
Getty Images
Self-service data preparation: What it is and how it helps users
Using self-service tools to properly prepare data simplifies analytics and visualization tasks for business users and speeds complex modeling processes for data scientists.

It's common in the fields of data science and data analytics to say that data preparation and processing make up 80% of the work involved. Why is so much effort required to prepare data before it can be analyzed?
Data in business applications is rarely stored in the right format for analysis. The point-of-sale system in the supermarket is optimized to check out what's in your cart and update the inventory system as efficiently as possible. It's not designed to deliver quarterly inventory reports and supply-chain predictions.
Equally important, data is rarely of the right quality for analysis. Some records have missing, incorrect or inconsistent values; they need to be fixed, and that process can be complicated. You also don't want data analysis slowing down your operational systems, so you need to move the data to a new location for analytics and reporting -- frequently shaping it, combining it and applying data quality operations on the way.
For all these reasons, data preparation is an important -- and, indeed, inevitable -- step in analytics applications. In fact, I often say that data preparation is data analysis in a significant sense, because you need to know how you'll use the data to know how to prepare it. Most often, it isn't IT that really understands these use cases, rather it's business users or data scientists. And now, there are tools they can use to do self-service data preparation.
What is self-service data preparation?
Even in the recent past, data analysis was the domain of specialists, typically within IT teams, because only experts could handle the complexities of running complicated calculations and selecting the right data visualizations and outputs. Data preparation also was a specialized task with its own complexities in combining, cleansing and optimizing data sets.
In recent years, the practice of analytics has greatly advanced, and now business users have excellent, relatively simple tools for analysis, visualization, reporting and data storytelling. They must be experts in business, but much of the technical burden is now handled by smarter BI applications.
As business users have become familiar with self-service BI and analytics, they also want to work directly with the data. If you can build your own visualizations, reports and dashboards, it's a barrier to your productivity if you always have to ask the IT or data management team for more data organized and formatted the way you want it.
Data scientists are in a similar situation, but with some differences. They also need to get data out of operational systems and into a suitable location for machine learning, predictive modeling and other advanced analytics. They need to tidy up data records, too, but they may find some of the inconsistencies useful -- say for fraud analysis. They also need the data to be in the right shape for their algorithms to work on, which may mean collecting it all into one very large table. They typically want to do all these things themselves.
Self-service data preparation makes that possible for data scientists and business users, enabling them to do the work of sourcing data, shaping it and cleaning it up, frequently from simple-to-use desktop or cloud applications.
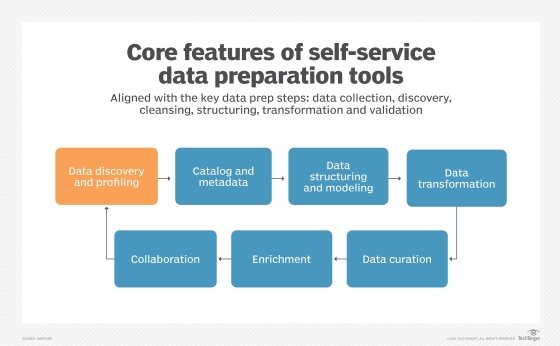
How self-service data preparation works
In many ways, the process of self-service data preparation is the same as traditional IT-driven data prep processes. Following are six somewhat simplified steps:
- Collecting data. When IT does data preparation work, it may gather data from all over the enterprise, often using specialized connectors and "inside knowledge" of database technologies. Business users most likely connect to familiar applications using simplified connectors built into their self-service data preparation platform.
- Profiling data. To work effectively with the data you collect, you need to preview it and see how complete and accurate it is. Self-service tools typically include data profiling capabilities that also provide statistical information about ranges of values, outliers, errors and other data attributes and issues.
- Joining data. When you need to analyze data from different data sets, or from different tables in one data set, you must first join the data. The logic and code for performing joins is still a favorite question in technical exams for database programmers. But self-service tools help you here, often making joins as simple as a drag-and-drop procedure.
- Cleansing data. Your data is rarely immediately good enough for analysis. You may need to add defaults for missing values or conform different formats to the same pattern, such as a standard country code. Increasingly, data preparation tools offer excellent data quality features. Others may include simpler capabilities with integrations to specialized data quality services.
- Transforming data. I mentioned before that data needs to be in the right shape for analysis. For example, there's a significant difference between the very flat structures that data scientists use and the very hierarchical ones used by financial analysts. This shaping is an important element of data transformation, which also involves putting data into the right format for the final step.
- Storing the prepared data. With all this work done, the data needs to go somewhere for future use. Common targets include data warehouses and data lakes, where you can make it available to other users, too. You also might store the data in a system specific to your preferred BI and data visualization tool. Or you could just save it locally for your own use.
Good self-service data preparation tools include features that support all these steps, even if the flow of the data prep process is a little different in some of them.

Self-service data preparation's benefits
The advantages of self-service data preparation can be classified into the following three categories:
- It enables business users and data scientists to be more agile and efficient, by giving them simplified tools to do traditionally complex work on their own. That saves them from time-consuming processes in which the IT team gathers requirements, builds and tests prototypes, gets feedback and so on.
- Enabling analytics users to do their own data preparation work also frees up IT and data management resources for more productive tasks.
- The self-service approach enables data preparation work to be distributed more widely throughout an organization and its IT infrastructure, avoiding bottlenecks and building in resilience.
A good example of these benefits in action would be when marketing teams need to respond to significant changes in the business environment. We have all seen this with the COVID-19 pandemic. After the virus outbreak, many retailers wanted to link customer data from physical locations with online activity and local data about COVID-19 cases. They wanted to ask simple questions with difficult answers, like what foot traffic they could still expect and how much business might move to the web.
Most often, these data sets did not exist, because this scenario was very new. IT teams -- struggling with their own new challenges at the time -- could have taken weeks to prepare the data, even if they could prioritize that work. But through self-service data preparation, marketing teams could easily source internal and external data sets, join them, and clean and transform them as needed. This acceleration of analytics proved to be critical for organizations in responding to the pandemic.
These specific advantages are compelling, but many businesses find the final benefit of self-service data preparation the most important, even if it's the most difficult to quantify. The increased efficiency for users makes them more able, and more likely, to explore new scenarios and test out innovative ways of analyzing business operations. The ultimate benefit of self-service data preparation is an enterprise more connected to, and more informed by, its business data.
Self-service data prep vs. ETL and data science pipelines
Self-service data preparation tools aren't the only game in town, of course. There are still well-established applications designed for IT -- primarily extract, transform and load (ETL) tools. Other data preparation technologies are available to data scientists. How do they all compare?
The first, and most important, distinction is simplicity and usability. Self-service tools are built for non-specialists. They may require some training -- and certainly reward some study and practice -- but they are specifically designed to get users started quickly.
ETL is a heavyweight data integration technology designed to move large volumes of data between databases while shaping and cleaning it during data movement. ETL tools can be configured to take advantage of the most advanced features of databases, and they include advanced capabilities for error handling and creating complex logic. Even though the tools are easier to use, ETL work is often a specialized job, especially in large enterprises.
While data scientists use self-service data preparation tools in some applications, many do much of their work in scripting languages, such as Python and R. Most often, they develop not just one script but a sequence of related scripts with complicated dependencies between them. Coordinating the scripts creates a data science pipeline that applies a set of actions to a data set. While building such pipelines is also becoming easier thanks to new tools, it remains a specialized option for data science work.
For simpler data science scenarios, and for business users who regularly need to analyze data and create visualizations and reports, self-service data preparation is an increasingly essential capability. They know all too well that data is rarely perfect for the task at hand -- and they're the ones best positioned to make it fit for the intended purpose.






