Synthetic data vs. real data for predictive analytics
Synthetic data helps simulate rare events and meet privacy compliance, while real data preserves natural variability needed to evaluate models against unpredictable conditions.
Data engineers face a paradox: Building effective AI models requires more data, but access to real data is increasingly limited by privacy, security and regulatory constraints.
Synthetic data is artificially created rather than collected from real-world events. It's essential in privacy-minded, sensitive industries or when real-world data sets are limited. For data scientists and AI engineers, synthetic data is a tool that can significantly improve the performance and reliability of models and data pipelines.
However, this approach has nuances and risks. Questions of ethics, governance and data quality still arise, even if the data isn't real.
Types of synthetic data
Synthetic data broadly consists of two types:
Fully syntheticdata. Created from scratch using algorithms or generative models like generative adversarial networks (GANs) or variational autoencoders.
Partially syntheticdata. Created by replacing only sensitive attributes in real data sets.
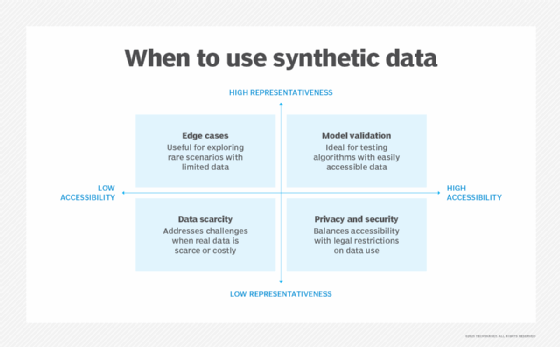
Key decision points for using synthetic or real data across common development and compliance scenarios.
Generating synthetic data
Synthetic data generation techniques have advanced significantly. Early models relied on rule-based systems and basic statistical methods. Sample data sets from databases or business intelligence (BI) vendors often use simple rules that define value ranges and patterns of data values within a specific column.
Modern engineers use various generation methods that build on these early approaches. Simpler methods include random sampling from statistical distributions that reflect the characteristics of the original data. More complex approaches, such as agent-based modeling, simulate individual agents behaving like customers and generating data in the system.
The real innovation has come from deep learning approaches. GANs work by setting two neural networks to work against each other. One generates synthetic data, while the other tries to distinguish that from real data. Over time, the synthetic outputs start to mimic the real data set's statistical distribution. This method can replicate complex patterns such as customer churn, browsing behavior, transaction sequences and rare edge cases. Through this adversarial process, the generator becomes skilled at creating realistic synthetic data.
The original data is assumed to be representative of a real-world environment. This matters because the generative model doesn't distinguish between useful signals and embedded noise unless actively guided. So, validating the quality of the original sample data is an essential step in creating this kind of synthetic data.
For example, sample data cleaned from the original data -- removing duplicates, incomplete records or data-entry errors -- might be suitable for modelling customer demographics, but it won't capture the messy reality of customer behavior that generated the original data set.
Governance and synthetic data
Fully synthetic data can be valuable for data governance under regulations like HIPAA or GDPR. It reduces the risk of reidentification because it doesn't correspond to a real individual.
In addition to fully synthetic techniques, partially synthetic methods, such as differential privacy, add carefully calibrated noise to protect individual records while maintaining statistical properties.
For example, differential privacy might alter a birthdate by adding or subtracting a random number of days within a given range. The result is no longer identifiable by this date, which is now partially synthetic but remains close enough for most analytics and predictive models.
Nevertheless, these techniques require disciplined oversight and should not be treated as a free pass on compliance. Even if data is synthetic, it's bound by organizational controls, including access management and tracking data lineage. If BI analysts pull synthetic data into dashboards, the metadata must clearly indicate what's real, what's synthetic and how it was generated.
While differential privacy limits the probability that any one data point is tied back to a real person, teams rarely audit the data post-synthesis. A reproducible audit trail should be part of every synthetic data pipeline.
The trade-offs of real and synthetic data
Real data reflects the complexities of the world, such as irregularities, seasonality and unpredictability. While real-world data collection is a more straightforward concept, it's often more complex in practice.
It is often expensive and time-consuming, particularly in new or experimental scenarios. Getting permission to collect real data in some regulated industries can take weeks due to significant privacy and ethical concerns. Obtaining proper consent, ensuring data security and complying with regulations, such as the GDPR or HIPAA mentioned above, results in new layers of complexity.
Bias is another concern in real-world data collection. Real data might reflect existing patterns that are no longer appropriate or representative. For example, women or minorities might be underrepresented in some insurance data sets going back several years. Less controversial but still problematic, data collected from a cellphone provider will reflect usage patterns from older plans and devices, which are less relevant today. Models trained on this data risk perpetuating or even amplifying those distortions.
However, in some cases, real-world data might be so uniform that rare events or edge cases can be difficult to model statistically. For example, a fraud alert model for a transaction processing system may not include enough examples of fraud to train the algorithm effectively.
For these scenarios, synthetic data offers complete control over the data generation process, allowing for the creation of test data sets that include edge cases missing from real data.
Limitations of synthetic data
In practice, synthetic data is only as reliable as the models and assumptions used to generate it. If the underlying understanding of the target phenomena is incomplete or flawed, those limitations will be present in the synthetic data and the systems built on it. Additionally, there is a risk that synthetic data might not capture unexpected correlations or subtle real-world patterns.
Synthetic data is only as reliable as the models and assumptions used to generate it.
These limitations emerge when deploying models trained on synthetic data. Sometimes the models perform well in controlled environments but struggle when confronted with the complexity of real-world data. For forecasting, real data wins if there is enough of it, it's readily available, compliant with regulations and is still relevant.
Simulating hypothetical scenarios, such as a new market segment, often lacks the relevant historical baseline data. That's where synthetic data shines. One effective approach is to train models on real data and then stress-test them using synthetic data. In this way, you can simulate an event such as a financial crisis, a weather disaster or a rare patient phenotype.
Some critics point out that overreliance on synthetic data creates a false sense of comfort. If they're making decisions that affect people's lives based on models trained on synthetic data, how can they be confident that those decisions are fair and reliable?
It's a valid concern. Real data offers authenticity and captures the complexity and nuance of the real world, including relationships and patterns that are difficult to anticipate. But real data comes with its own set of challenges. It's often incomplete, biased or carries significant privacy risks and regulatory burdens that synthetic data can help mitigate.
Use cases and industry patterns
Several industries already apply synthetic data in practical, domain-specific ways.
In finance, synthetic transaction data supports secure collaboration across institutions by enabling the exchange of modeled transaction data without exposing customer identities. This makes it possible to improve fraud detection models without relying on sensitive real-world records.
Using data in this way is not always easy. Synthetic data can replicate known fraud patterns, but generating novel behaviors is elusive. Still, teams find it useful for testing model sensitivity to threshold shifts or adversarial conditions.
In healthcare, synthetic data has significantly advanced AI development. Training models on synthetic patient records allows algorithm design without exposing personal health information. This approach accelerates innovation while maintaining patient privacy. Researchers have created synthetic CT scans and lab results for rare diseases to safely support pharmaceutical R&D.
In autonomous vehicle development, synthetic simulation data is invaluable for testing rare and dangerous scenarios such as crashes or reckless pedestrian behavior. These situations are critical to the safety of self-driving systems, but they are uncommon, and it would be unethical to recreate them. Synthetic simulations complemented with real-world testing ensure safety across diverse environments and conditions.
When to use what?
This table summarizes some common use decision points for choosing real or synthetic data:
Scenario
Synthetic data
Real data
Notes
Rare events/edge cases
Preferred: Generate thousands of edge cases quickly
Limited: Might take years to collect sufficient samples
Use synthetic to augment. Validate it on real samples when available.
Privacy-sensitive applications
Preferred: Regulatory compliance, data minimization
High risk: Personal information exposure, regulatory constraints
Document the synthetic generation process for audit trails.
System/pipeline testing
Preferred: Controlled, repeatable test scenarios
Risky: Might expose production data in test environments
Synthetic provides safe testing without production data access.
Model training (Initial)
Good: Rapid iteration, perfect labeling
Essential: Ground truth, real distributions
Start with real data understanding, augment with synthetic.
Model validation (Final)
Insufficient: Might miss real-world complexity
Required: The only way to verify actual performance
Never deploy without real data validation.
Dashboard prototyping
Preferred: No production access needed
Access constraints: Might delay development
Use synthetic for design, switch to real for go-live.
Regulatory submissions
Context-dependent: Thoroughly document your methodology
Preferred: Higher regulatory confidence
Hybrid approaches are often the strongest for compliance.
Integrating synthetic and real data
An effective method for using synthetic and real data together is through an iterative process. Begin with a reduced set of real data to generate synthetic records and train initial models. Then, validate those models on real data and refine the synthetic generation using improved results. This takes advantage of the strengths of both data types while mitigating their weaknesses.
Clear documentation is essential to track where and how synthetic data is used, particularly for high-stakes applications in finance or healthcare. Strong data provenance and transparency around its origin support ethical standards and regulatory compliance.
Equally important is the need for rigorous evaluation to determine how well synthetic data preserves statistical properties of the source data and whether it introduces any distortions.
Domain experts should play a central role in assessing synthetic data quality. Statistical similarity is insufficient: The data must make sense to a business expert.
Ultimately, choosing between synthetic or real data depends on the scenario being modelled and the development phase of the model or system. This table will clarify when to make certain choices during development.
Phase
Primary data source
Secondary source
Validation approach
Research/exploration
Real data
Synthetic for gap-filling
Statistical comparison of distributions
Initial development
Synthetic data
Real samples for reference
Periodic real data validation
System testing
Synthetic data
-
Controlled test case generation
Model training
Hybrid (real + synthetic)
-
Cross-validation on both sources
Preproduction validation
Real data (a subset, or hold-out set)
-
Performance metrics on real data only
Production monitoring
Real data
-
Continuous real-world performance tracking
Synthetic data and strategy
As AI demands more and more models of the real world, synthetic data has shifted from a data engineering technique to a strategic asset. It reflects how teams manage their privacy, time, budget and regulatory constraints.
Trade-offs remain. Synthetic data is not a perfect approach, but it has often been dismissed due to concerns around authenticity. Synthetic data is ultimately a tool. And like any tool, it's about using it for the right job at the right time.
The future of data in predictive analytics isn't synthetic or real; it's synthetic and real, working together intelligently.
Donald Farmer is a data strategist with 30+ years of experience, including as a product team leader at Microsoft and Qlik. He advises global clients on data, analytics, AI and innovation strategy, with expertise spanning from tech giants to startups. He lives in an experimental woodland home near Seattle.