10-step guide for testing a backup and recovery plan
Failure is not an option when it comes to backing up data and recovering it if disaster strikes. Data backup testing can pinpoint potential problems in the recovery process.

Creating a viable data backup plan is essential to maintaining an effective disaster recovery process. But backups can fail and, therefore, must be tested -- a practice that can be easily overlooked. Regular testing of backups under various scenarios ensures critical data will always be safe, secure, readily available and, in the event of a disaster, successfully recovered.
Data backup testing can identify a variety of unforeseen problems that could arise during a recovery process. Common issues include the following:
- Corrupt backup data that prevents it from being copied successfully to a recovery environment.
- Incomplete backup data that causes the loss of important information or fails to restore certain systems.
- Permissions issues or inconsistencies that make backup data challenging to access or cause system failures inside the recovery environment due to broken access control settings.
- Delays in accessing backup data or transferring it to a recovery environment, falling short of recovery time objective goals.
Backup testing can correct these issues before an actual disaster strikes and increase the chances of a successful recovery following an outage, cyberattack or other disruption. While backup testing has always been important, it has become particularly critical because of the scale and complexity of the backup and recovery challenges that businesses encounter today. The need to recover data and systems that often span multiple clouds, for example, can increase the chance of overlooking some data during the backup process. Likewise, the prevalence of cyberattacks, such as ransomware incidents in which attackers deliberately destroy backups alongside production systems, makes it especially important for businesses to verify whether their backups are intact and capable of driving successful recovery. Due to their complexity, data backup testing requires a multi-step process.
1. Document what needs to be backed up
Make an inventory of the organization's data and systems and identify which ones need to be backed up. Visibility into the company's assets is essential. Since today's IT environments are highly dynamic, there's a chance new resources have come online but are not yet covered by backups.
When documenting what you need to back up, consider not only traditional types of IT assets, such as databases, but also data associated with SaaS products hosted by external vendors. Even if the organization doesn't host its own SaaS apps, company data stored in those apps should be backed up in case the data is accidentally deleted or the SaaS provider experiences a failure.
Generating an IT asset inventory is complex, but certain types of automation tools, such as network mappers and data discovery software, can help streamline the process by automatically identifying many of the resources within the IT estate and tracking changes in real time.
2. Assess existing backups
Determine which backups are on hand, how recently they were created and where they're located. When backing up resources that span multiple environments and storing multiple copies of backups, it can be easy to lose track of the number of backups, where they live and which types of data they include. So just as with IT assets, create a comprehensive inventory of backups.
3. Examine backup contents
After taking stock of the backups and the assets needed to back up, examine the contents of the backup data to confirm it contains all the necessary files.
Some backup and recovery software can automate this process by comparing the data inside backups to production environments. Another approach is to spin up a recovery testing environment based on the backups, then use a tool like rsync with the --dry-run option enabled to compare the contents of the recovery environment to those in the production environment. Rsync is an open source tool for syncing two directories or file systems. With the --dry-run option turned on, it will identify differences between two environments without attempting to resolve the differences.
Note that it's normal for some deviations to exist between the backup data and command environment, because the latter has likely changed since the most recent backup occurred. Be sure there are no major unexpected differences, such as important data that exists in production but is not present in the recovery environment created based on the backups.
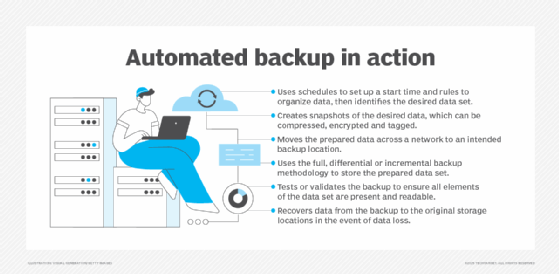
4. Check backup permissions
If backups fail to preserve the permissions settings present in production systems, recovery can be slower because it'll be necessary to reconfigure permissions manually during the recovery process. To test for that issue, compare the access rights of users and groups inside the backup data to those in the production environment.
Some backup software includes features that can compare these settings automatically. That function can also be done manually by restoring systems to a test environment based on the backups, then using the command ls -lR to create a list of all files and their associated access control settings for both the production and recovery environments. Then use diff to compare the lists, automatically identifying discrepancies.
5. Test recovery speed
Recovering from backups can take longer than expected, especially if data is moved over the network as part of the disaster recovery plan. In that case, network bandwidth limitations could delay the rate at which the data can be moved from backups into the recovery environment.
The best way to verify how quickly a recovery can be performed is to simulate a full recovery exercise: Transfer data from the backups to the environment or infrastructure that will be used for restoring disrupted systems and track how long it takes to complete the migration. Also consider whether there are delays in provisioning new resources during the recovery process. If new virtual servers need to be spun up as part of disaster recovery, for example, confirm that the virtualization software can launch new hosts at the required speed.
6. Assess backup redundancy
Even if the backups pass all the tests and enable successful recovery at the expected speed, there's a risk the backups themselves could be destroyed during a disaster. The best way to guard against this threat is to create redundant backups. The traditional rule of thumb is the so-called 3-2-1 backup strategy to maintain at least three copies of data, with at least two copies on different storage media, such as local hard drives and cloud storage, and at least one stored at a different physical location from the production systems. Some organizations today opt for even greater degrees of redundancy by storing copies of backups at more than two physical sites.
Regardless of how many backup copies are created and where they're stored, assessing whether the company's backup redundancy practices meet the necessary risk level is an important part of the backup testing process. It's not a good idea to wait until an actual disaster to discover, for example, that a recovery failed because all the backups were stored at the same location and wiped out during the disaster.
7. Evaluate recovery infrastructure
During the disaster recovery process, the recovery infrastructure -- either on-premises or in the cloud -- needs to be able to host the systems and data being restored. The cloud tends to be more cost-effective and scalable because it provides access to virtually unlimited infrastructure capacity with resources on a pay-as-you-go basis.
In either case, accompany the backup tests with an assessment of the recovery infrastructure. Consider how long it will take to get the recovery infrastructure up and running following a disaster. If the recovery infrastructure remains active on a permanent basis, the recovery time might be faster but also more expensive. Also consider whether there are any limitations that could prevent successful recovery. If, for example, the production environment has grown in size, it might not offer enough capacity to accommodate all of the workloads.
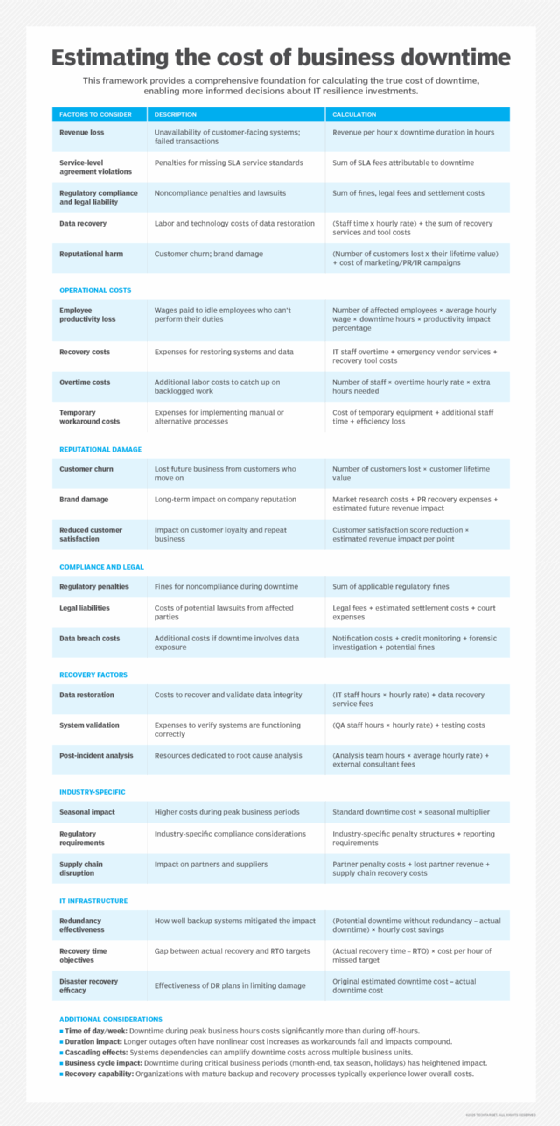
8. Weigh multiple disaster scenarios
Test and assess backups in various scenarios. Different types of outages can cause varying backup and recovery complications. For example, a cyberattack designed to prevent the organization from recovering its data presents a different challenge when an outage is caused by a fire in one of its data centers.
There are four main types of disaster scenarios that should be tested:
- Natural disasters, such as earthquakes and floods. The likelihood that they will affect recovery efforts can vary depending on where backups are stored and how susceptible those locations are to these types of catastrophic events.
- Physical disasters, such as fires or plumbing failures inside a data center. These risks can affect all organizations equally.
- Technology failures, such as disk drives that wear out or lose data. These issues tend to be more localized because they typically affect certain systems or data.
- Cybersecurity incidents, such as ransomware attacks or distributed denial-of-service attacks. They pose additional challenges because the attackers might attempt to hinder data recovery --for example, destroying backups or causing network failure.
Consider how each of these events might complicate the recovery process. If attackers take the network offline, for example, can the data be recovered by transferring it via physical storage media? Or if a server rack that contains a key network switch is destroyed by fire, can the recovery process be successfully completed by routing the data through another switch?
9. Evaluate disaster recovery playbooks
A disaster recovery playbook spells out who will do what to restore systems from backups during and following an incident. Develop multiple playbooks, one for each type of potential event. Evaluate them for accuracy, system coverage, availability of all those tasked with handling an incident and the likelihood of a successful recovery.
10. Automate and repeat recovery testing
Ensure that tests occur regularly by automating backup tests where possible. While some of these steps can't be automated, such as the manual process of reviewing playbooks, many core aspects of backup testing can be automated using backup and recovery software products or simple scripts.
Chris Tozzi is a freelance writer, research adviser and professor of IT and society. He has previously worked as a journalist and Linux systems administrator.







