, a business glossary with common terms and other information meant to ensure that data is used properly.
Data catalogs are driven by metadata, the descriptive data about data that's used to create the data inventory. The underlying metadata also provides contextual information about data assets to help catalog users understand the data that's available in IT systems and decide whether it fits their needs.
The use of data catalogs is growing as organizations rely more and more on data analytics to drive business strategies and operations. Catalogs are now a core component of many data management environments, and market research firm IDC has forecast that worldwide revenues for data catalog software will increase at a compound annual growth rate of 16.8% from 2020 to 2025.
How do data catalogs work?
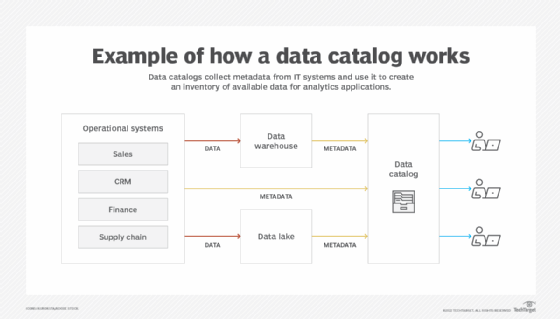
A data catalog collects metadata from different source systems and from data warehouses and data lakes that support business intelligence (BI), analytics and data science applications. Built-in metadata management functions organize and enrich the metadata to make it useful for end users. For example, tags can be applied to data entries to add more information about them, such as data classification settings, data quality scores and usage metrics. Increasingly, artificial intelligence (AI) and machine learning algorithms are used to automatically ingest, catalog, classify and tag metadata.
The data inventory in a catalog is searchable; typically, users can search on business terms, technical names, tags and other keywords or through natural language queries. Data catalogs also provide automated search recommendations, like regular search engines. Alternatively, users can browse through a catalog to look for data that meets their application needs. Overall, catalogs are designed to evoke a "data shopping" experience.
To aid users in understanding data, catalogs include data lineage details, such as where data is created and how it flows through IT systems and is transformed for different uses. They also offer data curation capabilities that enable data management and analytics professionals to organize data sets for their own applications or for other users to access. Functions for adding comments, reviews and ratings to data entries are commonly embedded, too, as are chat features and other collaboration tools.
Types of metadata collected in data catalogs
Different kinds of metadata are pulled into data catalogs to provide a wide range of information about the data assets listed there. The following are the three primary types of metadata that are used in a data catalog.
Technical metadata. Also sometimes referred to as structural metadata, it provides information about the technical structure of data. For example, technical metadata describes the schemas, tables, columns, indexes, file names and other objects in databases and data warehouses. It also identifies where data is located in IT systems and documents things such as data types, data models and automated data transformation scripts.
Operational metadata. This describes how data assets are created, updated, changed and used, as well as when data was processed or modified and who updated or transformed it. The metadata can also include the names of data owners and data stewards, statistics on data usage and details on data access rights and restrictions. It's sometimes called process metadata, although that is also viewed as a subset of operational metadata focused on the steps involved in data processing, management and analysis.
Business metadata. This applies business context and meaning to data assets to help catalog users understand them. For example, it includes internal data definitions and relevant business terms, such as the ones listed in business glossaries. Other business keywords can be added, too. Data classifications, business rules and information on the business domains that data was created in and its fitness for particular uses are also examples of business metadata.
Data catalog users and use cases
A data catalog is used by various people in an organization. On the end-user side, that includes data scientists, other data analysts, data engineers and members of BI teams, as well as business analysts, executives and managers looking to analyze data. Data stewards and other members of data governance teams also use data catalogs as part of managing the governance process. In addition, regulatory compliance and risk management officials use them to track how data assets are managed and used.
The following are some common use cases for data catalogs.
Data discovery. As mentioned above, the main purpose of a data catalog is to help analytics users find the data they need. Without one, data discovery can be a laborious, time-consuming process -- one of the reasons for the maxim that data scientists spend 80% of their time looking for and preparing data and just 20% analyzing it. Even worse, they may not know about some relevant data, which can reduce analytics accuracy. A data catalog is designed to streamline data discovery and make it more effective.
Self-service analytics and BI. Data discovery is a lead-in to the analytics process. With the help of a data catalog, it's much easier for data scientists and analysts to do machine learning, predictive modeling and other advanced analytics applications without requiring any assistance from the IT and data management teams. Similarly, business users are better able to access and analyze data sets on their own for self-service BI applications.
Data governance and stewardship. A data catalog can help data governance managers and data stewards ensure that users comply with governance policies and procedures. For example, they can define policies in a catalog, automate data governance workflows and track changes to data sets and user access controls. The business glossary also helps drive effective data governance, and built-in quality assessment and monitoring functions can boost related data quality improvement initiatives.
Data curation. By using a data catalog to curate data sets for analysis, data curators can further streamline the analytics process and make sure that all of the data needed for applications is included. That's particularly helpful on analytics applications run repeatedly; in addition, curated data sets can be reused for other purposes. Data curator is a formal role in some organizations. In others, curation may be handled by various data professionals, including BI teams and data scientists, analysts and engineers.
Benefits that a data catalog provides
Most organizations build an enterprise data catalog to inventory all of their data assets. Some, especially large organizations, may have multiple data catalogs for individual divisions and business units. In both cases, the benefits that a data catalog can provide include the following:
- More accurate analytics. By making it easier for users to find all of the applicable data for analytics applications, a data catalog helps improve the accuracy of the results.
- Better business decisions. Improved analytics results drive more informed decision-making by business executives, ideally leading to stronger business strategies and operational decisions.
- Productivity improvements. A data catalog reduces the time users spend looking for data, enabling them to do more analytics work. It can also eliminate duplicate data transformation and preparation tasks by different analysts.
- Higher-quality data that's more reliable. Embedded data governance, data quality and data security functions help create trusted data sets for analytics users.
- Improved regulatory compliance. Built-in data classification settings, access controls and governance policies can help boost compliance with data privacy laws and other regulations.
- Increased analytics and business agility. A data catalog also enables data scientists and other analysts to respond more quickly to changing business needs for analytics information.
Key features of a data catalog
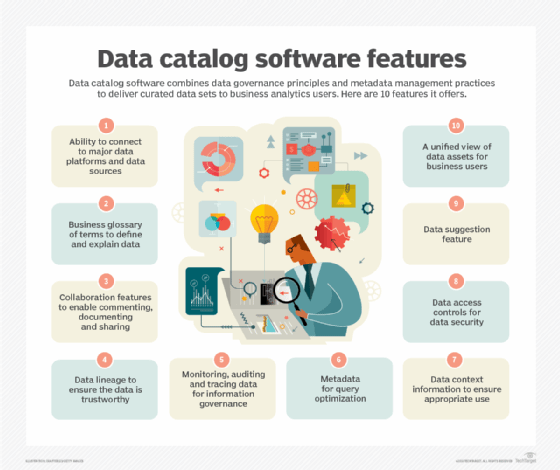
While a data catalog is first and foremost an inventory of data assets, it provides a broad set of features for end users and data management and governance teams. The following items are some common data catalog features:
- Connectors to various data sources. These enable the data catalog to harvest metadata from operational systems, data warehouses, data lakes and other repositories.
- Metadata management tools. Data management teams and other catalog users can use these tools to organize, classify and enrich metadata after it's ingested into the catalog.
- AI and machine learning algorithms. Metadata harvesting, cataloging and tagging are often now automated through the use of built-in AI and machine learning technology.
- Business glossary. It contains internal definitions of business terms and concepts, such as what constitutes a customer, for mapping them to data assets listed in the catalog.
- Data lineage functions. They use the metadata in the catalog to document and provide visualized views of data flows, data transformations and other historical details about data.
- Search capabilities. To aid in data discovery, users can search the data catalog's contents by keywords or natural language queries and get recommendations about relevant data.
- Collaboration tools. Catalog users can chat and share information with each other, work together on data workflows and comment on, review and rate data assets.
- Integrated data governance. Embedded tools support various steps in the data governance process, including data stewardship, data quality management and data security.
Data catalog tools and vendors
Numerous software vendors offer data catalog tools that automate the process of building and managing data catalogs, with the features mentioned above included. The following are some prominent vendors:
- major IT vendors and cloud providers, such as AWS, Google Cloud, IBM, Microsoft and Oracle;
- software vendors with broad product portfolios that include data management and governance tools, such as Hitachi Vantara and Quest Software;
- vendors that focus on data management and governance, such as Ataccama, Boomi, Collibra, Informatica and Talend;
- data catalog and metadata management specialists, such as Alation, Alex Solutions, Atlan, Data.world, OvalEdge and Zeenea; and
- BI and analytics software vendors that offer companion data catalog tools, such as Alteryx, Qlik, Tableau and Tibco.
In a July 2022 report on emerging data management technologies, consulting firm Gartner said AI-driven data catalog tools -- or augmented data cataloging and metadata management solutions, as it now calls them -- are in the "early mainstream" stage of maturity. They likely won't become fully mature for another two to five years, Gartner added. But it gave the tools a "High" rating on potential benefits for user organizations.
Alternatively, there are various open source data catalog tools that organizations can use. Examples include Amundsen, Apache Atlas, DataHub and Metacat.







