What alternatives to HTTP are there for microservices?
Using HTTP as the bus for traffic between microservices can create some unwanted impacts, including more TCP/IP overhead. Mark Betz goes over some useful alternatives to HTTP.
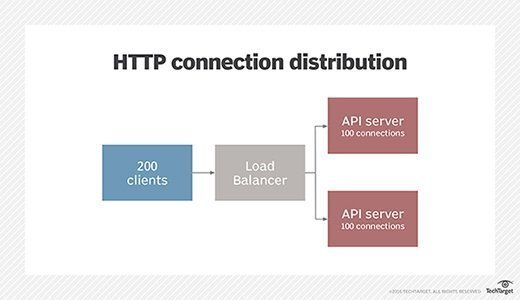
The default model for most service-oriented architectures is to have a set of monolithic application servers handling HTTP connections forwarded by a load balancer. This approach works well and uses a protocol and supporting infrastructure with which virtually all software engineers have at least a passing familiarity. In this model, using a round-robin load balancing scheme to send requests to a pool of two servers, each server will handle approximately half of the concurrent request load. Figure 1 shows such a scenario.
HTTP requires that a connection be held open for the duration of a request until a response is received or until the connection closes due to a timeout or error. One way of evaluating the overhead of this scheme is to look at the total number of open connections that must be maintained to handle a particular volume of requests. As can be seen in Figure 1, this architecture requires a total of 400 open connections to service 200 concurrent client requests: 200 between clients and the load balancer and 200 between the load balancer and the server pool.
Figure 1. Connection distribution using HTTP load balancing and round-robin request routing.
And then there were microservices ...
The architecture in Figure 1 is probably still the most common approach taken by small- to medium-scale sites being developed and maintained by small teams, and it can perform very well. When the application has to scale in terms of request volume, and the engineering processes have to scale in terms of team size and organization, the next step is often to begin decomposing the service API implementations into more granular pieces: the microservices approach.
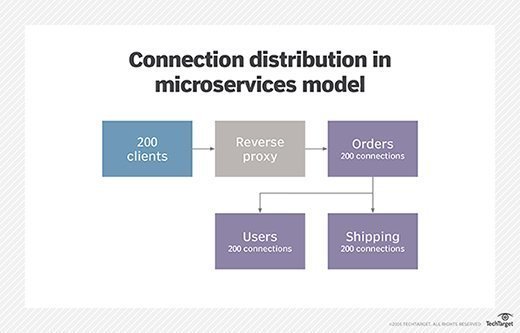
This model quickly introduces more connection paths into the flow of traffic on the back end, as it is usually inevitable that individual services will have to communicate among themselves. Figure 2 shows one such scenario.
Figure 2. Connection distribution in a microservices model.
In this scenario, the client finalizes an order, which requires the Orders service to first verify the client authentication and fetch user properties from the Users service, and then contacts the Shipping service to schedule delivery. Since the lifetime of each connection is shorter and caching can reduce the number of requests, comparing this to the monolithic approach is not as simple as counting open connections. But, clearly, one impact of using HTTP as the bus for traffic between microservices is more TCP/IP overhead.
One impact of using HTTP as the bus for traffic between microservices is more TCP/IP overhead.
Mark Betz
Another impact comes from the nature of the Internet Protocol itself: In order to get a packet of data to a port on a particular server, you need to know the server's network address before connecting. The reason for this is to increase infrastructural rigidity by requiring servers to have known addresses, a problem that is difficult to reconcile with performance and durability enhancements like autoscaling and failover.
The alternative, and a much more flexible approach, is Service Discovery, which, in a nutshell, simply means that each server reports its network address to some central repository of system state that can be read by internal clients. This is the mechanism of choice for container clustering platforms like Kubernetes and Docker Swarm. It's reliable, but it is a little bit intrusive, as each service implementation must know how to interact with the service discovery framework as well as with the other services in the cluster.
The alternatives to HTTP
Many of these issues can be mitigated by using alternatives to HTTP for inter-service requests. The two most common alternatives are most likely Remote Procedure Calls (RPCs) and message queueing (AMQP).
RPCs are conceptually closer to HTTP in operation and, thus, a little less interesting in the context of this tip. RPCs typically employ a more efficient binary, over the wire data format than text-oriented HTTP requests. But, beyond that, many of the same issues discussed above persist: You may still create a large number of connections between services when handling a high volume of requests, and some form of service discovery is still required so that the addresses of servers are known to the clients at runtime.
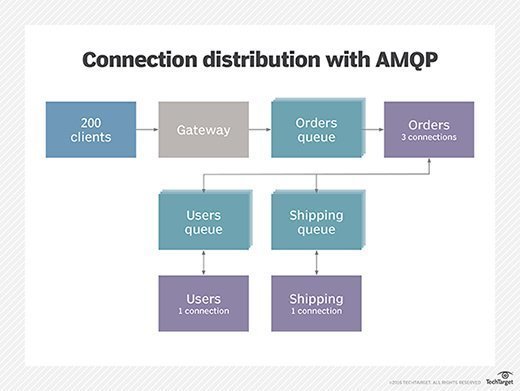
By contrast, AMQP is a completely different way of looking at the nature of communication between back-end services. In place of the connection-oriented request/response, AMQP substitutes asynchronous messages and replies. And, instead of establishing direct routed connections between clients and services, a message broker manages queues into which messages are posted. Services then receive the messages from the queues, process them and return the responses to a reply queue. Figure 3 depicts the order finalization transaction described above using message brokers as alternatives to HTTP.
Figure 3. Connection distribution in a microservices model using AMQP queues.
This may be an over-simplified example, but it serves to clarify the conceptual differences. In this scenario, the component labelled "gateway" is a client of the message broker, as are each of the individual services. The gateway is responsible for terminating HTTP connections, translating requests into messages, posting them into the appropriate queue and then waiting for the reply to come back before translating it into an HTTP response to complete the lifecycle.
Using message queues to decouple clients and services in this way has a few distinct advantages.
The number of connections between services no longer scales directly with the volume of requests. Think of pools of database connections rather than open connections to an HTTP server.
There is no need for active service discovery: Services connect to their designated queue at startup and begin processing messages.
AMQP brokers accommodate efficient, over the wire formats like protocol buffers, meaning you can minimize the amount of bandwidth used.
You can couple a message broker, like RabbitMQ, with a worker framework, like Celery, to get autoscaling based on queue congestion and other metrics.
Another significant, though subtler, advantage is that the asynchronous nature of messaging is a natural fit for single-threaded, event-driven servers. Much more detail would be out of place here, but, in a nutshell, the preferred strategy for handling large numbers of connections in modern servers is single-threaded, non-blocking and event-driven.
In this model, it is important that services not use the main thread to make long-running blocking calls to other systems. You need to keep everything moving at all times, and message queuing handles this kind of control flow very elegantly. The requesting thread posts a message to a queue and either polls or gets a callback when a response is received. In the meantime, the thread is free to work on other requests.
What's the catch?
The trade-off is that you need to implement and maintain the message broker as another high-availability service. If the service goes down, the whole back end grinds to a halt. An increase in complexity is never to be taken lightly, but there are mature packages available that dial the risk back to acceptable levels.
In terms of impact on developers and the code they write, services do need to know how to connect to the queue. They need code to do that, but, unlike the HTTP model, they don't need a control plane separate from the data plane to handle lifecycle events.
Lastly, you need to implement and support the gateway piece described above. There are quite a few third-party and open source possibilities out there, and those offerings will likely continue to mature.