
Getty Images/iStockphoto
High availability and resiliency are vital to a DR strategy
Together, high availability and resiliency can prepare an organization for potential disruptions. Find out how these metrics work in disaster recovery.

In an age where acceptable downtime is essentially zero, high availability and resiliency are critical metrics in business continuity and technology disaster recovery.
High availability and resiliency address disruptions to an organization from system failures, network outages and application issues. In IT, HA describes systems that function without interruption for specific periods of time. Resiliency is the ability of a system to recover from a disruption and to modify its capabilities to adapt and better respond to similar events in the future.
Despite common goals, HA and resiliency are not synonymous. A strong disaster recovery strategy incorporates both concepts.
This article will discuss each metric, the differences between the two and how they fit into a DR plan. It will also cover fault tolerance, another critical -- but separate -- metric.
What is high availability?
High availability describes a system's ability to remain operational without interruption for a specific period.
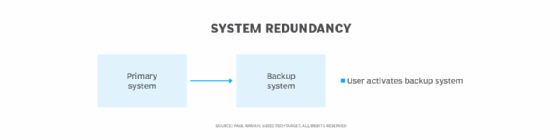
IT administrators typically use redundancy to make sure that backup hardware, software and storage are available if primary resources fail. In many cases, users must activate the backup resources. HA takes technology redundancy to the next level.
HA improves on redundancy by reducing single points of failure, adding dynamic system monitoring to detect failures. HA also incorporates an automated failover capability to immediately move the production assets to an alternate platform.
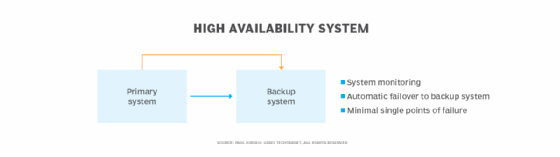
The backup system can be in a data center or an alternate location, such as a cloud service. The time needed to recover and restart the system following failover depends on the network bandwidth available and the technology used to enact the failover.
HA systems are typically designed to achieve a specific level of availability, often called the percent uptime. For example, to truly consider a system highly available, many organizations aim for five-nines availability. This means that the system is available 99.999% of the time, which equates to downtime of less than six minutes in a year.
Greater availability usually comes at greater cost, but also provides a significant boost to an organization's DR capabilities. The technology that monitors the system's performance, the costs for backup resources and the resources an organization needs to establish HA performance are more than those required for simple redundancy. It is good practice to maintain spares of critical IT assets, power systems, network components and other resources.
However, considering the costs associated with downtime, preventive measures to guarantee high availability can be worth the initial expense.
What is resiliency?
Business continuity and disaster recovery (BCDR) typically focus on recovering systems and restoring business processes. Resiliency goes a step further. To be considered resilient, organizations must use lessons learned from previous events to help adapt and improve their methods to be better prepared for future events. This can be applied to BCDR plans as well as IT systems and networks, backup resources, power and environmental systems, and other IT resources.
For example, a commercial power outage of two weeks might be beyond an organization's backup power system capabilities. To achieve more resilient power, the organization can install a larger system and make arrangements for scheduled refueling.
High availability and resiliency in DR
High availability applies to system availability and reliability. Resiliency addresses how resources have been improved to better deal with future incidents. This makes them both integral elements of a strong disaster recovery plan. Both methods reduce downtime, which is critical in DR today.
High availability is not the same thing as resiliency, but it does contribute to it. However, it also contributes to higher costs because of the technology required. Resiliency is not as straightforward when it comes to expenses. There are different levels of resiliency an organization can achieve, so spending and budget will vary based on what level the organization requires.
While disaster recovery is growing as a priority for businesses, some organizations are reluctant to spend on a DR strategy. IT and DR leaders must make sure that the costs and resources needed to achieve the desired level of resiliency are balanced with the organization's business needs. If management has a limited appetite for additional technology investments, a highly available infrastructure might not be an option.
What about fault tolerance?
Taking the model of high availability to the next level is fault tolerance. None of the approaches in this article can guarantee resiliency, but a progression to fault tolerance is likely to result in a higher state of resiliency.
Fault tolerance means that a system is designed to almost never fail, other than for unusual circumstances, such as natural disasters and other unanticipated events. HA and fault tolerance are typically associated with hardware and network elements. Software that fails will fail in HA and fault-tolerant systems alike.
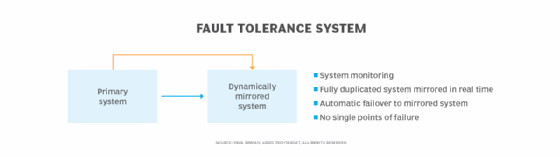
One way that organizations achieve fault tolerance is by establishing fully mirrored systems that are immediately updated whenever the primary system is updated. In this scenario, single points of failure are largely eliminated. Mirrored systems are in constant standby mode, ready to take over processing from a disrupted system. When system monitoring detects an issue that crosses a preset threshold, it immediately transfers production duties to the standby resources so that production is never interrupted. These resources can be local or remotely located, typically in a cloud.
Due to the additional systems and resources required, achieving fault tolerance has higher costs than high availability.
Paul Kirvan, FBCI, CISA, is an independent consultant and technical writer with more than 35 years of experience in business continuity, disaster recovery, resilience, cybersecurity, GRC, telecom and technical writing.







