Structured vs. unstructured data: The key differences
Structured and unstructured data pose unique challenges when it comes to categorizing, defining and storing data. Check out the differences and where semistructured data fits in.
The two main types of data are structured and unstructured. Structured data is typically alphanumeric, easy to categorize based on shared traits of data points and suitable to store in a predefined data model, such as a database. Unstructured data is usually something other than an alphanumeric representation; it doesn't fit neatly into a defined, uniform framework; and is often stored in its native format.
The term data embraces nearly anything that can be expressed or represented in digital form. To some degree, the type of data doesn't matter as much as the context in which it is viewed and its relationships with other bits of data. Context and relationships help turn raw data into useful information.
The ability to manipulate data depends largely on how we classify data elements so that we can see how they relate to broader data sets and the commonalities they have. Data classification enables clusters of data to be searched to discover specific instances that match search criteria.
To achieve all of that requires building uniform structures to hold or define data in a consistent manner -- hence the term structured data. But dealing with data isn't always straightforward, as anyone who has tried to make sense of a massive amount of data will attest. Not all data lends itself to being defined and classified, and that can cause issues.
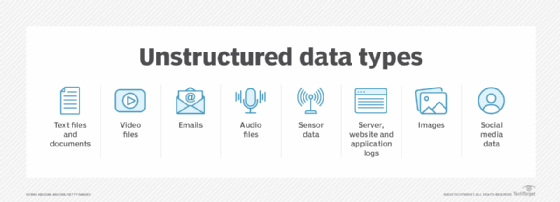
Today, data is usually much more than an alphanumeric representation of something. It can be video, audio or document files; social media jottings; or email content. These unstructured data types don't fit neatly into a defined framework and are rapidly becoming the dominant types of data in the enterprise.
To further complicate matters, it's sometimes necessary to combine structured and unstructured data to derive the desired information. This hybrid approach represents a third general data type -- called semistructured data -- which is possibly the fastest growing of all three categories.
What is structured data?
Structured data is data that, because of what it represents and its format, can be categorized, defined and stored in a consistent structure, such as a database management system (DBMS).
The individual data elements of structured data can be constructed in a way that will conform to standard constraints, such as the following:
Made up of text, numeric or alphanumeric data.
The number of characters constituting the element.
The nature of the data elements that enables them to be logically grouped based on their similar or like values.
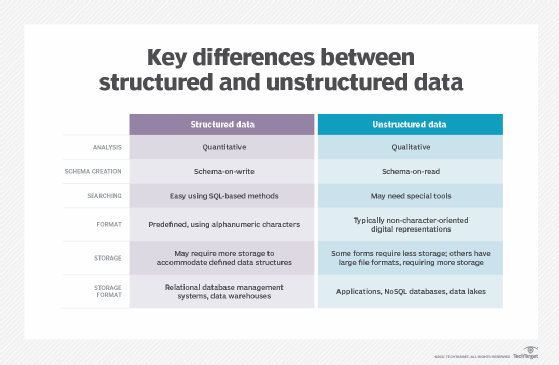
Placing data into the structured environments is sometimes referred to as schema-on-write, meaning data is newly written to or moved to specifically defined slots in a data repository. The definitions are typically narrow to ensure that only like data will be written to the appropriate place in the schema.
For example, a ZIP code field may be defined as being numeric and five characters long, thus preventing any data that doesn't meet those two criteria from being written to that structure. Additional safeguards against spurious data can be put in place by applying filters that further specify an appropriate entry, such as barring a range of ZIP codes that begin with "900."
Another way to ensure that entries conform to a single format is to provide a template for entries. The template effectively forces each entry to appear in a uniform format that facilitates searches. For example, a template for Social Security numbers may force entries to be made in this format: ###-##-####.
The ability to group data in this manner makes searching for specific instances of data easy because of the uniformity with which the data is stored. A database of addresses may have the following standard defined fields:
first and last name
street address
city
state
ZIP code
To find and extract only the residents of Oregon from the database, you could search the ZIP code field for all entries that begin with "97."
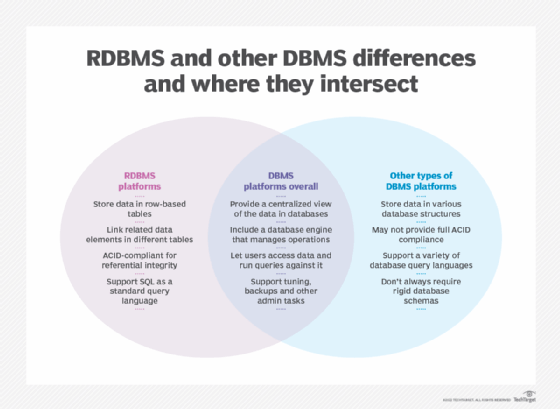
For more sophisticated data manipulation, a relational DBMS (RDBMS) makes it possible to set up relationships between two or more different sets of mostly unlike data. The different data sets within a relational database are called tables; within the tables are collections of data arranged in columns (fields) and rows (records or data entries). By associating a like column or field that appears in both tables, the data can effectively be combined to yield even more information.
For example, if the database of addresses was one table and a second table was a list of students with their major courses of study and hometowns, a new set of data could be extracted that showed the distribution of a majors in a specific state.
SQL facilitates the extraction and compilation of data from a group of tables. SQL established a standard set of commands to access, find and assemble data into meaningful forms.
In some cases, relational or nonrelational databases may include a column that points to an unstructured data element, such as a video file. This unstructured data element is called a blob, or binary large object. In most cases, the BLOB is linked to the other information in the data row so it can be located by searching on other data elements within the record. The BLOB itself typically is not searchable except possibly by its name or data type -- for instance, MP4, MOV or WMV for video files.
The similarities and differences between DBMS and RDBMS
What is unstructured data?
As mentioned earlier, unstructured data encompasses things like video, audio and document files; social media posts; and email content. It defies easy standardization and categorization. It often resembles collections of data rather than discrete data elements, such as a document comprising hundreds or thousands of words and addressing many different topics. At best, it's difficult to define the contents of the document as a single entity, and structured data tools don't offer any mechanisms to parse through the document to enable categorization of the data it includes.
New sources of data, such as IoT sensors, satellite imagery, drone-captured data, security cameras and voice recording systems, are producing enormous quantities of unstructured data every day.
Unstructured data can be managed, but it is usually stored as an object in its original, raw format and only manipulated when it is needed. That process is called schema-on-read, which refers to an approach to data analysis used in newer data management tools, such as Hadoop, that applies structure to the data when it is read.
Metadata is used to categorize unstructured data. The metadata accompanies the object, providing a limited amount of standard information about it that can be used as search and sorting criteria. But metadata is generally limited to basic information about the file, such as when it was created and modified, its size and the file type.
There are also tools that can scan unstructured data, such as audio or video files, and extract information such as locations or spoken phrases that can be used as additional metadata. Similarly, technologies such as XML -- extensible markup language -- can add some structure to textual files.
While extracting or associating specific information from unstructured data is difficult, methods to do this are urgently needed. It's estimated that 80% of the data organizations create or collect is unstructured. New sources of data, such as IoT sensors, satellite imagery, drone-captured data, security cameras and voice recording systems, are producing enormous quantities of unstructured data every day. These huge volumes are straining storage systems, so many organizations use cloud storage services to store their unstructured data.
Unstructured data is coming from all sorts of sources, IoT sensors and social media being the newest.
Semistructured data
As its name implies, semistructured data is a body of data that combines both structured and unstructured data or, more likely, unstructured data to which some structure has been added to make it more accessible.
In a simple form, semistructured data may be a video file that is accompanied by structured data that provides greater definition to the file, such as topics, location, date, participants, length and format. Any of those pieces of information can then be used to locate or group specific videos.
More on IoT and unstructured data
IoT sensors and devices are bringing massive amounts of unstructured data into the enterprise. Find out about the various challenges this is raising, particularly in terms of storage.
A big data, IoT project brings unique storage demands
Six reasons IoT storage should be object-based
Structured vs. unstructured data: Key differences
The differences between structured and unstructured data are profound, but both types provide important information for organizations. As noted, there's far more variety in unstructured data, and the analytics tools used to manipulate unstructured data are likely to be newer and produce information that is less literal than the systems that process structured data.
For example, a supermarket can use a relational database to associate what a customer buys with that customer's loyalty program ID to produce coupons for items that the data suggests the customer is likely to buy. An analysis of unstructured data in a retail environment might use video data noting the aisles a customer visits and how long they linger in certain areas, as well as the sequence of movements. Based on the information collected, the system may then instantly produce a coupon for milk after a customer passes through the coffee aisle and approaches the dairy case.
Key areas of differentiation between structured and unstructured data include the type of analysis, schema used, type of format and various storage criteria.
Importance of structured vs. unstructured data
Structured data tends to yield quantitative information, while unstructured data provides information that is more qualitative. Of course, both types of data analysis are important, although not all organizations require both.
For example, when viewed in terms of newer data analysis and manipulation technologies, structured data is a good fit for AI processing, such as machine learning.
Big data and big data analytics or data mining processing require massive amounts of data, and structured data is once again preferred. However, given the sheer amount of unstructured data being collected today, it also has a role in big data environments.