
Getty Images/iStockphoto
How cost and complexity factor into AWS DR strategies
To choose the right AWS disaster recovery plan, understand how much downtime your business can tolerate -- and how DR scenarios affect your monthly costs.

As reliable as they can be, cloud services inevitably fail -- which makes disaster recovery essential.
When building a disaster recovery (DR) plan, AWS users must determine how much they are willing to spend, in terms of both time and money, to get their desired DR results. They must also understand AWS Availability Zones (AZs) and Regions, and how those concepts play into DR.
Levels of DR in AWS
There are four levels of DR protection in AWS. According to the cloud provider, those options vary, in terms of cost and complexity. They are listed below, starting with the least costly and complex option and becoming increasingly more expensive and complex:
- Backup and restore. Admins typically choose this option for DR requirements such as minimizing data loss. Items are restored hours or days after the DR event occurs due to cold storage retrieval.
- Pilot light. This option replicates data from one AWS Region to another. It also provisions a copy of the underlying application infrastructure, but resources, such as servers, are only turned on for testing or failover. There is some downtime, but workloads are back online fairly quickly, in minutes to hours depending on how much data was replicated.
- Warm standby. This option maintains a scaled-down version of your production environment in another AWS Region. The downtime is minimal, typically minutes, because the workloads remain functional in the other Region.
- Multi-site active/active. With this option, users run workloads in multiple AWS Regions simultaneously, ensuring little or no service interruption. While it is the most complex and expensive option, it can bring recovery times to near zero.
When choosing an AWS DR strategy, assess how much data you can afford to lose, how quickly you need to recover and how much that recovery effort will cost.
How Regions and Availability Zones influence DR
Regions and Availability Zones are a key part of DR initiatives in AWS. A Region is a geographic location in which AWS' data centers reside. An AZ is group of logical data centers within a particular Region.
Many people think of DR as hardware redundancy, and the need to spread workloads across multiple AZs. That is mostly right. An AZ typically consists of multiple data centers that already have built-in redundancy, such as for power supply and networking. However, that doesn't mean data centers in a certain AZ are mirrored clones of each other. Services and data can move between them, but more likely as a form of failover versus being fully in sync. This results in partial -- not full -- redundancy.
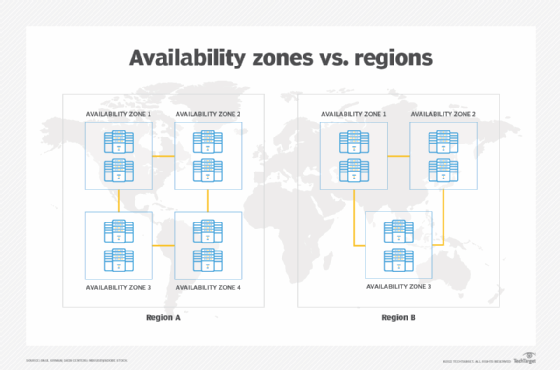
Each AWS Region typically has two or more AZs. If you bridge your application across two AZs, there will be low latency and, therefore, minimal downtime. Each AZ can have multiple redundant data centers for failover, ensuring the zone is protected. A multi-AZ strategy is often used to protect against localized disasters, such as an earthquake or flooding.
If you are concerned about an event that could affect all AZs in a Region, such as a massive power outage on the Eastern Seaboard, you go a step further and bridge across two AWS Regions. However, a multi-Region strategy will create more complexity and costs.
Use automation to reduce costs
An aggressive DR strategy can narrow most redundancy gaps -- but at a price. A duplicate of your environment in another location can double your AWS bill. That's a big expense for something that is waiting to be used rather than actively being used.
This is why infrastructure as code (IaC) is ideal in DR. If your recovery time objective can handle a short outage, why not build the infrastructure for your data only when you need it? Automation can enable infrastructure on demand, when you need it -- rather than in case you need it. This is a much cheaper approach to DR in AWS.
The importance of data replication
Automation and AZs are important elements for AWS disaster planning. That said, these tactics work only if your data is ready -- meaning, you've done the necessary data replication.
For a reasonable level of DR response, data needs to be accessible in a timely manner. You can't pull it from AWS Simple Storage Service Glacier, or other cold storage services, and expect DR automation strategies to work.
You can also use smaller standby environments that always run in a limited active/active scenario. AWS Auto Scaling brings these standby environments to a full production environment without human intervention and with limited downtime. There might be a lag in services during recovery, but the cost savings can be substantial enough to warrant a short performance hit.
Automation via IaC and AWS Autoscaling will, however, require staff time and effort to set up and test.
If a workload demands it, pursue a full multi-AZ strategy. A DR plan doesn't have to be built around a single approach. Applying one DR strategy to all workloads would likely be cost prohibitive and restrictive. Some workloads need a higher level of protection against downtime, and others do not.
As an organization, make DR choices that reflect your priorities and cost preferences -- and adjust them over time.






