What is a distributed file system (DFS)?
A distributed file system (DFS) enables clients to access file storage from multiple hosts through a computer network as if they were accessing local storage. Files are spread across multiple storage servers and in multiple locations, enabling users to share data and storage resources. A DFS can be designed so geographically distributed users, such as remote workers and distributed teams, can access and share files remotely as if they were stored locally.
How a DFS works
A DFS clusters several storage nodes and logically distributes data sets across multiple nodes, each with its own computing power and storage. The data on a DFS can reside on various storage devices, such as solid-state and hard disk drives.
Data sets are replicated onto multiple servers, which enables redundancy to keep data highly available. The DFS is located on a collection of servers, mainframes or a cloud environment over a local area network (LAN) so multiple users can access and store unstructured data. Organizations that need to scale up their infrastructure can add more storage nodes to the DFS.
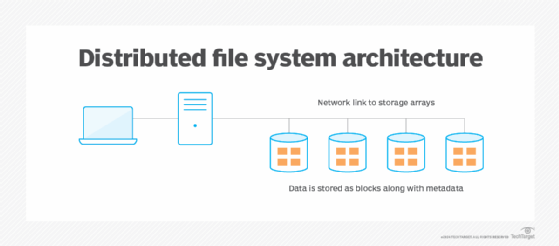
Clients access data on a DFS using namespaces. Organizations can group shared folders into logical namespaces. A namespace is the shared group of networked storage on a DFS root. These present files to users as one shared folder with multiple subfolders. When a user requests a file, the DFS brings up the first available copy.
There are two types of namespaces:
- Standalone DFS namespaces. A standalone or independent DFS namespace has just one host server and does not use Active Directory (AD). In a standalone namespace, the configuration data for the DFS is stored on the host server's registry. A standalone namespace is often used in environments that only need one server.
- Domain-based DFS namespaces. Domain-based DFS namespaces integrate and store the DFS configuration in AD. They have multiple host servers, and the DFS topology data is stored in AD. Domain-based namespaces are commonly used in environments that require higher availability.
Advantages and disadvantages of a DFS
Like any data storage paradigm, the DFS has its pluses and minuses. Choosing to use it -- or not -- is a matter of carefully considering both sides.
Advantages
Perhaps the most significant benefit of a DFS is that it provides organizations with a scalable system to manage unstructured data remotely. It can help organizations use legacy storage to save the cost of storage devices and hardware.
The following are some additional benefits:
- High availability and redundancy. File replication preserves data in case of point failures, giving the system high fault tolerance.
- Better performance. Distributing data storage across nodes enables parallel access and improved input/output (I/O).
- Collaboration-friendly data sharing. With locking mechanisms and versioning, multiple users can work on the same files simultaneously and from different locations.
- Cost savings. Most DFS options can run on commodity hardware, making infrastructure cheaper.
Disadvantages
The following downsides of DFS are not obvious up front but should be carefully considered:
- Complexity. Planning and building out a DFS is not easy; the network architecture alone can take much time and effort.
- Bottlenecks. Because consistency checks and synchronization are ongoing, I/O bottlenecks can often occur.
- Security challenges. Data spread across many nodes and locations requires that all of them be made secure, which can be daunting.
- Bandwidth issues. Perpetual replication and synchronization generate a great deal of network traffic over and above the movement of data itself.
Features of a DFS
Organizations use a DFS for features such as scalability, security and remote access to data. Additional features of a DFS include the following:
- Location independence. Users do not need to be aware of where data is stored. The DFS manages the location and presents files as if they were stored locally.
- Transparency. Transparency keeps the details of one file system away from other file systems and users. There are multiple types of transparency in distributed file systems, including the following:
-
- Structural transparency. Data appears as if it is on a user's device. Users cannot see how the DFS is configured, such as the number of file servers or storage devices.
- Access transparency. Users can access files that are located locally or remotely. Files can be accessed no matter where the user is, provided they are logged in to the system. If data is not stored on the same server, users should not be able to tell, and applications for local files should also be able to run on remote files.
- Replication transparency. Replicated files located on different file system nodes, such as on another storage system, are hidden from other nodes in the system. This enables the system to create multiple copies without affecting performance.
- Naming transparency. Files should not change when moving among storage nodes.
- Scalability. To scale a DFS, organizations can add file servers or storage nodes.
- High availability. The DFS should continue to work in the event of a partial system failure, such as a node failure or drive crash. It should also create backup copies if the system fails.
- Security. Data should be encrypted at rest and in transit to prevent unauthorized access or data deletion.
Types of DFS
A DFS uses file sharing protocols that enable users to access file servers over the DFS as if they were local storage.
A DFS can use the following protocols:
- Server Message Block. SMB is a file-sharing protocol that enables file read and write operations over a LAN. It is used primarily in Windows environments.
- Network File System. NFS is a client-server protocol for distributed file sharing commonly used for network-attached storage systems. It is also more commonly used with Linux and Unix operating systems.
- Hadoop Distributed File System. HDFS helps deploy a DFS designed for Hadoop applications.
- Filesystem in User Space. FUSE can be treated as a local filesystem and is mountable using Amazon S3, for instance.
Open source distributed file systems include the following:
- Ceph. Ceph is open source software designed to enable organizations to distribute data across multiple storage nodes. It is used in many OpenStack implementations.
- SeaweedFS. This fast open source DFS is friendly to blob storage and data lake implementations.
- HDFS. See above.
- GlusterFS. GlusterFS is a DFS that manages multiple disk storage resources into a single namespace.
- JuiceFS. This object storage system is a de facto DFS by virtue of its multiclient usage, but it uses an atypical architecture not seen in other DFSes.
Key trends in DFS
DFS is a rapidly evolving data storage option, especially for cloud storage. The following are some of the new developments to watch for:
- Big data and AI. Machine learning workloads for AI applications require high throughput and low-latency access, which DFS provides.
- Better metadata management. Managing distributed metadata is challenging, but DFS is improving its systems' scalability and performance.
- Multi-cloud support. Multi-cloud environments are increasingly common in the enterprise; DFS is adapting to this.
- Hybrid environments. Many organizations still maintain both on-premises and cloud resources; DFS is likewise becoming increasingly friendly to these scenarios.
- Internet of things integration. As IoT proliferates, DFS is expanding to support distributed data collection.
Vendors that offer DFS products
Numerous storage vendors offer DFS products and capabilities for unstructured data applications and workloads, including the following:
- Alluxio.
- Dell Technologies.
- IBM.
- Nutanix.
- Pure Storage.
- Qumulo.
- Scality.
- Vast Data.
- Weka.
Decentralized data storage provides organizations with an alternative to centralized cloud storage. Discover how decentralized storage operates and explore examples of products to consider.






