
Getty Images/iStockphoto
Key features of a distributed file system
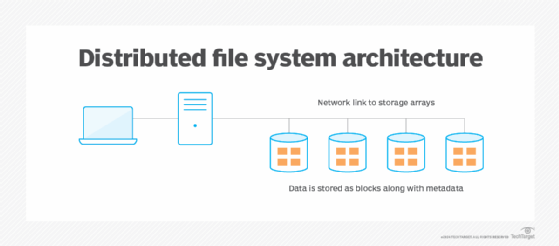
Distributed file systems enable users to access file data that is spread across multiple storage servers. A DFS should uphold data integrity and be secure and scalable.

Distributed file systems can share data from a single computing system among various servers, so client systems can use multiple storage resources as if they were local storage. Distributed file systems enable organizations to access data in an easily scalable, secure and convenient way.
A DFS enables direct host access to file data from multiple locations. By contrast, a network file system (NFS) is a type of distributed file system protocol where storage resources connect to a computer using network resources, such as a LAN or SAN. In DFS, hosts can access data using protocols such as NFS or SMB. Admins can also add nodes to a DFS for quick scaling, and backups should be used to create copies to prevent data loss in the event of drive failures.
Features of distributed file systems
Distributed file systems have several important features, as listed below:
- Access transparency. The DFS should display the user's file resources following the correct secure login process, regardless of the user's location.
- Naming transparency. File names should not indicate the location of any given file and should not change when the files move among storage nodes supported by the DFS.
- Replication transparency. Replicated files stored in different nodes of the DFS are kept hidden from other nodes in the file system.
- Structure transparency. The actual structure of the DFS, such as the number of file servers and storage devices, is hidden from users. By hiding the complexities, the system becomes more understandable for users.
- Data integrity. When multiple users access the same file storage systems and possibly even the same files, the DFS must manage the flow of access requests so there are no disruptions in file access or damage to file integrity.
- High availability. Like any storage device, equipment managed by a DFS must not be interrupted or disabled. However, if an issue such as a node failure or drive crash occurs, the DFS must remain operational and quickly reconfigure to alternate storage resources to maintain uninterrupted operations. Disaster recovery (DR) plans must include provisions for backing up and recovering DFS servers, as well as storage devices.
- High reliability. Another way to ensure data availability and survivability in a disruption is to have the DFS create backup copies of files specified by users. This is complementary to high availability and ensures that files and databases are available when needed.
- Namespaces. A namespace defines a repository of commands and variables to facilitate specific activities. In distributed file systems, namespaces gather the required commands and related actions needed for the DFS to function properly. A single namespace supporting multiple file systems generates a single user interface that makes all file systems look like a single file system to a user. Namespaces also reduce the chance of interference with the contents of other namespaces.
- Performance. This metric measures the time needed to process user file access requests and includes processor time, network transmission time and time needed to access the storage device and deliver the requested content. DFS performance should be comparable to a local file system.
- Scalability. As storage requirements increase, users typically deploy additional storage resources. The DFS should be powerful and adaptable enough so that, as storage capacity scales upward, the system can handle the additional resources so users do not notice any difference in performance.
- Security. As with any data storage arrangement, data must be protected from unauthorized access and cyberattacks that could damage or destroy the data. Encryption of the data – both at rest and in transit – helps increase data security and protection.
- User mobility. This feature dynamically routes a user's directory of file resources to the node where the user logs in.
Standalone DFS versus domain-based DFS namespaces
Standalone distributed file systems do not use Active Directory (AD). Instead, they are created locally with their own unique root directories and stored on the host server's registry. They cannot be linked with any other DFS entities. A standalone namespace is often used in environments that only need one server.
Domain-based DFS namespaces, however, store the configuration of a DFS in AD. This makes DFS easier to use and more accessible throughout a system. They are often used in environments that require high availability of data.
Advantages and limitations of distributed file systems
DFS technology provides file availability and recoverability in a scalable system by distributing critical files and databases across multiple storage devices. Some of these storage entities are at alternate company locations and can also be cloud-based. Users can also enhance data movement across storage nodes. These are important strategies for protecting data and supporting DR and business continuity (BC) initiatives.
For organizations with multiple locations, a DFS can be designed to support geographically dispersed sites and can also support remote workers and distributed teams by accessing and sharing files remotely as if they were stored locally.
There can be difficulties if there is a change in file servers, file storage applications and other storage protocols that might not be compatible with the DFS/NFS application. There are risks of data loss if security provisions are not in place. Movement of data from one storage node to another can result in lost data.
Protocols that can support a DFS
A DFS uses file sharing protocols that let users access file servers over the DFS as if they were local storage. The following are examples of three protocols a DFS can use:
- Server Message Block (SMB). The SMB file sharing protocol supports read/write operations on files over a LAN and is used in Windows environments.
- Network File System (NFS). NFS is a client-server protocol for distributed file sharing using network-attached storage (NAS). It is used with Linux and Unix operating systems.
- Hadoop Distributed File System (HDFS). The HDFS protocol is used to deploy a DFS designed for Hadoop applications.
Recent developments in DFS technology
Several developments have been occurring in DFS technology. The following are some examples of key activities:
- Cloud-based object storage. Current cloud storage software, such as Google Cloud Storage, Amazon S3 and Azure Blob Storage, are superseding traditional DFS tools like HDFS.
- Microsoft Storage Replica. This is considered a modern replacement for Distributed File System Replication (DFSR), as it supports both synchronous and asynchronous replication to minimize data loss in a disaster.
- Global file systems. Advances in global file system architectures that support real time replication, data locality and removing storage bottlenecks are addressing the limitations of traditional DFS.
- Interplanetary File System (IPFS). This technology uses a decentralized, peer-to-peer network structure with content-based addressing (e.g., content as opposed to location) to store files. It is designed to improve security, reduce redundancy and speed up file retrieval.
- Next-generation distributed storage technologies. Advanced storage technologies are on the horizon that improve scalability, security and performance by using erasure coding and blockchain-based decentralized consensus mechanisms, for example.
Impact of artificial intelligence on DFS technology
As might be expected, AI is impacting DFS in several important ways:
- Enhancements to data management. This will involve automated data classification to improve DFS file organization and retrieval, as well as the use of machine learning (ML) to optimize data placement and replication.
- Improved maintenance and fault tolerance. Proactive maintenance using AI can identify potential hardware outages before they occur, while advanced recovery techniques will minimize downtime by dynamically rerouting data access.
- Threat detection, prevention and management. Users can better identify unauthorized access or potential cyber threats using algorithms to analyze threat data. Likewise, advanced authentication (e.g., encryption) will likely improve data security.
- Enhanced performance. By adjusting caching strategies and enhancing load balancing, users can speed up file retrieval and improve resource utilization across distributed nodes.
- Automation of DFS functions. One of the key attributes of AI is that it can automate many traditional tasks such as file indexing, metadata management and access control, while enhancing data synchronization across multiple locations.
Paul Kirvan, FBCI, CISA, is an independent consultant and technical writer with more than 35 years of experience in business continuity, disaster recovery, resilience, cybersecurity, GRC, telecom and technical writing.




