Free DownloadWhat is data backup? An in-depth guide
Data backup is constantly evolving, yet it endures as a necessity for organizations facing a host of potential disruptions. TechTarget's data backup guide discusses the importance of backup, outlines the benefits and challenges of providing this layer of data protection and provides an overview of different backup approaches, technologies and vendors. It also describes how to create and implement a data backup plan and includes a planning template. Throughout the guide, hyperlinks point to related articles that cover those topics in more depth.
The cost of downtime and how businesses can avoid it
Disrupted operations cost businesses billions of dollars annually. Disaster planning, cyber resilience and monitoring system dependencies can help limit the damage.
Business downtime damages sales, batters productivity and diminishes corporate standing with customers, partners and third-party watchdogs.
The expense is staggering. A 2024 Oxford Economics study found that downtime costs Global 2000 enterprises $400 billion a year -- a $200 million average annual loss for each company. The economic advisory firm noted that lost revenue was the most significant direct downtime cost, with regulatory fines and service-level agreement penalties rounding out the top three.
What is business downtime?
The Oxford Economics report, conducted with Cisco's Splunk subsidiary, focused on unplanned downtime, which can stem from human error, technical complexity, cyberattacks and natural disasters. Planned downtime also contributes to the operational strain on organizations when IT systems go offline for maintenance or upgrades.
CIOs and chief information security officers, along with other business and technology leaders, are responsible for reducing downtime and preserving the availability of systems, applications and data. Sprawling IT estates that include on-premises assets as well as cloud-based resources complicate that task.
The rapid and widespread digitalization of industries in recent years means that companies, large and small, have become more dependent on technology and more susceptible to system downtime. However, organizations can take steps to plan for and minimize disruption and its expensive aftermath.
As for causes, downtime triggers are many and varied. Here's a summary of the usual suspects.
Human error
Human error ranks among the leading factors in downtime events. "Ultimately, it's people," said Brian Greenberg, CIO at consultancy RHR International. "Either someone fat-fingered a command, didn't follow a process properly or maybe the organization didn't have the processes in place that would prevent mistakes from happening. Those are generally the main causes."
The No. 1 cause of human-error-related outages is "data center staff failing to follow procedures," according to the Uptime Institute's "Annual Outage Analysis 2025" report. The certification body's survey of 397 data center operators placed faulty processes/procedures as the second-highest culprit.
Paul Savill, global practice leader of network and edge at IT infrastructure services company Kyndryl, also cited people -- and the increasingly intricate technologies they manage -- as a major downtime contributor. "Human error is still a big one," he said. "A lot of human error is being driven by the complexities -- the amount of software upgrades [and] revisions that happen in the hardware these days that technicians have to deal with."
In many cases, people think they know. That's where the issues start.
Ofer RegevCTO and head of network operations, Faddom
Technical issues
Complex, frequently changing IT environments often contribute to human-caused outages. Application owners might know exactly what their software does but be unaware of an integration someone has built or changes in the underlying infrastructure, said Ofer Regev, CTO and head of network operations at software provider Faddom. "That could be anything from deploying a new Active Directory server or changing firewall rules, which they might not even know the full impact of," Regev explained. "In many cases, people think they know. That's where the issues start."
In general, frequent changes in an IT estate increase the potential for error. "Applications are usually a lot more dynamic," Regev said. "Autoscaling, lots of integrations with other tools and platforms, virtualization and cloud are dynamic by nature, and environments have to change more than they used to. Keeping track of those changes is more of a challenge."
Aging infrastructure can also lead to downtime events. "There is still a lot of very old infrastructure out there, basically end of life and end of support," Savill said. "So, the age of the equipment in the infrastructure is another big contributor."
The 2024 "Kyndryl Readiness Report" noted that 64% of CEOs are worried about outdated IT. The report is based on a survey of 3,200 senior decision-makers. Data gleaned from Kyndryl Bridge, the company's AIOps platform that manages customers' IT estates, indicated that 44% of mission-critical IT infrastructure is nearing or has already reached end-of-life status.
Cyberattacks and security breaches
Greenberg noted that technology can go down, but those types of failures are less frequent than outages caused by threat actors and events such as ransomware and phishing attacks.
Savill also cited cyberattacks as a source of downtime. "Cybersecurity threats just seem to continue to perpetuate," he said. "The battle between the good cybersecurity people and the bad actors continues, and new realms keep opening up." He pointed to the example of the Microsoft SharePoint zero-day vulnerability, which surfaced in July and affects on-premises SharePoint servers. Microsoft released an emergency patch for that issue. "That's a good example of how even with really large, trusted, sophisticated software providers like Microsoft, things can still go wrong," Savill added.
These key downtime triggers cost businesses billions of dollars annually. They include a set of overarching factors and groups of specific ones generated by Informa's internal AI assistant.
External factors
The Uptime Institute study stated that outages have become less frequent and severe in recent years, citing the data center industry's progress in risk management and reliability. But the organization warned data center operators against complacency, especially when it comes to threats beyond their walls. "Operators face mounting external risks that are largely beyond their control -- including power grid constraints, extreme weather, network provider failures and third-party software issues," the report noted.
External service providers, including cloud hyperscalers, telecom operators and colocation companies, also contribute to downtime. Those providers accounted for about two-thirds of publicly reported outages over the last nine years, according to the Uptime Institute.
Enterprises using cloud applications, for example, must adapt to the resulting limitations regarding availability and disaster recovery, Greenberg said. "Companies that have migrated more and more toward SaaS offerings," he explained, "no longer have the same kind of controls over disaster recovery that they did when they ran their own ERP or CRM."
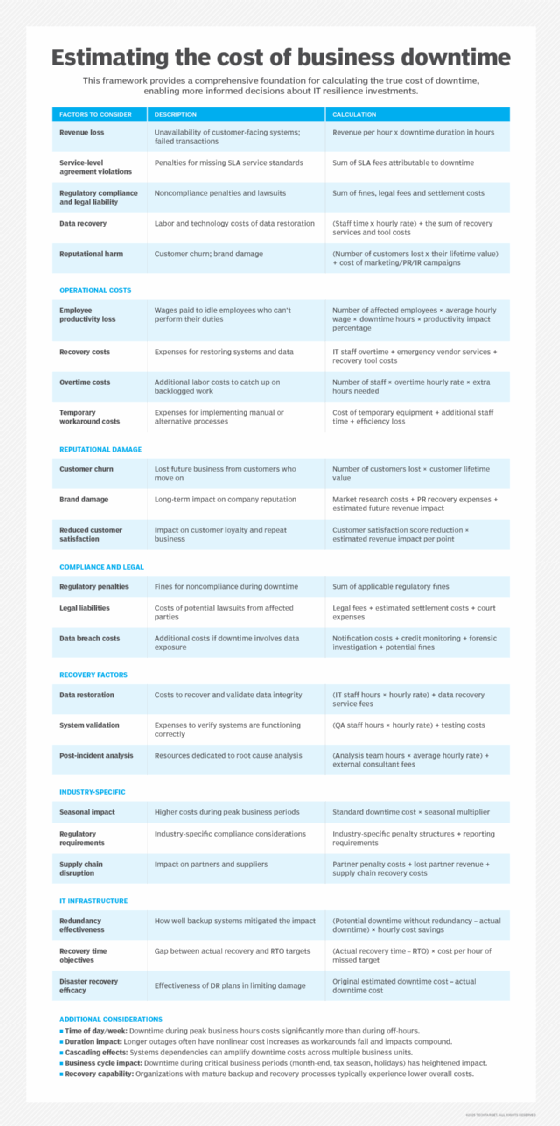
How much does business downtime cost?
The Oxford Economics study estimated that downtime costs an organization an average of $9,000 per minute or $540,000 per hour. Lost revenue, as the study noted, commands the largest slice of direct downtime costs. Other direct costs include the software and services required to restore lost or corrupted data.
But indirect costs exist as well, including customer churn and reputational damage. An Oxford Economics poll of chief marketing officers found that companies spend an average of $14 million on brand trust campaigns to repair their image after an outage.
Enterprises must calculate their downtime costs to develop resiliency strategies that focus on the availability of critical systems. Greenberg recommended starting with a business impact analysis (BIA). "The BIA tells us what systems are going to contribute greatly to revenue [and] negative effects if they go down," he said. "If it is order processing, that's going to have a pretty big impact. Manufacturing? Same thing."
Organizations should also identify the connections between their critical systems and other systems. Based on those findings, IT leaders can determine which systems should get the highest resiliency investments.
Overall, a downtime cost assessment will consider factors such as reputational damage, loss of productivity and recovery measures in addition to revenue loss.
How to minimize business downtime
Enterprises can employ several measures to minimize downtime risk and mitigate the effects of system failures.
1. Develop or update a BCDR strategy and plan
Business continuity and disaster recovery (BCDR) provide a foundation for minimizing the effects of outages. The objectives of a BCDR strategy and plan include implementing data backup procedures, reducing the risk of data loss, restoring critical operations, avoiding extensive revenue loss and buffering indirect costs such as reputational damage.
Conducting a BIA is typically an early step in creating a BCDR plan. The BIA, coupled with a risk assessment, provides details on critical business processes, their associated downtime costs and the IT resources that support them. A plan helps enterprises prepare for events such as power outages, natural disasters, physical security threats and supply chain disruption.
2. Create a cyber-resilience strategy
Incidents such as ransomware attacks can block access to business-critical files. Cyberattacks of that severity warrant a high-level plan. A cyber-resilience strategy aims to help businesses prepare for and respond to these incidents. Businesses should coordinate their cyber-resilience strategy with their BCDR activities, as they share common components such as incident response.
Resiliency also calls for security training to help employees recognize security threats and learn what to do if an incident occurs. "Constant education of the company's user community -- constant training and testing -- is an important part of reducing and mitigating" the threat of bad actors, Greenberg said.
Casey Rosenthal, who helped develop the chaos engineering approach as Netflix's availability czar, focuses on resilience engineering. He's found that the tenets organizations have used for decades to boost availability fall well short of current needs. "There are so many things that you think are common sense that turn out not to be true or not effective at building a system that is more reliable," explained Rosenthal, who is interim CEO at HiBeam, a division of Trifork U.S. that builds fault-tolerant, high-concurrency systems.
He includes root cause analysis in that category. Businesses use this approach in post-outage assessments to identify ways to shore up systems and prevent relapses. "Root cause analysis is, at best, a waste of time," Rosenthal surmised. "In complex systems, there is never a real root cause. The pursuit of that one line of code, or the one thing that caused the outage, is not a productive pursuit for creating a more reliable system."
A cloud provider, for example, might trace an outage to one engineer and one line of code in a configuration file that brought down a service for a few hours. Rosenthal contended that this finding is unhelpful, since the analysis fails to consider factors such as improper software documentation, insufficient training or C-level executives who emphasize new feature releases over reliability. "If you focus up in an organization, your odds of improving the reliability of the systems are much greater," Rosenthal said.
4. Assess the resiliency of cloud providers
Businesses that rely on cloud vendors for core IT must vet those suppliers' resiliency. Enterprises with in-house IT can set up redundant data centers and engineer fault tolerance into their systems, Greenberg noted. "When you get NetSuite or Gmail or HubSpot, you are not the engineer of those systems," he said. "So, part of your purchasing decision will have to be ensuring your provider has those capabilities already in place."
Greenberg noted that RHR International, which relies heavily on SaaS providers for its IT systems, looks for providers with built-in resiliency. As part of the evaluation process, organizations can review providers' System and Organization Controls (SOC) 2 Type 2 or ISO 27001 compliance audits. Those security frameworks include an availability component. "That gives you the assurance that those providers will be able to withstand and have resilience in their systems," Greenberg said.
A provider might include a carve-out in its SOC report, listing downstream service providers beyond the audit's scope. In some cases, a SaaS vendor relies on a cloud partner or partners, such as AWS, Google or Microsoft, Greenberg said. So, a business should also review the compliance audits of the vendors in the SaaS provider's supply chain.
5. Look for an edge in AI
AI shows promise for supporting network resilience, according to Savill. Kyndryl's AIOps platform, he noted, pulls information from a customer's IT systems to look for correlations that can manage their environments more proactively. The customer's data, pooled with data from other Kyndryl clients, reveals patterns likely to cause problems, he said, adding that this approach saves customers about $3 billion annually through downtime prevention, reduced planned maintenance costs and improved IT estate performance.
Following the CrowdStrike outage in 2024, Kyndryl also used AIOps to support data recovery. About 95% of affected Kyndryl customers had their information and systems recovered within 72 hours, according to Savill. AI helped determine what information was most important and what information was lost. The technology then pulled pertinent information from historical data to load during the restore. A manual process would have extended the outage time, Savill noted.
6. Track dependencies among systems
Dependencies and integrations among systems are not always tracked and documented. This knowledge gap can lead to outages.
"I like to design in, whenever possible, reporting and monitoring on system interconnectedness," Greenberg said. He cited API connectors between platforms as an example. Organizations need to know if the API is communicating and getting data, and if not, be able to notify the appropriate people of the issue. Connectors should be monitored to ensure they function properly. "This is oftentimes an oversight," Greenberg added. "A lot of people will set it and forget it."
Regev, whose company provides a dependency mapping tool, said IT departments aren't always aware of what they have and how their assets interact. "Everything around dependencies is going to be very important," he said.
John Moore is a writer for Informa TechTarget covering the CIO role, economic trends and the IT services industry.