structured data

What is structured data?
Structured data is data that has been organized into a formatted repository, typically a database. This is done so the data's elements can be made addressable for more effective processing and analysis. The data resides in a fixed field within a record or file.
Structured data contrasts with unstructured and semi-structured data. The three types of data exist on a continuum, with unstructured data being the least formatted and structured data being the most formatted. The more structured a set of data is, the more amenable to processing and analysis it is.
How does structured data work?
Structured data needs a data model and data repository, which is usually a database. A data model organizes elements of data and defines how they relate to one another. For example, a data model might specify that the data element representing a customer in a database contain several smaller elements or attributes that represent specific customer information. Examples of structured data in this scenario include a person's name, phone number, address and ZIP code.
The structure of the data might be enforced. For example, the ZIP code field might only accept numeric data that is five characters long. This maintains the integrity of the data, while preventing data that doesn't fit this description from being entered into the schema. The nature of structured data is that it can be logically grouped by similar values and constraints.
Data is defined narrowly by these constraints and written to defined slots in a data repository. For instance, in a database, each field in a record is discrete, and its information can be retrieved either on its own or along with data from other fields, in a various combination.
Databases make data more comprehensive so that it yields useful information. Structured data might also be stored in rows and columns in a relational database, which links tables of data together so they can be tapped by a broader set of search criteria to return more detailed information.
A database query language, such as structured query language (SQL), lets a database administrator interact with and manipulate the data in the database. Extract, transform and load (ETL) processes are sometimes used to integrate different structured databases into a data warehouse.
Benefits and drawbacks of structured data
There are many benefits to using structured data, including:
- Storage. Because structured data is predefined within a series of constraints, it is easier to organize and store, especially in comparison to unstructured data.
- Security. Narrow constraints make structured data easier to secure. Good data security requires data classification, which is facilitated when data falls into a ready-made data structure.
- Data analysis. When there is more descriptive information attached to data, it's easier to process, analyze and draw inferences from it.
- Easy to understand. Narrow constraints allow data to be quickly understood and used. Business users can read and understand structured data without needing to know a great deal about data formatting and databases.
There are also drawbacks to structured data, such as:
- Rigid schema. Structured data must conform to a schema that dictates a predefined purpose. This approach can limit how the data is used. Data that does not conform to a particular schema might not be able to be processed in a structured database.
- Missing data. Because data must adhere to certain data format, businesses might miss out on unstructured data that could improve decision-making.
- Underrepresented. Modern devices generate a lot of unstructured and semi-structured data. Businesses must find a way to use this data, which might not fit neatly into a predetermined schema. If businesses only focus on collecting and processing structured data, they will not be able to capitalize on the full range of opportunity that internet of things devices and big data offer.
Use cases for structured data
Some common examples of how structured data is used include:
- Search engine optimization tool. For search engines, website owners can edit their site's HTML to describe their webpage using a series of HTML tags, called microdata. Marking up a website with microdata tags helps search engines understand the website better and makes it more likely to appear in search results. Schema.org is a community that creates, maintains and promotes shared vocabularies of microdata that can be used to mark up webpages. In this context, structured data is functioning like metadata.
- Machine learning algorithm training. Programmers use structured data to write and augment machine learning algorithms that use supervised learning. In supervised learning, machines are trained using well-labeled training data; structured data tends to apply more easily to the machine's rules.
- Data management. Business intelligence software might use SQL databases or Excel files to track basic data such as customer contact information, account credentials and financial transactions. Some tools used to store structured data include online analytical processing, MySQL and PostgreSQL.
- ETL. This process involves extracting data from original data sources, transforming it by cleaning it up and then loading it into a larger data repository such as a data warehouse.
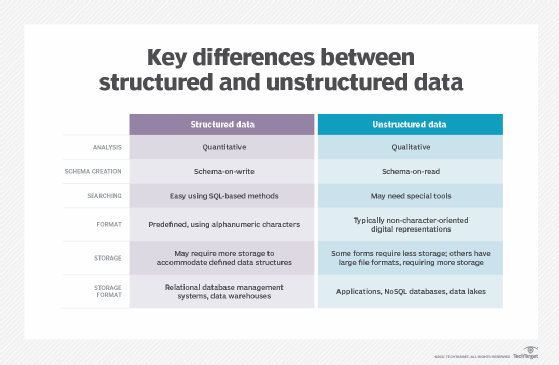
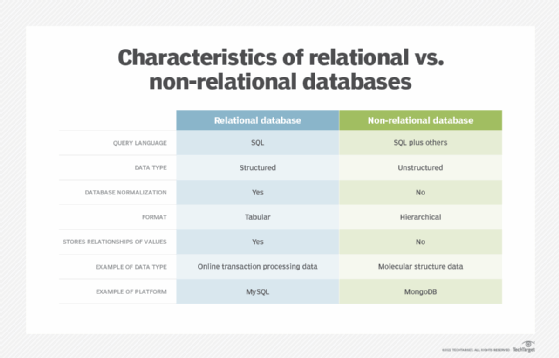
Structured vs. unstructured data
There are several key differences between unstructured and structured data. Whereas structured data is highly specific and conforms to a predefined data model, unstructured data does not. Unstructured data is generally stored in its native format. It is more plentiful and flexible than structured data, but it is harder to manipulate and often requires more advanced methods and data science techniques to do so.
Examples of unstructured data include social media posts; IoT remote sensor data; rich media, such as images, video and audio; and webpages. Unstructured data is often stored in data lakes.
When the HTML microdata function is used as an SEO tool, it helps provide structure to the otherwise unstructured data of webpages.
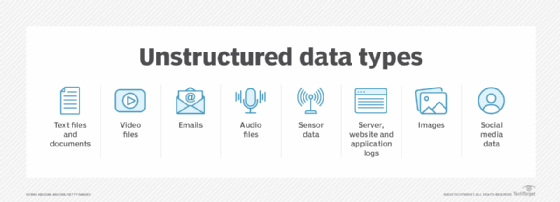
Data lake governance can be difficult because of the sheer amount of unstructured data stored. Learn some governance principles and best practices to keep a data lake from becoming a data swamp.