
Getty Images
Top considerations for HPC infrastructure in the data center
Determine whether HPC is right for your organization by understanding the compute, software and facilities requirements and limitations for supporting HPC infrastructure.

High-performance computing arose decades ago as an affordable and scalable method for tackling difficult math problems. Today, many organizations turn to HPC to approach complex computing tasks such as financial risk modeling, government resource tracking, spacecraft flight analysis and many other "big data" projects.
HPC combines hardware, software, systems management and data center facilities to support a large array of interconnected computers working cooperatively to perform a shared task too complex for a single computer to complete alone. Some businesses might seek to lease or purchase their HPC, and other businesses might opt to build an HPC infrastructure within their own data centers.
By understanding the major requirements and limiting factors for an HPC infrastructure, you can determine whether HPC is right for your business and how best to implement it.
What is HPC?
Generally speaking, HPC is the use of large and powerful computers designed to efficiently handle mathematically intensive tasks. Although HPC "supercomputers" exist, such systems often elude the reach of all but the largest enterprises.
Instead, most businesses implement HPC as a group of relatively inexpensive, tightly integrated computers or nodes configured to operate in a cluster. Such clusters use a distributed processing software framework -- such as Hadoop and MapReduce -- to tackle complex computing problems by dividing and distributing computing tasks across several networked computers. Each computer within the cluster works on its own part of the problem or data set, which the software framework then reintegrates to provide a complete solution.
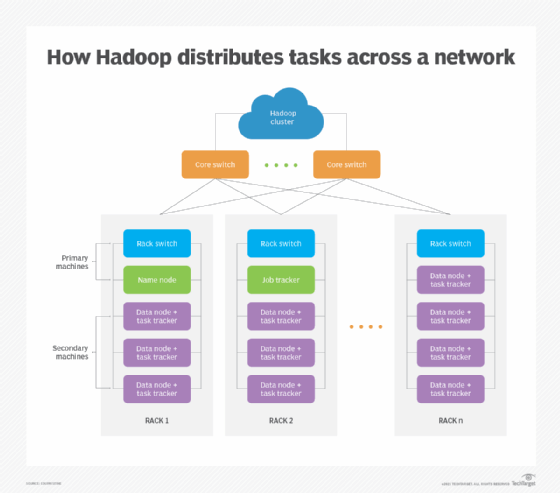
Distributed HPC architecture poses some tradeoffs for organizations. The most direct benefits include scalability and cost management. Frameworks like Hadoop can function on just a single server, but an organization can also scale them out to thousands of servers. This enables businesses to build an HPC infrastructure to meet its current and future needs using readily available and less expensive off-the-shelf computers. Hadoop is also fault-tolerant and can detect and separate failed systems from the cluster, redirecting those failed jobs to available systems.
Building an HPC cluster is technically straightforward, but HPC deployments can present business challenges. Even with the ability to manage, scale and add nodes over time, the cost of procuring, deploying, operating and maintaining dozens, hundreds or even thousands of servers -- along with networking infrastructure to support them -- can become a substantial financial investment. Many businesses also have limited HPC needs and can struggle to keep an HPC cluster busy, and the money and training a business invests in HPC requires that deployment to work on business tasks to make it worthwhile.
Only a thorough understanding of use cases, utilization and return on investment metrics lead to successful HPC projects.
What does it take to implement HPC?
The three principal requirements for implementing an HPC cluster in a business data center include computing hardware, the software layer and facilities to house it all. More exact requirements depend on the scale of the HPC deployment.
Compute requirements. Building an HPC cluster requires servers, storage and a dedicated network that should not share the everyday business traffic LAN. In theory, you can implement HPC software such as Hadoop on a single server, which can help staff learn and gain experience with HPC software and job scheduling. However, a typical HPC cluster based on Hadoop uses a minimum of three servers: a primary node, a worker node and a client node.
You can scale up that simple model with multiple primary nodes that each support many worker nodes, which means the typical HPC deployment consists of multiple servers -- usually virtualized to multiply the number of effective servers available to the cluster. The dedicated cluster network also requires high-bandwidth TCP/IP network gear such as Gigabit Ethernet, NICs and switches. The number of servers and switches depends on the size of the cluster, as well as the capability of each server.
A business new to HPC often starts with a limited hardware deployment scaled to just a few racks, and then scales out the cluster later. You can limit your number of servers and switches by investing in high-end servers with ample processors and storage, which leads to more compute capacity in each server.
Software requirements. Mature stacks must readily support the suite of HPC cluster management functions. Software stacks such as Bright Cluster Manager and OpenHPC typically include an assortment of tools for cluster management, including:
- Provisioning tools
- Monitoring tools
- Systems management tools
- Resource management tools
- MPI libraries
- Math libraries
- Compilers
- Debuggers
- File systems
Some organizations might adopt an HPC framework such as the Hadoop framework to manage their HPC. Hadoop includes components such as the HDFS file system, Hadoop Common, MapReduce and YARN, which offer many of the same functions listed above.
HPC projects require an output, which can take the form of visualization, modeling or other reporting software to deliver computing results to administrators. Tools like Hunk, Platfora and Datameer visualize Hadoop data, and open source tools such as Jaspersoft, Pentaho and BIRT; business intelligence tools such as Cognos, MicroStrategy and QlikView; and charting libraries, including Rshiny, D3.js and Highcharts, can visualize output for non-Hadoop frameworks.
Facilities requirements. Facilities can often become the most limiting factor in HPC. To implement HPC, you require the physical floor space and weight support to hold racks of additional servers, power to operate them and adequate cooling capacity to manage heat. Some businesses simply might not have the space and cooling infrastructure to support a substantial number of additional servers.
Hyper-converged infrastructure systems can minimize physical computing footprints, but HCI carries high-power densities that can result in rack "hot spots" and other cooling challenges. A full compute rack intended for HPC deployment can include up to 72 blade-style servers and five top-of-rack switches, weighing in total up to 1,800 pounds and demanding up to 43 kW of power.
HPC deployments require a careful assessment of data center facilities and detailed evaluations of system power and cooling requirements versus capacity. If the facilities are inadequate for an HPC deployment, you must seek alternatives to in-house HPC.
Handling HPC implementation challenges
Compute challenges. Although HPC hardware is familiar and readily available, you can address compute limitations with modular high-density servers. A modular design makes servers easy to expand and replace. You can achieve the best performance using dedicated high-performance servers with a dedicated high-speed LAN, which enables you to update HPC programs over time through regular technology refresh cycles and additional investment.
Software challenges. The principle HPC software challenges lie in managing software component versions and interoperability, i.e., ensuring that patching or updating one component does not adversely impact the stability or performance of other software components. Make testing and validation a central part of your HPC software update process.
Facilities challenges. Available physical data center space, power and cooling required to handle additional racks filled with servers and network gear limit many organizations hoping to implement HPC. Server upgrades can help. By deploying larger and more capable servers to support additional VMs, you can effectively add more HPC "nodes" without adding more physical servers. In addition, grouping VMs within the same physical server can ease networking issues because VMs can communicate within the server without passing traffic through the LAN.
You can look to third-party options such as colocation for additional space. Colocation enables your organization to rent space in a provider's data centers and use that provider's power and cooling. However, colocation often demands a costly long-term contractual obligation that can span years.
Power costs also affect the long-term costs of an HPC deployment, so evaluate the availability and cost of local power. Consider balanced three-phase electrical distribution infrastructure and advanced power distribution gear -- such as smart PDUs and switched PDUs -- to increase power efficiency. Uninterruptible power supply units support orderly server shutdowns of HPC clusters to minimize data loss.
Adding racks of high-density servers can add a considerable cooling load to a data center's air handling system. When additional cooling isn't available, evaluate colocation or cloud options, or consider advanced cooling technologies such as immersion cooling for HPC racks.
Using the cloud for HPC?
Several public cloud providers, including AWS, Google Cloud Platform and Microsoft Azure, offer HPC services for businesses daunted by the challenges of building and operating HPC. Public clouds overcome scale and cost challenges for individual businesses, which often makes them ideal for HPC tasks. Clouds can provide:
- almost unlimited scale through globally available data centers;
- a variety of dedicated CPU, GPU, field-programmable gate array and fast interconnect hardware capabilities to optimize job performance for tasks like machine learning, visualization and rendering;
- mature and readily available HPC services such as Azure CycleCloud and Apache Hadoop on Amazon EMR, which lessen the learning curve and support burden on local IT staff; and
- pay-as-you-go cost models that enable a business to only pay for HPC when it actually uses those cloud services and resources.
Businesses with frequent and modest HPC tasks can choose to build and maintain a limited HPC cluster for the convenience and security of local data processing projects and still turn to the public cloud for occasional more demanding HPC projects that they cannot support in-house.






