Serverless computing creates as much confusion as it does excitement. What it is and how it's applied remains a moving target.
AWS, Microsoft and Google continue to evolve their serverless approaches, as they look to seize on the benefits of reduced overhead and eliminate the current limitations around complex use cases. But for serverless computing to truly take off, it may require a marriage with another technology that some see as the primary alternative to building next-generation applications -- containers.
Serverless computing stands apart from VMs
Cloud computing has traditionally focused on VM-based IaaS. Enterprises leased VMs with certain characteristics and paid cloud providers for their commitment, whether they fully utilized those instances or not. But, in an operational sense, sustaining a cloud VM was about as complicated as sustaining a real server. This traditional approach was a bad fit for some applications due to the combination of Opex burden and the risk of underutilization.
Serverless computing is intended to eliminate both of these issues. Serverless applications use ad hoc capacity, which means they only use resources -- and the business is only charged -- when the application runs. This is the foundational truth of serverless: Infrequently used applications don't require you to spin up a VM, manage it and pay for it in anticipation that it might eventually be called upon. You grab resources when they're needed and release them when they aren't, and you don't really manage them at all.
This model gets complicated when you consider a specific application, like a CRM or payroll app. The application uses CPU and memory cycles while it runs, and sometimes storage or database resources, as well. When it's not in use, it goes away -- the problem is that most applications expect to stay put. They keep information in local variables, and in a serverless model, those variables will also disappear once the application is gone.
The latest trend in cloud computing is to bring serverless distribution tools ... to managed Kubernetes services.
Except, sometimes there aren't any variables. "Functional" or "lambda" computing is a specific model by which components don't store anything internally. The outputs are always a function derived directly and exclusively from the inputs; nothing is saved between executions of the function. You can spin it up anywhere, at any time, and the same inputs will always produce the same result -- they're stateless.
AWS and Microsoft both offer functional computing in serverless form, but these offerings have limited utility. Writing stateless functions to do stateful actions, such as transaction processing, is complex, and serverless functions are most useful when utilization is low, which isn't the case for most business applications.
As a result, Amazon and Microsoft have somewhat softened their serverless approach. They both started their serverless business with the assumption people would write stateless functions, but over time they've added documentation on state control and offered orchestration services to manage state and broaden the viability of serverless.
Google, meanwhile, has taken a softer approach from the start. Google calls the components "microservices" instead of "functions." Those microservices don't have to be truly stateless -- they just can't hold state information in the microservice instance. Google also emphasizes containers over VMs because they have lower overhead and are easier to move. As a result, they can be made to fit a serverless pricing model without all those functional restrictions.
Along came Kubernetes
Microservices and containers, when equipped with an external source of state control, offer a way to create a sliding scale that ranges from container-based apps with lower overhead to applications that are true functions. State control can be provided by the originator of the transaction -- the GUI or app -- as well as a back-end database or an orchestrator. Developers can use the first two options in any cloud, but they have to handle the implementation themselves.
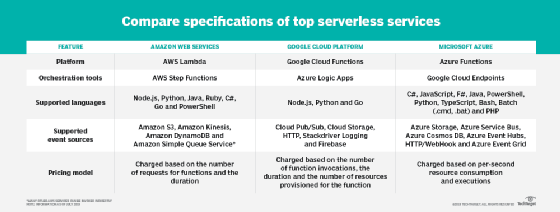
All of the public cloud providers offer orchestration as a feature. AWS Step Functions, Microsoft Azure Logic Apps, Google Cloud Endpoints and Google Cloud Functions all extend stateful application support to functions without demanding a lot of heavy lifting from developers.
Still, it's clear that organizations aren't looking for the kind of pure, on-demand behavior of traditional serverless. Rather, they need a means to support applications with highly elastic, yet regularly utilized, workloads. For this, cloud providers are quietly promoting the concept of a managed container service -- or, more specifically, managed Kubernetes service. These include Amazon Elastic Kubernetes Service, Azure Kubernetes Service and Google Kubernetes Engine.
The benefits of marrying containers and serverless
Containers have much lower overhead than VMs, and managed Kubernetes services can deploy containers as needed. They insulate users from operational details, much like serverless, but they're more practical for the real-world business applications.
The latest trend in cloud computing is to bring serverless distribution tools, including those for step-based orchestration, to managed Kubernetes services. To accomplish this, integrate Kubernetes with a service mesh. The most popular service mesh technology is Istio, which spun out from a project partially supported by Google. Linkerd is another, but it's limited to a mesh add-on that users have to include and support, whereas Istio can be delivered as part of managed Kubernetes service.
Service meshes address the registration and discovery processes needed to deploy, scale and replace services as needed. They provide developers with an elastic pool of resources and containerized components. You don't scale a particular microservice to zero instances, but you can scale it over a wide range, which can greatly reduce the cost of hosting an application with a highly variable workload.
Not every application is a candidate for a managed Kubernetes service, but it's much easier to build and design applications for service-mesh-based scaling than to build functions designed for orchestration. Furthermore, a managed Kubernetes service reduces the risk of major cost overruns if your usage exceeds expectations, while still minimizing operational burdens.
We may find that, for marketing reasons, cloud providers begin to position managed Kubernetes services as serverless. After all, in its strictest sense, "serverless" simply means "without servers" -- which means it can loosely apply to all sorts of cloud services. We've already seen this with database products, such as Amazon Aurora Serverless, and PaaS tools, including Google App Engine.
In addition, cloud providers may adjust their pricing on serverless, step-based orchestration tools, and managed Kubernetes services could change over time as providers try to capitalize on the opportunity. For those who are looking at serverless, or who have been driven from it by unpleasant cost surprises, these trends should offer hope of better things to come.