What is data cleansing (data cleaning, data scrubbing)?
Data cleansing, also referred to as data cleaning or data scrubbing, is the process of fixing incorrect, incomplete, duplicate or otherwise erroneous data in a data set. It involves identifying data errors and then changing, updating or removing data to correct them. Data cleansing improves data quality and helps provide more accurate, consistent and reliable information for decision-making in an organization.
Data cleansing is a key part of the overall data management process and one of the core components of data preparation work that readies data sets for use in business intelligence (BI), machine learning (ML), artificial intelligence and other data science or analytical applications. Data quality analysts and engineers or other data management professionals typically do this work. But data scientists, BI analysts and business users also clean data or participate in the data cleansing process for their own applications.
Data cleansing vs. data cleaning vs. data scrubbing
Data cleansing, data cleaning and data scrubbing are often used interchangeably. For the most part, they're considered the same thing but can have more specific goals in the data management or quality process.
Data scrubbing is a subset of data cleansing that involves removing duplicate, bad, unneeded or old data from data sets. For example, a data set might be scrubbed to remove data elements or records that have aged out of the organization's accepted data retention period.
Data scrubbing has a different meaning in connection with data storage. In that context, it's an automated function that checks disk drives and storage systems to make sure the data they contain can be read and to identify any bad sectors or blocks.
Similarly, data cleaning is another subset of data cleansing that focuses on correcting errors and inconsistencies in the data set. For example, if a customer identifies an error in their account, such as an incorrect address or other personally identifiable information, a routine data cleaning process can update or correct the data deficiencies.
Why is clean data important?
The classic computer science idiom, garbage in, garbage out, applies particularly well to data quality and analytics. The outcome of a data analytics process cannot be better than the data used. Although perfect data doesn't guarantee accurate outcomes from the analytics process, incomplete, inaccurate or flawed data will absolutely prevent accurate results or conclusions from analytics, ML model training and other data-driven processes.
Business operations and decision-making are increasingly dependent on data, as organizations look to use data analytics to help improve business performance and gain competitive advantages over rivals. As a result, clean data is a must for BI and data science teams, business executives, marketing managers, sales reps and operational workers. That's particularly true in retail, healthcare, financial services and other data-intensive industries, but it also applies to organizations across the board, both large and small.
If data isn't properly cleansed, customer records and other business data might not be accurate, and analytics applications could provide faulty information. That can lead to flawed business decisions, misguided strategies, missed opportunities and operational problems that could increase costs and reduce revenue and profits. Gartner research notes that poor data quality costs organizations an average of $12.9 million per year, though the long-term effects of erroneous strategies and decision-making can compound short-term losses.
What kind of data errors does data scrubbing fix?
Data cleansing addresses a range of errors and issues in data sets, including inaccurate, invalid, incompatible, corrupt and incomplete data. Human errors during the data entry process causes some types of data problems. Others result from the use of different data structures, formats and terminology in different systems throughout an organization.
For example, the process of exchanging data sets between two dissimilar systems or processing applications can introduce data issues because of improper data translations or incorrect mathematical processes such as data normalization. The types of issues that are commonly fixed as part of data cleansing projects include the following:
- Typos and invalid or missing data. Data cleansing corrects various structural errors in data sets. These include misspellings and other typographical errors, wrong numerical entries, syntax errors and missing values, such as blank or null fields that should contain data.
- Data validation. Simply having data doesn't guarantee its accuracy or completeness. Data validation is an essential data cleansing process that looks at accuracy, completeness, scale and other data quality criteria.
- Data enrichment. Improving data through enrichment can add valuable and relevant information that enhances the quality and usability of data. In some cases, these efforts might be directed at supporting metadata, such as tags and classifications, that can benefit analytics later.
- Inconsistent data. Names, addresses and other attributes are often formatted differently from system to system. For example, one data set might include a customer's middle initial, while another doesn't. Data elements such as terms and identifiers can also vary. Data cleansing helps ensure that data is standardized and consistent so it can be analyzed accurately.
- Data type conversions. A variation of data consistency, type conversions ensure consistent formatting and content is used within the data set. For example, if the data is supposed to contain only numbers, any text entries would get deleted or remediated appropriately.
- Duplicate data. Data cleansing often uses an algorithm to identify duplicate records in data sets and either removes or merges them through the use of deduplication measures. For example, when data from two systems is combined, duplicate data entries can be reconciled to create single records.
- Data normalization. Normalization ensures that data elements follow a similar or uniform scale or format. For example, consider two data sets containing temperature data. If one data set is in degrees Fahrenheit and another data set is in Celsius, normalization would perform conversions so that both sets use the same scale.
- Irrelevant data. Some data, such as outliers and out-of-date entries, aren't relevant to analytics applications and can skew their results. Data cleansing removes redundant data from data sets, which streamlines data preparation and reduces the required amount of data processing and storage resources. Outlier removal can prevent data points that might skew results.

Characteristics of clean data
Various characteristics and attributes are used to measure the cleanliness and overall quality of data sets, including accuracy, completeness and consistency, as well as data integrity, reliability, timeliness, uniformity, uniqueness and validity.
Data management teams create data quality metrics to track those characteristics, as well as things like error rates and the overall number of errors in data sets. Data managers use surveys and interviews with business executives, among other tools, to try to calculate the business impact of data quality problems and the potential business value of fixing them.
The benefits of effective data cleansing
Done well, data cleansing provides the following business and data management benefits:

- Improved decision-making. With more accurate data, analytics applications can produce better results. That helps organizations make informed decisions on business strategies and operations, as well as things like patient care and government programs.
- More effective marketing and sales. Customer data is often wrong, inconsistent or out of date. Cleaning up the data in customer relationship management and sales systems helps improve the effectiveness of marketing campaigns and sales efforts. This can also translate into improved customer experience.
- Better operational performance. Clean, high-quality data helps organizations avoid inventory shortages, delivery snafus and other business problems that can result in higher costs, lower revenue and damaged relationships with customers.
- Increased use of data. Data has become a key corporate asset, but it can't generate business value if it isn't used. By making data more trustworthy, data cleansing helps convince business managers and workers to rely on it as part of their jobs.
- Reduced data costs. Data cleansing stops errors and issues from propagating in systems and analytics applications. In the long term, that saves time and money, because IT and data management teams don't have to continue fixing the same errors in data sets.
- Effective data governance. Data cleansing and other data quality methods are a key part of data governance programs that ensure data is consistent, free of bias and used in accordance with business policy. Clean data is a hallmark of a successful data governance initiative and is essential to meet prevailing regulatory compliance requirements, depending on the business and industry.
Data cleansing challenges
Data cleansing doesn't lack challenges. It's often time-consuming, due to the number of issues that must be addressed in many data sets and the difficulty of pinpointing the causes of some errors. Other common challenges include the following:
- Deciding how to resolve missing or deleted data values so they don't affect analytics applications.
- Deciding how to resolve incorrect data values because good data must not include bad or incorrect data.
- Identifying weak points or secondary causes, such as data errors in outside data that's acquired or purchased.
- Fixing inconsistent data in systems or data sources controlled by other business units.
- Cleaning up data quality issues in big data systems that contain a mix of structured, semistructured and unstructured data.
- Establishing a regular schedule and useful tools to ensure timely and efficient data cleansing tasks.
- Getting sufficient resources and organizational support.
- Dealing with data silos that complicate the data cleansing process.
How to conduct data cleansing at your organization
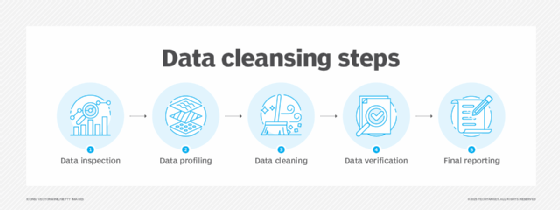
The scope of data cleansing work varies depending on the data set and analytics requirements. For example, a data scientist doing fraud detection analysis on credit card transaction data may want to retain outlier values because they could be a sign of fraudulent purchases. The data scrubbing process typically includes the following actions:
- Inspection and profiling. First, data is inspected and audited to assess its quality level and identify issues that need to be fixed. This step usually involves data profiling, which documents relationships between data elements, checks data quality and gathers statistics on data sets to help find errors, discrepancies and other problems.
- Cleaning. This is the heart of the cleansing process, when data errors are corrected or normalized, and inconsistent, duplicate and redundant data is addressed. Original data sets can be backed up or retained for a period to ensure that cleansing tasks don't adversely or unexpectedly affect data.
- Verification. After the cleaning step is completed, the person or team that did the work inspects the data again to verify its cleanliness and make sure it conforms to internal data quality rules and standards.
- Reporting. The results of the data cleansing work should then be reported to IT and business executives to highlight data quality trends and progress. The report could include the number of issues found and corrected, plus updated metrics on the data's quality levels.
The cleansed data is then moved into the remaining stages of the data preparation workflow. This process starts with data structuring and data transformation, to continue preparing it for various data analysis and analytics uses.
Data cleansing tools and vendors
Numerous tools can be used to automate data cleansing tasks, including both commercial software and open source technologies. The tools include a variety of functions for correcting data errors and issues, such as adding missing values, replacing null values, fixing punctuation, standardizing fields and combining duplicate records. Many tools also do data matching to find duplicate or related records.
Tools that help cleanse data are available in a variety of products and platforms, including the following:
- Specialized data cleaning tools from vendors such as Data Ladder, Drake, Quadient Data Cleaner, Validity DemandTools and WinPure.
- Data quality software from vendors such as Datactics, Experian, Innovative Systems, Melissa, Microsoft Purview and Precisely.
- Data preparation tools from vendors such as Altair, Alteryx Designer Cloud (formerly Trifacta), DataRobot, Tableau and Tibco Software.
- Data management platforms from vendors such as Alteryx, Ataccama, IBM InfoSphere Quality Stage, Informatica, SAP, SAS, Syniti and Talend.
- Customer and contact data management software from vendors such as Redpoint Global, Tye and ZoomInfo.
- Tools for cleansing data in Salesforce systems from vendors such as Cloudingo and Plauti.
- Open source tools such as DataCleaner and OpenRefine.
Data can be a burden or an advantage. Learn how to improve data management, break down data silos and invest in analytics to build a data-driven culture.
Continue Reading About What is data cleansing (data cleaning, data scrubbing)?
Dig Deeper on Data governance
-
![]()
7 challenges, best practices for ERP data migration
By: James Kofalt
-
![]()
GreenOps – Astronomer: Workflow orchestration is the hygiene layer a data team needs
By: Adrian Bridgwater
-
![]()
What is data quality and why is it important?
By: Scott Robinson
-
![]()
Top data quality management tools in 2025
By: Robert Sheldon



