data center resiliency
What is data center resiliency?
Resiliency is the ability of a server, network, storage system or an entire data center to recover quickly and continue operating even when there has been an equipment failure, power outage or other disruption.
Data center resiliency is a planned part of a facility's architecture and is usually associated with a disaster recovery plan and other data center DR considerations, such as data protection. The adjective resilient means having the ability to spring back.
Data center resiliency is often achieved through the use of redundant components, systems and facilities. When one element fails or experiences a disruption, the redundant element takes over seamlessly and continues to provide computing services to the user base.
Business continuity (BC), incident response and emergency response all factor into an organization's overall resilience. The goal of resiliency is to minimize downtime. Ideally, users of a resilient system never know that a disruption has occurred.
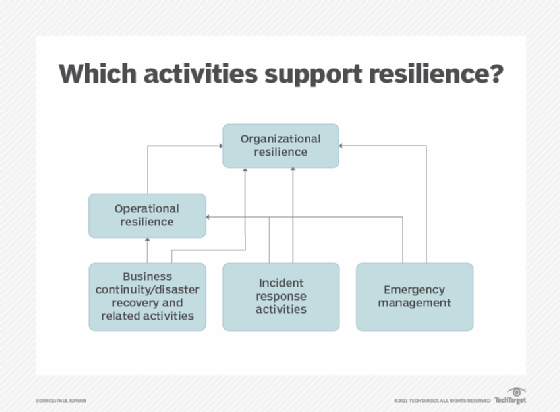
Examples of data center resiliency
The following are some ways that data resiliency is incorporated into data centers.
Server redundancy
If a server's power supply fails, the server fails, too. That means all of the workloads on that server are unavailable until the server is repaired and restarted or the workloads can be restarted on another suitable server.
Servers often incorporate a redundant, uninterruptible power supply (UPS). If that's the case, the backup power supply turns on automatically when the power supply fails and keeps the server running until a technician can replace the failed power supply.
Techniques, such as server clustering, support redundant workloads on multiple physical servers. When one server in the cluster fails, another node takes over with its redundant workloads.
Data center redundancy
The same redundancy concept holds true at the level of the data center facility itself. For example, an organization may power its data center with two separate utility feeds from different utility providers so that a backup provider is available when the first provider fails.
Colocation
Organizations that support hot sites can use data center colocation. With this approach, data center managers move an entire operation from one facility to another in response to a local disruption or regional disaster.
Critical services
The redundancy techniques employed in a data center can vary with the importance of the respective workloads, and that redundancy is a key factor in a resiliency plan. Organizations with mission-critical computing workloads or high availability applications use more resilient techniques at more levels in their data center because the cost of not preserving critical computing services is typically higher during a prolonged service outage.
For example, critical business services, such as online transaction processing or database systems, may be designed with comprehensive data center resiliency, including clustering, snapshots and off-site redundancy. Nonessential workloads that can tolerate some level of disruption may receive little resiliency or simply remain offline until they can be restored.
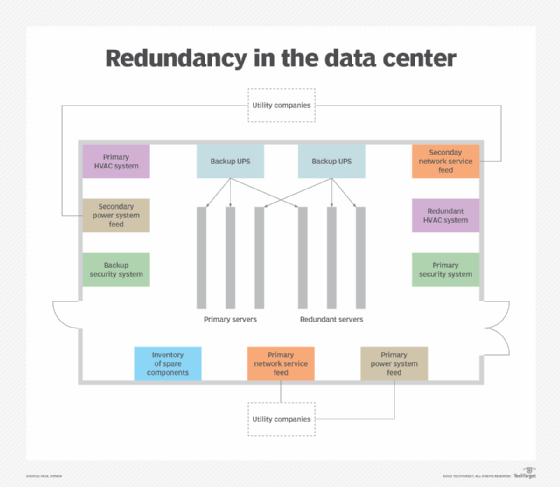
Resiliency vs. redundancy
The easiest way to differentiate between the terms resiliency and redundancy is to understand that, to achieve resilience, one must first have redundancy. However, while redundancy is relatively easy to achieve by adding components that back up primary data center components, that still does not mean the data center is resilient.
Data center managers can determine if a data center is resilient in one of the following two ways:
- They can shut off the power to the data center and see what happens. Most CIOs and their managers won't attempt this experiment, even with redundant resources. The risk is too great, especially during daily production.
- They can launch some level of shutdown over a weekend or holiday when operations are slower and less critical. The results of this approach provide insight into an organization's ability to bounce back from a major disruption of its IT infrastructure. It also identifies areas where additional resources are needed to boost recoverability of critical systems.
Data center industry vendors, consultants and research groups provide assessment services and insight to help business managers better understand the need for more resilient data centers.
How to achieve data center resiliency?
To develop a resiliency plan, data center operations teams must evaluate their existing IT infrastructure and decide which elements are mission-critical. From there, they must determine what level of resiliency each needs. To do this, they should consider both business and technical factors.
The cost of resiliency can be high because more resilience requires more investment.
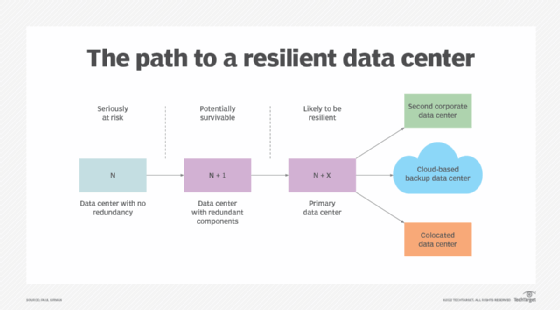
The diagram below introduces the concept of N+ redundancy as an element of resiliency. A data center with no redundancy is an N facility. Redundant components are added until there is a one-to-one level of redundancy. At that point, the data center has N+1 redundancy.
Some organizations add multiple elements of redundancy, such as a second corporate data center, a colocated data center or a cloud-based replicated data center configuration. These approaches move the organization closer to real resiliency, or N+X resiliency. For example, a cloud computing approach might offer the benefit of the cloud provider having multiple data centers of its own to provide yet more real-time resiliency.
Other steps that can help make a data center more resilient and maximize uptime are the following:
- Monitor data center operating conditions. Most data centers have temperature and humidity monitors. Data center operators should have additional monitoring equipment to keep an eye on server operations, application processing, data backup and power levels. Watching these operations identifies potentially disruptive situations before they escalate into outages.
- Have redundant networking and security. An important example of this is to have two or more internet service providers that use separately routed internet access paths. Redundancy in network perimeter configurations enhances security.
- Deploy alarms and other alerting devices. These signal when specific Performance thresholds have been exceeded.
- Conduct exercises and simulations. Outage and other problem simulations can help identify where vulnerabilities exist that could cause a real incident.
Ensuring a resilient data center is an ongoing activity and must be part of daily data center operations and not just be part of an occasional exercise.
It's not just the data center that needs to be resilient. Cloud resiliency is also critical when it comes to ensuring BC. Find out what you need to know about it.
Continue Reading About data center resiliency
Dig Deeper on Data center ops, monitoring and management
-
![]()
4 ways to support contact center calling redundancy
By: Reda Chouffani
-
![]()
Bulletproof IT: How CIOs safeguard the tech supply chain
By: Tim Murphy
-
![]()
What is digital resilience? Definition, strategy and use cases
By: Stephen Bigelow
-
![]()
High availability and resiliency are vital to a DR strategy
By: Paul Kirvan



