
Getty Images/iStockphoto
Compare Hadoop vs. Spark vs. Kafka for your big data strategy
Learn more about these three big data frameworks and what use case best suits each one. You might also examine options such as Apache Hive, Flink and Storm.

Big data became popular about a decade ago. The falling cost of storage led many enterprises to retain much of the data they ingested or generated so they could mine it for key business insights.
Analyzing all that data has driven the development of a variety of big data frameworks capable of sifting through masses of data, starting with Hadoop. Big data frameworks were initially used for data at rest in a data warehouse or data lake, but a more recent trend is to process data in real time as it streams in from multiple sources.
What is a big data framework?
A big data framework is a collection of software components that can be used to build a distributed system for the processing of large data sets, comprising structured, semistructured or unstructured data. These data sets can be from multiple sources and range in size from terabytes to petabytes to exabytes.
Such frameworks often play a part in high-performance computing (HPC), a technology that can address difficult problems in fields as diverse as materials science, engineering or financial modeling. Finding answers to these problems often lies in sifting through as much relevant data as possible.
The most well-known big data framework is Apache Hadoop. Other big data frameworks include Spark, Kafka, Storm and Flink, which are all -- along with Hadoop -- open source projects developed by the Apache Software Foundation. Apache Hive, originally developed by Facebook, is also a big data framework.
What are the advantages of Spark over Hadoop?
The chief components of Apache Hadoop are the Hadoop Distributed File System (HDFS) and a data processing engine that implements the MapReduce program to filter and sort data. Also included is YARN, a resource manager for the Hadoop cluster.
Apache Spark can also run on HDFS or an alternative distributed file system. It was developed to perform faster than MapReduce by processing and retaining data in memory for subsequent steps, rather than writing results straight back to storage. This can make Spark up to 100 times faster than Hadoop for smaller workloads.
However, Hadoop MapReduce can work with much larger data sets than Spark, especially those where the size of the entire data set exceeds available memory. If an organization has a very large volume of data and processing is not time-sensitive, Hadoop may be the better choice.

Spark is better for applications where an organization needs answers quickly, such as those involving iterative or graph processing. Also known as network analysis, this technology analyzes relations among entities such as customers and products.
What is the difference between Hadoop and Kafka?
Apache Kafka is a distributed event streaming platform designed to process real-time data feeds. This means data is processed as it passes through the system.
Like Hadoop, Kafka runs on a cluster of server nodes, making it scalable. Some server nodes form a storage layer, called brokers, while others handle the continuous import and export of data streams.
Strictly speaking, Kafka is not a rival platform to Hadoop. Organizations can use it alongside Hadoop as part of an overall application architecture where it handles and feeds incoming data streams into a data lake for a framework, such as Hadoop, to process.

Because of its ability to handle thousands of messages per second, Kafka is useful for applications such as website activity tracking or telemetry data collection in large-scale IoT deployments.
What is the difference between Kafka and Spark?
Apache Spark is a general processing engine developed to perform both batch processing -- similar to MapReduce -- and workloads such as streaming, interactive queries and machine learning (ML).
Kafka's architecture is that of a distributed messaging system, storing streams of records in categories called topics. It is not intended for large-scale analytics jobs but for efficient stream processing. It is designed to be integrated into the business logic of an application rather than used for batch analytics jobs.
Kafka was originally developed at social network LinkedIn to analyze the connections among its millions of users. It is perhaps best viewed as a framework capable of capturing data in real time from numerous sources and sorting it into topics to be analyzed for insights into the data.
That analysis is likely to be performed using a tool such as Spark, which is a cluster computing framework that can execute code developed in languages such as Java, Python or Scala. Spark also includes Spark SQL, which provides support for querying structured and semistructured data; and Spark MLlib, a machine learning library for building and operating ML pipelines.

Other big data frameworks
Here are some other big data frameworks that might be of interest.
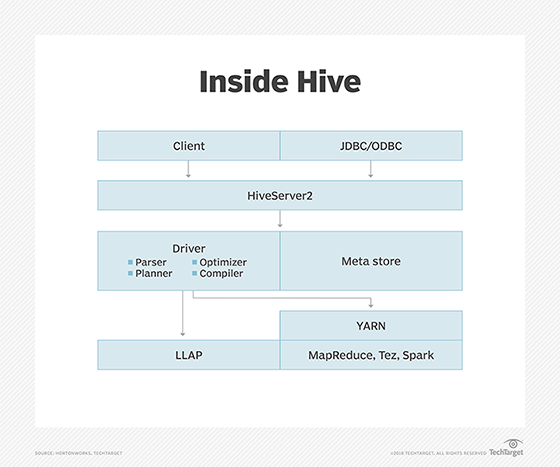
Apache Hive enables SQL developers to use Hive Query Language (HQL) statements that are similar to standard SQL employed for data query and analysis. Hive can run on HDFS and is best suited for data warehousing tasks, such as extract, transform and load (ETL), reporting and data analysis.
Apache Flink combines stateful stream processing with the ability to handle ETL and batch processing jobs. This makes it a good fit for event-driven workloads, such as user interactions on websites or online purchase orders. Like Hive, Flink can run on HDFS or other data storage layers.
Apache Storm is a distributed real-time processing framework that can be compared to Hadoop with MapReduce, except it processes event data in real time while MapReduce operates in discrete batches. Storm is designed for scalability and a high level of fault tolerance. It is also useful for applications requiring a rapid response, such as detecting security breaches.







