data ingestion

What is data ingestion?
Data ingestion is the process of obtaining and importing data for immediate use or storage in a database. To ingest something is to take something in or absorb something.
Data can be streamed in real time or ingested in batches. In real-time data ingestion, each data item is imported as the source emits it. When data is ingested in batches, data items are imported in discrete chunks at periodic intervals of time. The first step in an effective data ingestion process is to prioritize the data sources. Individual files must be validated and data items routed to the correct destinations.
When numerous big data sources exist in diverse formats, the sources may number in the hundreds and the formats in the dozens. In this situation, it is challenging to ingest data at a reasonable speed and process it efficiently. To that end, vendors offer software to automate the process and tailor it to specific computing environments and applications.
When data ingestion is automated, the software used may include data preparation capabilities. These features structure and organize data so it can be analyzed right away or later using business intelligence (BI) and business analytics programs.
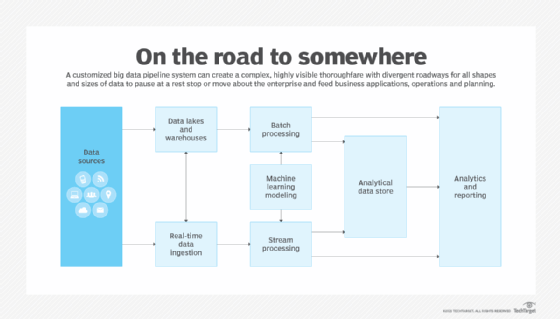
Types of data ingestion
There are a few main ways to ingest data:
- Batch processing. In batch processing, the ingestion layer collects data from sources incrementally and sends batches to the application or system where the data is to be used or stored. Data can be grouped based on a schedule or criteria, such as if certain conditions are triggered. This approach is good for applications that don't require real-time data. It is typically less expensive.
- Real-time processing. This type of data ingestion is also referred to as stream processing. Data is not grouped in any way in real-time processing. Instead, each piece of data is loaded as soon as it is recognized by the ingestion layer and is processed as an individual object. Applications that require real-time data should use this approach.
- Micro batching. This is a type of batch processing that streaming systems like Apache Spark Streaming use. It divides data into groups, but ingests them in smaller increments that make it more suitable for applications that require streaming data.
The components of an organization's data strategy and its business requirements determine the data ingestion method it uses. Organizations choose their model and data ingestion tools in part based on the data sources they use and how quickly they will need access to the data for analysis.
Data ingestion tools and features
Data ingestion tools come with a range of capabilities and features, including the following:
- Extraction. The tools collect data from a variety of sources, including applications, databases and internet of things devices.
- Processing. The tools process data so it's ready for the applications that need it right away or for storage for later use. As mentioned earlier, a data ingestion tool may process data in real time or in scheduled batches.
- Data types. Many tools can handle different types of data, including structured, semistructured and unstructured data.
- Data flow tracking and visualization. Ingestion tools typically provide users with a way to visualize the flow of data through a system.
- Volume. These tools usually can be adjusted to handle larger workloads and volumes, and scale as the needs of the business change.
- Security and privacy. Data ingestion tools come with a variety of security features, including encryption and support for protocols such as Secure Sockets Layer and HTTP over SSL.
Benefits of data ingestion
Data ingestion technology offers the following benefits to the data management process:
- Flexibility. Data ingestion tools are capable of processing a range of data formats and a substantial amount of unstructured data.
- Simplicity. Data ingestion, especially when combined with extract, transform and load (ETL) processes, restructures enterprise data to predefined formats and makes it easier to use.
- Analytics. Once data is ingested, businesses can use analytical tools to draw valuable BI insights from a variety of data source systems.
- Application quality. Insights from analyzing ingested data enable businesses to improve applications and provide a better user experience.
- Availability. Efficient data ingestion helps businesses provide data and data analytics faster to authorized users. It also makes data available to applications that require real-time data.
- Decision-making. Businesses can use the analytics from ingested data to make better tactical decisions and reach business goals more successfully.
Challenges of data ingestion and big data sets
Data ingestion also poses challenges to the data analytics process, including the following:
- Scale. When dealing with data ingestion on a large scale, it can be difficult to ensure data quality and ensure the data conforms to the format and structure the destination application requires. Large-scale data ingestion can also suffer from performance challenges.
- Security. Data is typically staged at multiple points in the data ingestion pipeline, increasing its exposure and making it vulnerable to security breaches.
- Fragmentation and data integration. Different business units ingesting data from the same sources may end up duplicating one another's efforts. It can also be difficult to integrate data from many different third-party sources into the same data pipeline.
- Data quality. Maintaining data quality and completeness during data ingestion is a challenge. Checking data quality must be part of the ingestion process to enable accurate and useful analytics.
- Costs. As data volumes grow, businesses may need to expand their storage systems and servers, adding to overall data ingestion costs. In addition, complying with data security regulations adds complexity to the process and can raise data ingestion costs.
Data ingestion vs. ETL
Data ingestion and ETL are similar processes with different goals.
Data ingestion is a broad term that refers to the many ways data is sourced and manipulated for use or storage. It is the process of collecting data from a variety of sources and preparing it for an application that requires it to be in a certain format or of a certain quality level. In data ingestion, the data sources are typically not associated with the destination.
Extract, transform and load is a more specific process that relates to data preparation for data warehouses and data lakes. ETL is used when businesses retrieve and extract data from one or more sources and transform it for long-term storage in a data warehouse or data lake. The intention often is to use the data for BI, reporting and analytics.
Data ingestion gives businesses the intelligence necessary to make all types of informed decisions. Learn how companies use data-driven storytelling to make information valuable to their business.