What is ASCII (American Standard Code for Information Interchange)?
ASCII (American Standard Code for Information Interchange) is the most common character encoding format for text data in computers and on the internet. In standard ASCII-encoded data, there are unique values for 128 alphabetic, numeric or special additional characters and control codes. Over the years, several ASCII extended sets have emerged that expand the original set of 128 characters with additional symbols and characters.
ASCII characters in the original ASCII table
The ASCII encoding system includes hundreds of characters, each assigned its own unique binary code. In the original system of 128 characters, the binary codes were 7 bits long. Today, ASCII uses 8-bit codes to maintain compatibility with modern computers that use 8-bit bytes. The extra bit in these codes is usually set to 0.
ASCII characters include uppercase and lowercase letters A through Z, numerals 0 through 9 and basic punctuation symbols. Codes 32-127 are all printable ASCII characters, representing letters, numbers, punctuation marks, plus some special characters like ^, [, \, ~ and other miscellaneous symbols.
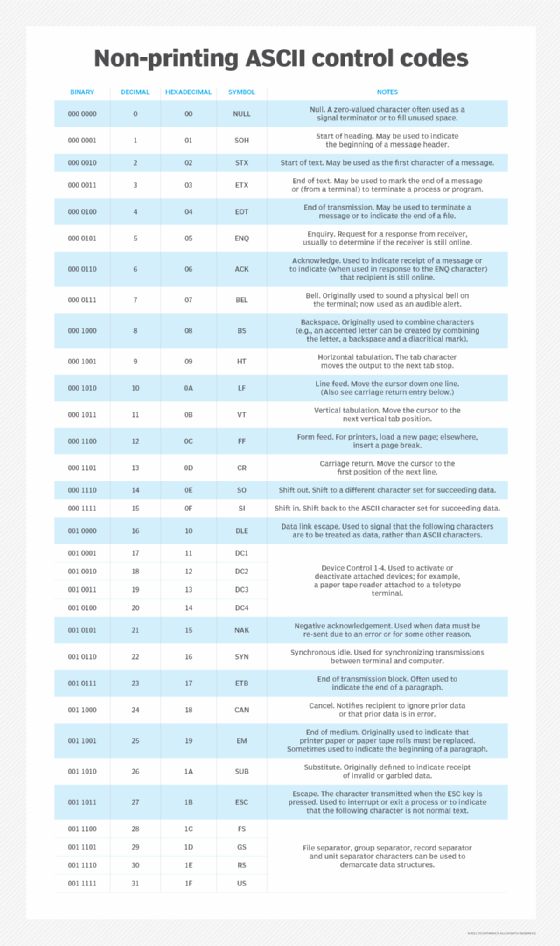
The ASCII format also uses some non-printing control characters (also called control codes) originally intended for use with teletype printing terminals used in the early days of computing to input and output data. These characters, as described in Table 1, range from decimal 0 to decimal 31, and represent characters like null character (character 0), back space (character 8), synchronous idle (character 22) and unit separator (character 31).
ASCII character representation
ASCII characters in both original and extended formats may be represented in several ways:
- As pairs of hexadecimal digits -- base-16 numbers, represented as 0 through 9 and A through F for the decimal values of 10-15.
- As three-digit octal (base 8) numbers.
- As decimal numbers from 0 to 127 (or 0 to 255 in the extended table).
- As 7-bit or 8-bit binary.
- As an HTML number.
Some characters can also be represented as their HTML names.
The ASCII encoding for the lowercase letter "m" is represented in these ways:
| Character/symbol | Description | Hexadecimal | Octal | Decimal | Binary (7 bit) | Binary (8 bit) | HTML number |
| m | Lowercase m | 6D | 155 | 109 | 110 1101 | 0110 1101 | m |
Similarly, the ASCII encoding for the semicolon (;) can be represented in the following ways:
| Character/symbol | Description | Hexadecimal | Octal | Decimal | Binary (7 bit) | Binary (8 bit) | HTML number | HTML name |
| ; | Semicolon | 3B | 073 | 59 | 001 11011 | 0001 11011 | ; | ; |
ASCII control codes (non-printing)
The ASCII values for 0 through 31 (binary: 0000 0000 through 0001 1111 in the 8-bit ASCII system) are non-printing control codes. They were originally intended for controlling the flow of data and include codes that do the following:
- Show the end or beginning of data components.
- Control or show the state of hardware used for data transmission.
- Accommodate positioning of the cursor pointer in a data stream.
- Indicate the start or end of text or transmission.
- Control peripheral devices like printers.
Some of the ASCII control codes are shown in the following table.
| Character/symbol | Description | Hexadecimal | Octal | Decimal | Binary (7 bit) | Binary (8 bit) | HTML number |
| NUL | Null character | 00 | 000 | 0 | 000 0000 | 0000 0000 | � |
| ACK | Acknowledge | 06 | 006 | 6 | 000 0110 | 0000 0110 |  |
| BS | Backspace | 08 | 010 | 8 | 0000 1000 | 000 1000 |  |
| CR | Carriage Return | 0D | 015 | 13 | 000 1101 | 0000 1101 | |
| DC1 | Device Control 1 (oft. XON) | 11 | 021 | 17 | 001 0001 | 0001 0001 |  |
| ESC | Escape | 1B | 033 | 27 | 001 1011 | 0001 1011 |  |
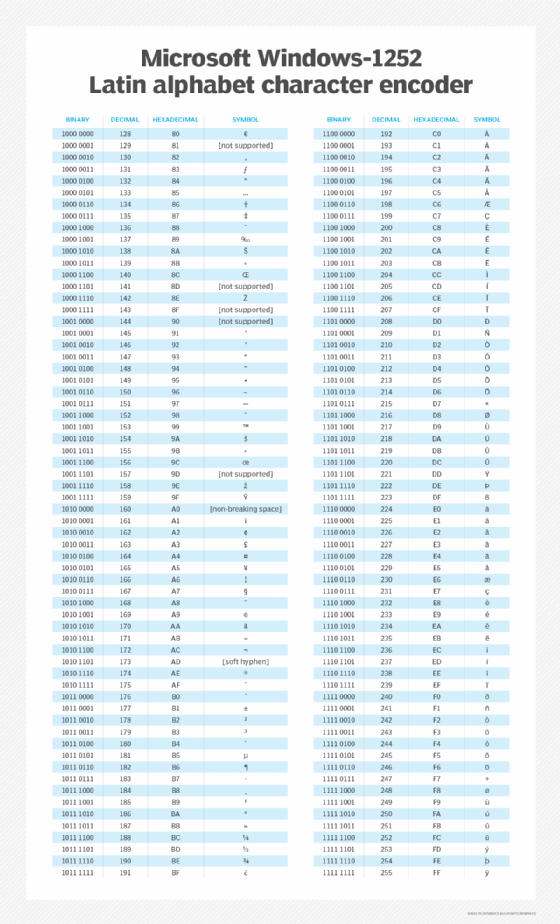
Extended ASCII characters
The standard ASCII character set is only 7 bits, and characters are represented as 8-bit bytes with the most significant bit set to 0. The extended ASCII character set includes 127 more 8-bit characters, where the most significant bit is set to 1. The extended ASCII character set includes the binary values from 128 (1000 0000) through 255 (1111 1111).
Here are some examples of characters included in the extended ASCII table.
| Character/symbol | Description | Hexadecimal | Octal | Decimal | Binary (8 bit) | HTML number | HTML name |
| € | Euro sign | 80 | 200 | 128 | 1000 0000 | € | € |
| … | Horizontal ellipsis | 85 | 205 | 133 | 10000101 | … | … |
| ' | Left single quotation mark | 91 | 221 | 145 | 1001 0001 | ‘ | ‘ |
| ÷ | Division sign | F7 | 367 | 247 | 1111 0111 | ÷ | ÷ |
| À | Latin capital letter A with grave | C0 | 300 | 192 | 1100 0000 | À | À |
| ÿ | Latin small letter y with diaeresis | FF | 377 | 255 | 1111 1111 | ÿ | ÿ |
There is no single extended ASCII character set. Unlike standard ASCII characters, there are multiple versions of the extended ASCII character set. These sets may differ depending on the operating system or vendor. Extended ASCII character sets typically include symbols, letters with diacritical marks, graphical markings and mathematical symbols including some Latin letters.
Table 2 lists Microsoft's Windows-1252 (CP-1252) character encoding of the Latin alphabet. This is the default extended ASCII character set for Windows that American and British English and other European languages use. Also, the table is a superset of ISO 8859-1 (ISO Latin-1) in terms of printable characters and uses only printable characters in the 128 to 159 range (no control characters).
How does ASCII work?
ASCII offers a universally accepted and understood character set for basic data communications. The format codes a string of data as ASCII characters that can be interpreted and displayed as readable plain text for people and as data for computers.
Programmers use the design of the ASCII character set to simplify certain tasks. For example, using ASCII character codes, changing a single bit easily converts text from uppercase to lowercase.
The capital letter "A" is represented by the binary value:
0100 0001
The lowercase letter "a" is represented by the binary value:
0110 0001
The difference is the third most significant bit. In decimal and hexadecimal, this corresponds to:
| Character | Binary | Decimal | Hexadecimal |
| A | 0100 0001 | 65 | 41 |
| a | 0110 0001 | 97 | 61 |
The difference between uppercase and lowercase characters is always 32 (0x20 in hexadecimal), so converting from uppercase to lowercase and back is a matter of adding or subtracting 32 from the ASCII character code.
Similarly, hexadecimal characters for the digits 0 through 9 are as follows:
| Character | Binary | Decimal | Hexadecimal |
| 0 | 0011 0000 | 48 | 30 |
| 1 | 0011 0001 | 49 | 31 |
| 2 | 0011 0010 | 50 | 32 |
| 3 | 0011 0011 | 51 | 33 |
| 4 | 0011 0100 | 52 | 34 |
| 5 | 0011 0101 | 53 | 35 |
| 6 | 0011 0110 | 54 | 36 |
| 7 | 0011 0111 | 55 | 37 |
| 8 | 0011 1000 | 56 | 38 |
| 9 | 0011 1001 | 57 | 39 |
Using this encoding, developers can easily convert ASCII digits to numerical values by stripping off the four most significant bits of the binary ASCII values (0011). This calculation can also be done by dropping the first hexadecimal digit or by subtracting 48 from the decimal ASCII code.
Developers can also check the most significant bit of characters in a sequence to verify that a data stream, string or file contains ASCII values. The most significant bit of basic ASCII characters will always be 0; if that bit is 1, then the character is not an ASCII-encoded character.
Why is ASCII important?
ASCII was the first major character encoding standard for data processing by computers and other electronic devices. The standardized, universally accepted nature of ASCII codes let different systems communicate with each other to process data, share files and documents, and more. Developers can use the ASCII format to design interfaces that both humans and computers understand.
As a standardized format for representing information and facilitating communication, ASCII is important in numerous fields, including the following:
- Computer programming.
- Data transmission protocols.
- Visual design.
- Graphic design.
Today, most modern computer systems use Unicode, also known as the Unicode Worldwide Character Standard. This means that ASCII encoding is now technically obsolete. Because ASCII text is compatible with Unicode Transformation Format 8 (UTF-8), many computers still use ASCII or Unicode encoding. The exceptions are some IBM mainframes that use the proprietary 8-bit code called Extended Binary Coded Decimal Interchange Code (EBCDIC).
ASCII variants in other languages
When it was first introduced, ASCII supported English language text only. When 8-bit computers became common during the 1970s, vendors and standards bodies began extending the ASCII character set to include 128 additional character values. Extended ASCII incorporates non-English characters, but it is still insufficient for comprehensive encoding of text in most world languages, including English. To overcome this limitation, different extended ASCII character sets have been developed.
Initially, other character encoding standards were adopted for other languages. In some cases, the standards were designed for other countries with different requirements. In other cases, the encodings were hardware manufacturers' proprietary designs.
What is the relationship between ASCII and Unicode?
Unicode is a character encoding standard that includes ASCII encodings. In 2003, the Internet Engineering Task Force (IETF) standardized the use of UTF-8 encoding for all web content in RFC 3629. Unicode character encoding replaces ASCII encoding, but it is backward-compatible with ASCII. ASCII characters use the same encoding as the first 128 characters of UTF-8.
Unicode defines codespaces for the implementation of character encodings for different languages. Characters can be mapped to encodings using either UTF or Universal Coded Character Set (UCS).
Depending on the language and mapping used, characters can be expressed in one to four 8-bit bytes (UTF-8), in two 16-bit units (UTF-16) or in a single 32-bit unit (UTF-32).
Both ASCII and Unicode provide standard ways to encode characters for use by computers and other devices. The number of characters supported and the way each character is represented differ in ASCII and Unicode. Even with extended ASCII, the number of English characters represented is 256. In contrast, Unicode supports codes for close to 150,000 characters. This is why Unicode can be used to represent text from many different languages for computer processing, not just English. Among the reasons for the emergence and introduction of Unicode is its ability to support characters for languages that use thousands of characters.
Unicode is also a universal encoding standard because it is platform-, program- and programming language-agnostic. The main drawback of Unicode is that it can only represent plain text, not rich text.
The UCS standard is an ISO (International Organization for Standardization) standard, ISO/IEC 10646. Since ISO/IEC 10646 defines the character encoding for UCS, Unicode supports the same encoding points and characters as ISO/IEC 10646 (specifically ISO/IEC 10646:2003).
ASCII advantages and disadvantages
More than half a century of use has made clear the advantages and disadvantages of ASCII.
Advantages
- Universally accepted. ASCII character encoding is universally understood and accepted. It is also universally implemented in computing through the Unicode standard (except for IBM mainframe EBCDIC encoding).
- Compact character encoding. Standard codes can be expressed in 7 or 8 bits. This means data that can be expressed in the standard ASCII character set requires only as many bytes to store or send as the number of characters in the data.
- Efficient for programming. The character codes for letters and numbers are well adapted to programming techniques for manipulating text and using numbers for calculations or storage as raw data.
Disadvantages
- Limited character set. Even with extended ASCII, only 255 distinct characters can be represented. The characters in a standard character set are enough for English language communications. However, it is difficult to accommodate languages that do not use the Latin alphabet, despite the support for diacritical marks and Greek letters in extended ASCII.
- Inefficient character encoding. Representing characters from other alphabets other than English requires more overhead such as escape codes.
Converting text to ASCII code in Windows
There is more than one way to display text as ASCII codes in Windows. To use the Windows PowerShell command Format-Hex to display ASCII encoding for a text file, take these steps:
- Open the Windows PowerShell application. Click on the search box in the lower left of your Windows desktop. Type PowerShell and click on the PowerShell icon to start the application.
- Format-Hex command. Enter the following command to display the ASCII encoding for a file called hello.txt in the c:\Users\userID\Documents directory: format-hex .\hello.txt
- View output. ASCII encoding for the file hello.txt will be displayed as shown in Figure 1.
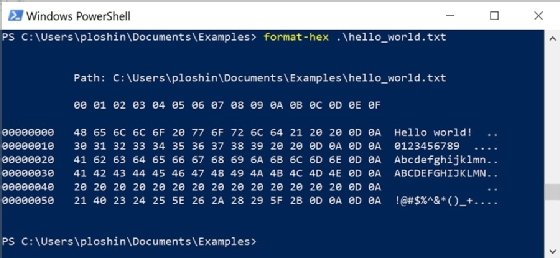
The top of the output shows that data is displayed in 16 columns, with one character per column. A running count of characters, in hexadecimal, is displayed along the left side of the output. In this case, in the last line, there are 0x60 (or 96 in decimal) characters at the start of the last line. ASCII encoding for the file's characters are shown in a grid 16 characters wide, with encoding in two-digit hexadecimal values. The original contents of the file are displayed to the right in 16-character groupings.
The original file has two spaces (ASCII 0x20) followed by a CR (carriage return, ASCII 0x0D) and LF (line feed, ASCII 0A) characters. The CR-LF combination is used in ASCII files to show the end of a line.
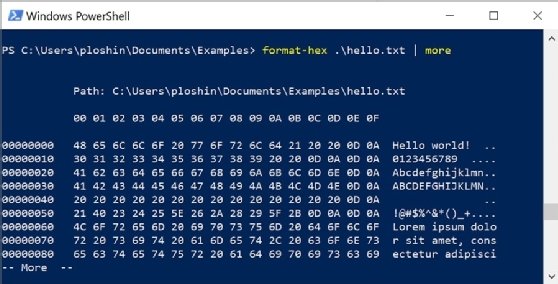
Other options. Format-Hex can be used with other commands for easier command-line viewing of larger files. For example, this command is used to page through ASCII encoding of a large file:
Format-Hex .\hello-long.txt | more
The output will look similar to Figure 2, and you can view output one page at a time.
The FTP ascii command
The File Transfer Protocol (FTP) has an ascii command that is used to enable the transfer of ASCII-encoded files. When transferring files in ASCII mode in FTP, the receiving host may change the file so it will be formatted as ASCII on the destination host.
When FTP transfers files using the binary mode, those files are not changed.
ASCII art
ASCII characters can be combined graphically to create an image. ASCII art is a common technique for creating graphical images on text-only media like a computer terminal or text-only printer. For example, this ASCII art is an example of an early emoji.
¯\_(ツ)_/¯
More elaborate images are possible when using more lines and more characters, especially from extended ASCII character sets.
History and future of ASCII
ASCII encoding is based on character encoding used for telegraph data and Morse code. The ASCII character encoding standard was designed in the early 1960s to provide a standard character set all computers could understand, facilitating data interchange between them. The American National Standards Institute first published it as a standard for computing in 1963.
The IETF adopted ASCII as a standard for internet data when it published ASCII format for network interchange as RFC 20 in 1969. That request for comments (RFC) document standardized the use of ASCII for internet data and was accepted as a full standard in 2015.
ASCII remains a universally accessible and acceptable standard for encoding computer and network data. Given the need to preserve data stored over the past decades, most experts predict it will remain foundational for computing, programming and electronic data interchange for many more years to come.
Learn more about data storage management and how organizations use data retention policies to retain data and maintain access to it over the long term.