6 data preparation best practices for analytics applications
Analytics applications need clean data to produce actionable insights. Six data preparation best practices can turn your messy data into high-quality fuel for analytics operations.

I don't relish being the bearer of bad news, nor can I claim clairvoyance. But I can say this with some confidence: Your analytics data is a mess.
How do I know? Partly from experience, but mostly because that's the nature of enterprise data. The inherent messiness makes effective data preparation a crucial part of analytics applications.
What is data preparation?
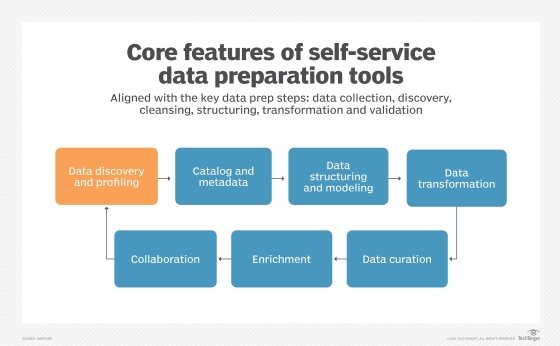
Enterprise data operations need clean data to function. Data preparation is the first step to ensure clean, accurate and complete data sets. Data preparation takes place over six steps that profile, cleanse, transform and validate data:
- Data collection. Gather relevant data from various sources including data warehouses, lakes and operational systems.
- Data discovery and profiling. Analyze the data's quality and identify any relationships and connections between data points. Profiling can highlight quality issues such as inconsistencies, anomalies and missing values.
- Data cleansing. Fix any errors identified in the previous step.
- Data structuring. Organize the data into the format it needs to fit your database.
- Data transformation. New data sets might not fit your existing schema. Transforming the data into a usable format might require new columns or tables in your existing database.
- Data validation. Check the data for consistency, completeness and accuracy.
Why data preparation is so important
Enterprise software applications save data in a form that is most suitable for their own purpose, not for your analytics needs. For example, data in a CRM system is oriented to customer management, whereas data in an accounting system is optimized for accounting, and data in an HR system has its own structure. If you want to analyze your business operations across these data silos, you're going to find the process far more complex and frustrating than you first thought it would be.
Even within a single data source, some of the information is irregular, which is why you often get multiple pieces of direct mail from a company addressed to slightly different versions of your name. Similarly, data might be out of date; it's hard work to keep abreast of all the changes in any business. You'll also find that data is inconsistent across different data sources and sometimes just plain wrong.
Even good data is often in the wrong shape for different use cases. What does that mean? Think of a spreadsheet and its rows and columns of data. Most business intelligence and reporting tools can use data in that format, but some data isn't structured that way. A lot of enterprise data has nested structures that contain a key record with multiple records of different types under it. You might need to flatten that out to look more like a spreadsheet so certain tools can use the data.
6 data preparation best practices
These kinds of issues underline why data preparation best practices are critical. They also illustrate why many data professionals say data preparation can take 60% to 80% of all the work done in data analysis. That naturally leads to the first of six best practices: Don't think data preparation comes before you start analyzing.
1. Data preparation is data analysis
I wish I could give you a simple formula for data quality to answer all the questions about the consistency, accuracy and shape of data sets. But the only sensible definition of good data is whether it's fit for the intended purpose. Why? Because different purposes have different requirements.
I once worked on an analytics project involving credit card transactions for the sales team of a major bank. They were designing new card products for different demographics and wanted to analyze card usage. In the mass of credit card processing data, there were many failed transactions for different reasons, such as credit limits or because the card couldn't be read properly. Often, in the days of dial-up connections, we found simple technical failures.
All the failed transactions got in the way of creating a clean data set for the sales team. We built a rather complex data preparation process to clean it all up. A few months later, the fraud analysis team said they would love to use this new data warehouse. Unfortunately, they needed to see all the failed transactions we had spent weeks of work and hours of processing to clean out of the system. The data that was good for one purpose was entirely unsuitable for another.
That's one reason why data preparation should be regarded as part of the analytics process. You must understand the use case to know what data will fit your purpose. You can't prepare a data set without knowing what you want to achieve. Data preparation and data analysis are simply two sides of the same coin.
2. Define successful data preparation
Acceptable data quality metrics are an important part of documenting the analytics use case in advance of designing your data preparation pipeline. For example, an inside sales team working the phones would be unhappy with a data set that doesn't include accurate contact numbers for all their prospects. A marketing team, on the other hand, might be content with a relatively low percentage of complete records if they don't plan to do telephone marketing.
A higher metric on data quality isn't always better. That's partly because use cases vary so much but also because of the cost to prepare data, including design and runtime, is high. Be careful to prepare data appropriately for each use case.
Useful metrics to gauge the success of a data preparation initiative include data accuracy, completeness, consistency, duplicates and timeliness.
3. Prioritize data sources based on the use case
As you bring data together from multiple sources, you'll quickly realize that not all systems are equal. Some might have more complete data, some more consistent and some might have records that are more up to date.
An important part of the data preparation process is deciding how to resolve differences among data sources. That also depends on the use case. Some examples include the following:
- If I'm preparing data for sales analytics, I might prioritize data from the CRM system where salespeople enter customer records and should know what they need in terms of quality.
- For a data science project, I'm likely to prioritize data that has a fine degree of detail because data scientists like to run raw detailed data through analytics algorithms to identify interesting patterns.
- When working on a formal management reporting project, I prefer data from systems with strict governance and control measures rather than a more open application.
Prioritizing sources is therefore a critical component of data preparation best practices. But working out the rules by which conflicting sources contribute to the final data set is not always easy to do in advance. Frequently, you must tag some data that might be correct but needs further review.
4. Use the right tools for the job
There are a wide variety of data preparation tools available, depending on your experience, skills and needs.
If your data is stored in a standard relational database or a data warehouse, you might use SQL queries to extract and shape data and, even to a certain extent, apply defaults and some basic data quality rules. But SQL queries are not best suited for the sort of row-by-row, step-based data preparation that's sometimes required, especially when there's a wide range of potential errors in specific ways. In that case, extract, transform and load (ETL) tools are much better suited. Indeed, ETL tools remain the enterprise standard for IT-driven data integration and preparation.
Data preparation tools might also be available in BI software, but they're designed specifically for the BI vendor's use cases and might not work well for more general applications. In addition, there are standalone self-service data preparation tools that enable business users to work on their own without extensive IT support. Self-service tools are more general-purpose and typically include capabilities for shaping data and executing jobs on a schedule. They can be an excellent choice for business users who frequently prepare data not just for their own use but also for others' uses.
Data scientists often have specialized needs to prepare data for algorithms or analytical modeling techniques. For those scenarios, they typically use scripting or statistical languages such as Python and R that offer advanced functions such as categorization and matrix transformations for data science. For simpler scenarios, data scientists might also use self-service data preparation tools.
The most familiar and common data preparation tool -- if not the most appreciated -- is Excel. But for all its convenience, flexibility and ease of use, Excel doesn't suit enterprise data preparation. Excel workbooks make it difficult to audit and log data as well as govern and secure it in accordance with enterprise data standards.
5. Prepare for failures during the preparation process
One advantage of ETL tools is the way they handle complex processes. When a tool finds a specific type of error in a record, it can move such records individually to secondary workflows that attempt to fix the error and bring the record back into the regular flow. If the record can't be fixed, the system might write it out to a special table for human review.
This kind of error handling is important in data preparation because errors occur quite frequently. Yet the entire process shouldn't fail because of one bad record.
You can use the features in specialized tools to design error handling, or you can do the work manually. You can also implement some useful error handling using general-purpose workflow and scheduling tools. No matter the approach, you must design a process that allows for failure and enables you to restart after a failure while carefully logging all the errors and corrections that might have occurred.
6. Keep an eye on costs
Data preparation can require as much as 80% of the time spent on an analytics project, with the implication that it can also prove to be expensive. Be aware of the following costs:
- License fees. Specialized data preparation software can be costly, especially those that are designed to process huge volumes of data efficiently and accurately. Data quality tools can also be expensive because of the painstaking updates needed to reference data sets for address cleansing, company names and so on. If you are using SQL or Excel, you might already have the licenses included in other packages. Keep in mind that these tools don't afford the scalability, capabilities and features of more advanced technologies.
- Compute costs. If your data preparation processes are complex, they'll require considerable compute costs when deployed in the cloud. Data engineers often need to tune the workflows and pipelines of data scientists to reduce compute costs. Beware of running data preparation tasks that look at every record in the system every time. That's wasteful and rarely needed. Incremental processing is an important capability to select as a feature or manually design in.
- Storage costs. Many data preparation processes use surprising amounts of storage as temporary files or staging areas for source data and partially processed data sets. Error handling, logging and archiving can also increase storage significantly. Even though data storage is relatively cheap these days, watch it closely.
- Human costs. As in every field, there are specialists in data preparation, and you might find that your processes grow enough in scale and complexity to require that kind of role. If BI users are mostly doing their own self-service data preparation, you might think the human costs can be discounted from or absorbed into the overall project cost. Yet there's also an opportunity cost to consider. Every hour spent preparing data could be spent on something else, so involving data analysts and business users in the preparation process could prove wasteful.
Preparing for data preparation
Data preparation can seem complicated and highly technical. Tools can help greatly, especially with building large-scale or complex data preparation processes. More importantly, a careful and practical mindset can take you a long way, supported by the six best practices, including a clear definition of data quality and a strong business sense of how the data will be used. That's how to prepare for data preparation.
Editor's note: This article was originally published in 2022. TechTarget editors revised it in November 2024 to improve the reader experience.
Donald Farmer is a data strategist with 30-plus years of experience, including as a product team leader at Microsoft and Qlik. He advises global clients on data, analytics, AI and innovation strategy, with expertise spanning from tech giants to startups. He lives in an experimental woodland home near Seattle.







