15 top data catalog software tools to consider using in 2026
Organizations can use numerous tools to build and manage data catalogs. Here are 15 prominent ones that data leaders should consider for their data management needs.
When data sprawls across various repositories, data management becomes more challenging. Analytics and AI applications are also less effective if data scientists and other end users can't find relevant data or understand its business context. In many cases, "organizations are drowning in data yet starving for insights," said Priya Iragavarapu, managing director of the AI practice at consulting firm AArete.
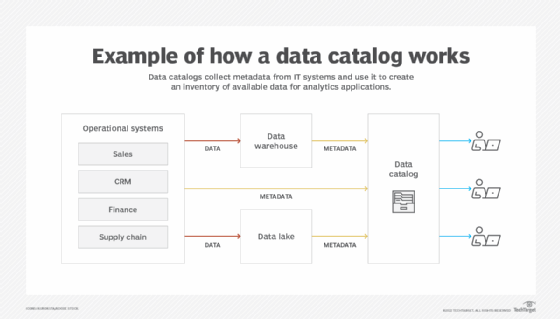
Data catalogs provide a unified inventory of enterprise data assets, making them more manageable, accessible and understandable. Data management teams can use a wide range of tools to build and manage catalogs. Data catalog tools collect metadata from various data sources and use it to organize, classify and enrich data entries. They're commonly integrated with data governance software to help organizations manage data quality, data use and regulatory compliance.
Increasingly, data catalog software also incorporates generative AI (GenAI), machine learning (ML) and other AI technologies to streamline catalog development and use. For example, early data catalogs required custom scripts to crawl data and harvest metadata, but modern tools do so automatically. AI assistants and agents handle cataloging tasks and help end users find data.
To help inform product evaluations by data leaders, the following are 15 notable data catalog tools, listed in alphabetical order with details on their key features and capabilities. TechTarget editors compiled the list based on research of available technologies, as well as market reports and vendor rankings from Forrester Research and Gartner.
1. Alation Data Catalog
Alation Data Catalog uses AI, ML, automation and natural language processing to simplify data discovery, create business glossaries and power its core Behavioral Analysis Engine. The engine generates popularity rankings, usage recommendations and other insights about data sets. It also analyzes data usage patterns to help streamline data stewardship, data governance and query optimization processes.
Allie AI is an AI copilot that documents new data assets, recommends metadata descriptions and identifies potential data stewards. Alation Data Catalog includes a set of prebuilt analytics dashboards with customizable reporting, and collaboration features enable users to create wiki articles and searchable conversations in data catalogs. The tool is part of the broader Alation Agentic Data Intelligence Platform, which also offers data governance, data lineage and data product marketplace applications.
Other key features in Alation Data Catalog include the following:
- Capabilities for flagging data health issues and defining enterprise data governance policies.
- More than 120 connectors to data sources, plus an Open Connector Framework SDK for building custom ones.
- A SQL editor for creating data queries that can be published in catalogs for sharing and reuse.
2. Alex Augmented Data Catalog
Alex Augmented Data Catalog provides various automation, AI and ML capabilities to support catalog creation and metadata management. Developed by Alex Solutions, the software automates data discovery and cataloging. It includes built-in features for data profiling, lineage tracking and metadata enrichment, plus a set of AI agents for tasks such as data classification and anomaly detection in data sets.
The data catalog tool also automates aspects of data governance and data quality processes. Data governance managers can use it to create policies, assign data stewards and monitor compliance with internal policies and regulatory requirements. The software automatically identifies data quality issues, and data stewards can analyze their potential impact on business workflows and alert data owners about necessary fixes.
Alex Augmented Data Catalog also provides the following features:
- Google-like natural language search and query capabilities.
- Plug-and-play metadata connectors to various data sources.
- A no-code ontology for classifying and organizing data based on business terminology, processes and objectives.
3. Ataccama Data Catalog
Ataccama Data Catalog is a core component of Ataccama One, an AI-driven platform centered on data quality management. The tool automatically monitors data sets for anomalies, data quality issues and structural changes while providing built-in quality rules as well as capabilities for creating custom ones. It also captures data lineage documentation and includes data profiling, data classification and metadata management capabilities.
An AI agent added to Ataccama One in November 2025 handles various tasks autonomously in data catalogs, such as profiling data, assessing data quality, and creating and applying quality rules. GenAI capabilities enable catalog users to create SQL queries, generate data descriptions and perform other tasks in natural language. In addition, Ataccama Data Catalog runs AI and ML algorithms to identify patterns, trends and relationships in data sets.
The catalog software also includes the following features:
- Indexing of reports, dashboards and data stories for BI and analytics uses.
- Collaboration features that enable users to add comments and ask questions about data assets.
- A data marketplace function to make data products available for reuse.
4. Atlan Data Catalog
Atlan Data Catalog borrows design principles from Google and tools such as GitHub and Slack. It enables users to search for data assets in natural language using keywords or associated business metrics, while providing a SQL syntax search capability for data engineers. Organizations can also integrate collaborative data workflows into catalogs. For example, users can discuss data in Slack chats and create Jira tickets to report data issues.
A Companion Sidebar feature provides at-a-glance information about data lineage, usage history, Slack threads, Jira issues and more to help users decide whether data is relevant and trustworthy. Atlan AI, a copilot tool, generates descriptions of data assets, data lineage summaries, SQL queries and definitions of business terms, metrics and KPIs.
Part of a broader data and metadata management platform that aims to create an enterprise context layer in organizations, Atlan Data Catalog also includes the following features:
- Open APIs that enable fully customizable metadata ingestion.
- More than 80 connectors to data platforms and tools.
- Role-based filtering to personalize catalog browsing for different users.
5. AWS Glue Data Catalog
AWS Glue Data Catalog is the persistent metadata store in AWS Glue, a fully managed extract, transform and load (ETL) service. Data management teams can use it to store, annotate and share metadata for use in ETL data integration jobs on the AWS cloud platform. It also provides a consistent metadata layer for querying and analyzing data across various AWS data stores, using integrated analytics services such as Amazon Athena, Amazon EMR, Amazon Redshift Spectrum and Amazon SageMaker AI.
As in traditional relational database catalogs, AWS Glue Data Catalog organizes metadata into databases and tables. The software is compatible with the metastore repository in Apache Hive and can be used as an external metastore for Hive data in Amazon EMR clusters. Organizations can also import technical metadata from the catalog tool into business data catalogs in Amazon DataZone, a separate data management service.
Other features in AWS Glue Data Catalog include the following:
- A wizard for creating crawlers that automatically scan data sources and extract metadata.
- Automated schema management and data lineage documentation.
- Integration with AWS Lake Formation for defining and managing data access policies.
6. Coalesce Catalog
Known as CastorDoc before Coalesce acquired and renamed it in March 2025, this AI-powered tool provides automated data documentation and natural language search capabilities. An AI assistant helps catalog users find relevant data, write SQL queries and understand data governance policies. Coalesce Catalog also automatically maps data lineage information and creates a metadata-driven semantic layer that applies business context to the data in a catalog.
Advanced data filtering, popularity signals, freshness indicators and certification badges help users evaluate data assets for use in analytics applications. Coalesce Catalog streamlines data classification and incorporates data governance features, including role-based access control and guided access request workflows. The catalog software is offered in a platform alongside Coalesce's original data transformation tool; the company is working to fully integrate the two tools.
Coalesce Catalog also includes the following features:
- Integration with more than 30 data platforms and related tools.
- Interfaces for searching data catalogs in Slack or Teams.
- Audit trails for monitoring data use and regulatory compliance.
7. Collibra Data Catalog
Collibra offers a namesake data and AI governance platform centered on Collibra Data Catalog. The tool provides automated data discovery, classification and curation powered by AI and ML, including the use of GenAI to create descriptions of data assets. It also automates data profiling and data lineage mapping across source systems. An integrated AI copilot helps catalog users find data and associated business definitions.
Collibra Data Catalog includes more than 100 prebuilt integrations for ingesting metadata from various data stores, business applications, BI platforms and data science tools. It provides configurable workflows for managing data catalogs, as well as guided data stewardship features and controls for enforcing data security and privacy protections. An embedded semantic layer connects technical metadata to business terms and concepts.
The Collibra software also offers the following features:
- Built-in views of data quality metrics and support for certifying trustworthy data.
- Collaboration capabilities, including crowdsourced feedback on data assets through ratings, reviews and comments.
- An integrated data marketplace where users can search for relevant data products and other curated data assets.
8. Data.world
Acquired by ServiceNow in July 2025, Data.world is a cloud-native data catalog tool offered as a SaaS platform. It's built on a knowledge graph architecture that provides a semantically organized view of enterprise data assets and their associated metadata across disparate systems. It also automates data quality checks, tracks data lineage and creates visualized maps of data relationships and dependencies.
Data.world includes a set of AI bots that help organizations deploy and manage data catalogs and automate data governance tasks. Archie Chat, a conversational AI assistant, provides a chat-like data discovery interface to assist catalog users in data searches, suggest research questions and generate natural language descriptions of data assets and metadata.
Other notable features in Data.world include the following:
- Collaborative querying capabilities and automated documentation of queries and related comments in a searchable repository.
- Customizable data governance workflows and task management processes.
- A data product marketplace with an online shopping UX.
9. Dataplex Universal Catalog
Dataplex Universal Catalog ingests technical metadata from Google Cloud and on-premises data sources and enables users to enrich it with business context. Google released the tool in 2024 to replace an older data catalog service. New features include a unified web interface and API, more advanced governance capabilities and wider metadata support.
Metadata change feeds enable data teams to track metadata updates in near real time and trigger automated workflows, such as data quality scans, compliance audits and security policy updates, when specified changes occur. Dataplex Universal Catalog also integrates with Google's BigQuery data platform and Vertex AI service to support data and AI governance initiatives. It automatically captures data lineage documentation and includes built-in data profiling and data quality management capabilities.
The catalog software also includes the following features:
- Automated metadata harvesting from various Google Cloud data sources, and support for ingesting metadata from other systems.
- Keyword and natural language search options.
- Search-driven access to data insights generated in BigQuery Studio using Google's Gemini AI assistant.
10. Erwin Data Catalog
Erwin Data Catalog is now part of Quest Trusted Data Management Platform, a software suite introduced in February 2026 that also includes Quest Software's data modeling, governance, quality and marketplace tools. The software automatically harvests, catalogs, enriches and curates metadata. It also supports drag-and-drop data mapping, reference data management, data lifecycle management, data lineage documentation and data classification.
Standard data connectors ingest data from commonly used databases. Optional ones are available for streaming data, cloud applications, BI environments and other data sources. Erwin Data Catalog integrates with a companion data literacy tool to aid in data discovery and governance. Built-in version management and change control functions track changes to data mappings and documentation.
The catalog tool also provides the following features:
- A dashboard provides high-level views of data catalog metrics and drill-down analysis capabilities.
- An impact analysis function for assessing the potential effects of changes to data attributes or tables.
- Automated functions accelerate data movement and transformation, as well as code generation and documentation.
11. IBM Watsonx.data intelligence
IBM Watsonx.data intelligence is a data governance and metadata management software suite launched in May 2025 that includes the former IBM Knowledge Catalog tool. It catalogs structured, unstructured and semistructured data, as well as ML models and other analytics assets. It supports AI-driven data discovery and provides automated data governance functions for tasks such as data quality assessments and data privacy policy management.
The software also includes metadata enrichment capabilities powered by large language models, plus a set of Knowledge Accelerators -- industry-specific vocabularies of business terms designed to streamline data governance and analytics deployments. It visually maps relationships between data assets and governance artifacts, using a knowledge graph and the FoundationDB open source database originally developed by Apple.
The catalog tool offers the following features as well:
- Data profiling, cleansing and validation capabilities.
- Support for creating data protection rules to control access to sensitive data.
- Integration with data lineage and data product marketplace tools that are also part of Watsonx.data intelligence.
12. Informatica Data Catalog
Informatica Data Catalog is part of the AI-powered Intelligent Data Management Cloud (IDMC) platform developed by Informatica, which Salesforce acquired in November 2025. The catalog tool uses Claire, Informatica's AI engine, to automatically find, ingest, classify and inventory data. Automated data curation features also use AI and ML algorithms to identify relationships between data sets and associate business terms with technical metadata.
Data lineage capabilities track data as it moves through systems and data pipelines, supporting impact analysis when data changes. Built-in collaboration capabilities let users add reviews, ratings and annotations to data assets, and subject matter experts can answer questions through a Q&A feature. Informatica Data Catalog also integrates with other IDMC tools, including data governance and data marketplace services.
In addition, the catalog software provides the following features:
- Automated data profiling and built-in functions for applying data quality rules and monitoring quality levels.
- A natural language search function and browsable hierarchical views for finding relevant data in a catalog.
- A knowledge graph that visually displays the connections between related data assets.
13. Microsoft Purview Unified Catalog
This tool is part of Microsoft Purview, a data security, governance and compliance service that runs in the Microsoft Azure cloud. Initially known as Microsoft Purview Data Catalog, it was renamed in late 2024, when Microsoft launched a revised data governance offering. The software runs on top of Microsoft Purview Data Map, a companion metadata management tool that scans data sources, ingests metadata and automatically classifies data.
In Microsoft Purview Unified Catalog, users can search for individual data assets or data products, such as tables, files and Microsoft Power BI reports. An embedded business glossary can also be used to find relevant data products by searching for terms, key data elements or business objectives. An AI copilot aids in catalog searches.
Other features in the catalog tool include the following:
- Data curation for organizing data by governance domains and grouping related data assets and products.
- Built-in data quality rules, plus data quality scanning, scoring and alerting functions.
- Workflows to help organizations track data governance practices and address issues.
14. OvalEdge Data Catalog
OvalEdge Data Catalog is the foundation of OvalEdge's namesake data governance platform. The catalog software crawls data sources and uses AI and ML algorithms to ingest, organize, enrich and curate data assets. It also provides AI-driven data classification and automated data lineage generation, including data flow diagrams that show how data moves through systems. Users can create custom fields to collect extended metadata types, such as access permissions and source-specific attributes.
OvalEdge Data Catalog includes built-in functions for data profiling and documenting relationships between data objects. It also tracks data use and generates popularity and importance scores to help teams prioritize data curation efforts. The tool supports both keyword and natural language search. OvalEdge's agentic AI chatbot, askEdgi, streamlines metadata search and analysis and triggers automated data governance workflows.
The data catalog software also includes the following features:
- Native connectors to more than 150 data sources.
- Question Wall, a centralized hub for knowledge sharing and collaboration.
- Integration with tools such as Slack, Jira and ServiceNow.
15. Precisely Data Catalog
A foundational component of Precisely Data Integrity Suite -- a broad data management and governance platform -- Precisely Data Catalog uses AI algorithms to automatically ingest metadata and generate data descriptions. Users can then curate data with Precisely's Gio AI Assistant and Data Catalog Agent. For example, the agent identifies and tags critical data, flags personal information for oversight and aligns metadata with business processes and regulatory compliance needs.
Precisely Data Catalog automatically applies data quality rules and scores to metadata. It also creates data profiles and continuously monitors data health to detect anomalies and other issues. Connectors to more than 20 data sources are currently available, while a variety of others are planned or available by request.
The catalog tool also includes the following features:
- Use of Precisely's data governance service to add business metadata to catalog entries.
- Visualization of data lineage and relationships.
- Integration with workflow management and data security tools that are also part of the Precisely platform's foundation.
Editor's note: TechTarget editors updated this article in March 2026 for timeliness and to add new information.
George Lawton is a journalist based in London. Over the last 30 years, he has written more than 3,000 stories about computers, communications, knowledge management, business, health and other areas that interest him.
Craig Stedman is an industry editor at TechTarget who creates in-depth packages of content on data technologies and processes.






