
Getty Images/iStockphoto
Stay online with these 5 AWS disaster recovery best practices
Solve disasters in an AWS deployment by having a disaster recovery strategy in place. Learn how to pick the right recovery methods and prevent more problems.

If AWS is a part of your IT strategy, AWS disaster recovery must be included in your overall DR strategy.
Having a DR plan tailored to AWS ensures that you can minimize data loss and reduce downtime during an incident involving the cloud provider's resources. This ranges from an incident caused by an AWS data center failure to mistakes made by the administrator, such as accidental data deletion or a misconfiguration that causes a crash. AWS disaster recovery planning leads to a better experience for your users, and greater reliability and resilience for the business.
Some aspects of DR planning for AWS aren't that different from DR in any context. Others are specific to AWS and require knowledge of its particular tools or services. To maximize reliability and minimize recovery time when disaster strikes an AWS environment, take these five key steps.
Step 1: Choose the right recovery method
An IT team has several methods for recovering failed workloads in AWS, which are detailed in AWS documentation. These include:
- Backup and restore. AWS cloud admins take regular backups and restore data from these backups after a failure. This approach costs the least because it doesn't require you to host a live backup environment. But it also causes the longest recovery times because you create a recovery environment from scratch.
- Pilot light. This approach uses a minimal backup environment, which is what pilot light signifies, running alongside the production environment. Recovery is a bit faster than it would be if you start from scratch, but the pilot light environment incurs ongoing costs.
- Warm standby. This setup requires a larger-scale backup environment where the IT team can restore services in the event of a failure. But this method is not fully production-ready. Hosting costs are higher for a larger backup environment, but recovery is faster.
- Multisite or active-active. Active-active DR relies on a full backup environment alongside the production environment. Hosting costs are highest in this case, but recovery time is minimal because workloads fail over to the backup environment almost instantly.
The right recovery method for an AWS cloud deployment depends on budget and recovery needs. Invest in a warm standby or multisite/active-active strategy if you have a generous AWS disaster recovery budget. Business decisions about the AWS workloads dictate recovery point objective (RPO) and recovery time objective (RTO).
You can employ multiple AWS recovery methods at the same time. A backup and restore or pilot light approach works for noncritical workloads that can tolerate some downtime. Simultaneously, you can create warm standby or active-active setups for other workloads that must be up and running as quickly as possible. Use all appropriate options to strike a balance between recovery planning cost and performance.
Step 2: Calculate RPO and RTO
Two main calculations should guide the recovery method used:
- RPO. The amount of data loss you can tolerate following an outage without experiencing critical business disruption. RPO is usually measured in terms of time. For example, your RPO could be twenty-four hours' worth of business data.
- RTO. The amount of time that critical systems can be down before they pose a major risk to the business.
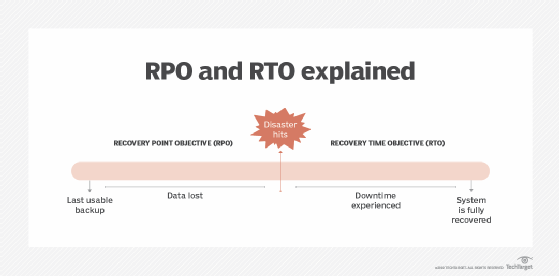
Every business or individual workload has different RPO and RTO requirements. To determine recovery needs, list which workloads the business depends on, and then categorize them according to how important they are to the business. Try labels like essential, very important, important, noncritical and negligible.
Then, consider how long the business could remain operational if the data or applications associated with each workload become lost. The results are the workloads' target RPO and RTO.
AWS workloads with fast RPO and RTO needs are best served by disaster recovery plans that enable rapid restoration in the event of an outage.
Step 3: Make an EC2 backup plan
AWS recommends two approaches to backing up virtual machines running in AWS EC2:
- EBS snapshots. A snapshot of an Elastic Block Store (EBS) volume contains the data inside the EC2 instance.
- AMI backups. Amazon Machine Images (AMIs) contain all the information required to rebuild a failed EC2 instance.
In general, AMI-based backup facilitates the fastest recovery because you don't need to rebuild any configurations to launch a replacement EC2 instance. Everything needed is contained in the AMI.
AMI backup is less flexible and somewhat riskier in some ways. AMIs generate instances that are identical to the EC2 instances on which they're based. That may be a problem if there is trouble within an EC2 instance that causes it to crash. In that case, the restored instance potentially hits the same problems as the one it replaced. You can also run into trouble if the original instance is still running. The original instance and the replacement instance might try to claim the same unique resources within AWS, because their configurations are identical.
In contrast, EBS volumes can attach to any EC2 instance of your choosing. You can restore the data for a failed instance but use a different configuration for the instance with EBS backups.
Consider using both EBS snapshots and AMI backups at the same time. That way, you can recover EC2 instances using whichever approach makes the most sense in a given scenario. However, opting for both backups means taking on storage costs and operational effort.
Tag EC2 backups to manage them effectively. Also, implement a lifecycle management process that deletes outdated backups to save space and storage costs when they're no longer needed.
Step 4: Use AWS backup automation
You can manage AWS disaster recovery manually, but the best AWS DR plans use automation to ensure that recovery processes are as fast and smooth as possible.
A key tool for this purpose is AWS Backup, a centralized policy-based approach to managing backup and recovery operations for a variety of AWS resources. The tool doesn't cover every type of AWS service, but it addresses the main ones. These are services like EC2 instances and most AWS databases. It can back up resources automatically and perform automated restores.
Amazon Route 53 Application Recovery Controller is a complementary AWS backup and recovery tool. This tool is especially useful for workloads with complex networking configurations. It automatically assesses recovery and failover plans. Use it to make sure that a pilot light, warm standby or active-active recovery environment is the right way to restore a failed workload given business expectations.
AWS' native backup tools only work within AWS. If you need to back up other environments in addition to AWS, consider third-party backup automation solutions. However, third-party backup tools that do not store data on AWS have a flaw. If backup data is not stored on AWS, you'll have to transfer it over the internet in order to recover the workloads. That can take a long time -- hours or, possibly, days -- for large volumes of data. In some cases, third-party backup tools let you back up AWS data directly within AWS, which will speed recovery.
Step 5: Test and manage any AWS recovery plan
Test your AWS recovery plans regularly to ensure they work as required.
The most straightforward way to test recovery plans is a simulation. Create a scenario where a critical workload fails and execute your plan for recovering it based on the available backups. Run through drills like this at least a few times a year. Do it more often for critical workloads.
Also consider running file-system checks on backup data to search for corruptions or other problems that could disrupt recovery. Use tools like Route 53 Application Recovery Controller to evaluate recovery readiness for supported workloads.
Update recovery plans over time. Reassess RTO and RPO at least once or twice a year and more often if workloads or business requirements change frequently. If a workload becomes more critical to business operations over time, for example, it might need to change from backup-and-restore procedures to a warm standby setup.
An AWS disaster recovery plan could involve much more than the basic steps described above. Particular workloads -- such as those involving Kubernetes, containers or serverless functions -- require extra planning to ensure fast recovery of the unique resources at stake. No matter the workload or technologies in use, the backup and recovery strategy should start with the basics. Define RTO and RPO needs and develop recovery methodologies and EC2 backup approaches that align with those needs.
Dig Deeper on Cloud infrastructure design and management
-
![]()
Choosing the right AWS disaster recovery strategy in 2026
By: Wisdom Ekpotu
-
![]()
Certified Professional AWS Solutions Architect Exam Braindumps
By: Cameron McKenzie
-
![]()
AWS Solutions Architect Professional Sample Exams
By: Cameron McKenzie
-
![]()
AWS Solutions Architect Associate Exam Questions
By: Cameron McKenzie



