What is OCR (optical character recognition)?

OCR (optical character recognition) is the use of technology to distinguish printed or handwritten text characters inside digital images of physical documents, such as a scanned paper document. The basic process of OCR involves examining the text of a document and translating the characters into code that can be used for data processing. OCR is sometimes referred to as text recognition.
OCR systems consist of a combination of hardware and software that is used to convert physical documents into machine-readable text. Hardware, such as an optical scanner or specialized circuit board, is used to copy or read text while software typically handles the advanced processing. Software can also take advantage of AI to implement more advanced methods of intelligent character recognition (ICR), like identifying languages or styles of handwriting.
OCR is most commonly used to convert hard copies of legal or historical documents into PDFs. Once the document is in this soft copy, users can edit, format and search it as if it were created with a word processor.
How optical character recognition works
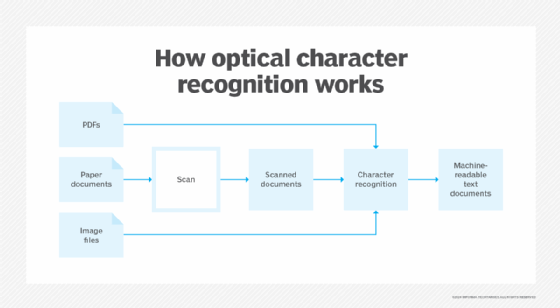
The first step of OCR is using a scanner to process a document's physical form. Once all pages are copied, OCR software converts the document into a two-color, or black-and-white, version. The scanned-in image or bitmap is analyzed for light and dark areas, where the dark areas are identified as characters that need to be recognized and the light areas as background.
The dark areas are then processed further to find alphabetic letters or numeric digits. OCR programs can vary in their techniques, but typically involve targeting one character, word or block of text at a time. Characters are then identified using one of two algorithms:
- Pattern recognition. OCR programs are fed examples of text in various fonts and formats, which they then use pattern recognition to compare and recognize characters in the scanned document.
- Feature detection. OCR programs apply rules regarding the features of a specific letter or number to recognize characters in the scanned document. Features could include the number of angled lines, crossed lines or curves in a character for comparison. For example, the capital letter "A" may be stored as two diagonal lines that meet with a horizontal line across the middle.
When a character is identified, it is converted into ASCII code that computer systems can use to handle further manipulations. Users should correct basic errors, proofread and ensure that complex layouts are handled properly before saving the document for future use.
Optical character recognition use cases
OCR can be used for a variety of applications, including the following:
- Scanning printed documents into versions that can be edited with word processors, like Microsoft Word or Google Docs.
- Indexing print material for search engines.
- Automating data entry, extraction and processing.
- Deciphering documents into text that can be read aloud to visually impaired or blind users.
- Archiving historic information, such as newspapers, magazines or phonebooks, into searchable formats.
- Electronically depositing checks without the need for a bank teller.
- Placing important, signed legal documents into an electronic database.
- Recognizing text, such as license plates, with a camera or software.
- Sorting letters for mail delivery.
- Translating words within an image into a specified language.
Benefits of optical character recognition
The main advantages of OCR technology are the following:
- saves time;
- decreases errors;
- minimizes effort; and
- enables actions that are not possible with physical copies, such as compressing into ZIP files, highlighting keywords, incorporating into a website and attaching to an email.
While taking images of documents enables them to be digitally archived, OCR provides the added functionality for editing and searching those documents.
OCR pulls text from images, but intelligent document processing (IDP) goes further—understanding meaning and context. Discover the key differences between OCR vs. IDP and why they matter.







