Where serverless storage fits in the serverless computing world
Storage for serverless functions must be external to the compute environment. Learn about the types of storage that work best for serverless computing.
What is serverless computing and how does serverless storage work? Basically, serverless is a way to develop an application as a set of smaller functional components and then submit those functions to a host service for elastically scalable event-driven execution. The service provider takes care of running, scaling and operating the entire IT stack underneath, freeing the application owner to focus more on business value and less on IT operations.
Because the service provider charges per function execution and not for reserved infrastructure, serverless operating costs fully align with application usage. With serverless, cloud expenses can be traced directly to applications and business users.
Serverless isn't truly without servers; there's a server somewhere in a cloud. Behind the scenes, there are probably virtual machines, containers, servers and storage. There are OS and application server code and layers of IT management that might include cloud orchestration, virtual hosting and container management, such as Kubernetes. The service provider handles all the networking, availability, performance, capacity and scalability issues an IT shop might normally have to be concerned with when hosting its own applications.
Think of it as functions as a service
A better name for all this might be functions as a service. At its simplest, this kind of function is a little piece of event-driven code, perhaps written in JavaScript, that's set up to be invoked in response to some trigger like a web-form submission click or IoT device event. Simple functions could simply insert a record into a database, make a log entry, trigger another event, send a notification message, transform a piece of data or return a calculation.
A complete serverless application would consist of a well-orchestrated cascade of functions. Each function could be independently reused and triggered in massively parallel ways. A function's execution could be scaled orthogonally from other functions providing for tremendous flexibility without traditional bottlenecks.
When a well-designed master graph of functions that trigger each other in a sophisticated cascade of events is deployed at scale, it can not only replace but outperform monolithic applications. One of the premises of serverless is that your applications would scale smoothly and be fully elastic, well beyond the limits of any predefined or prepaid server farm or set of cloud machine instances.
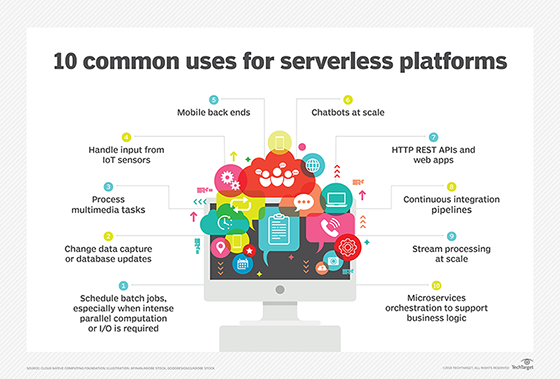
Common uses for serverless platforms
This is still a bit futuristic because, of course, applications aren't made up of just compute functions. There's still data that needs to be managed, protected and persisted. Storage for serverless must be a consideration and effective serverless storage developed.
Storage for serverless
Like microservices in containers, the initial idea for serverless functions is to construct them in ephemerally, so they don't contain any data and aren't relied upon to internally persist data.
If a company is adopting serverless, ultimately, the idea will be to get out of operating and managing storage as well.
Unlike long-running applications, the point is that functions are triggered by an event, do something specific and are retired as opposed to becoming a long-lived application. Serverless functions and may be launched in massively parallel ways to scale quickly to meet demand. So where does serverless data live?
Effectively, data storage for serverless functions must be external to the compute environment. Because of the elastic scaling and small event cascades, traditional storage volumes and file systems are going to struggle mightily and become obvious bottlenecks in large-scale serverless application deployments.
Today, serverless function development environments can make direct use of storage service APIs. As scalable storage suitable for web-scale apps and containerized applications, cloud-data services are ideal data persistence partners. Here are the storage types that work well as storage for serverless:
Cloud database services that are architected for multi-tenancy, elastic scalability and web-style access make them a good choice for transactional persistence.
Object storage services, such as AWS S3, with simple get/put protocols are ideal for many kinds of web-scale apps and functional designs.
Application memory cache, such as Redis, can work for high-performance data sharing needs.
Journaling logs in which data is written serially to the end, while readable in aggregate, can help protect streaming data in functional designs.
When using any data store with serverless designs, great care must be taken with idempotency -- an operation that has no additional effect if applied more than one time. Care must also be taken with asynchronous event assumptions and timing or race conditions. In particular, functional designs have to pay attention to parallel data updates and write-locking conditions.
So what exactly is serverless storage?
The serverless ideal is to get IT -- and DevOps -- out of managing and operating servers of any kind, including physical servers, virtual servers, containers and cloud instances. The idea is to force IT to hand over the responsibility to be on call for any operational issue to the serverless environment provider. If a company is adopting serverless, ultimately, the idea will be to get out of operating and managing storage as well.
However, common requirements for IT to ensure data governance, compliance and protection will mean a long period of hybrid protected storage architectures. And in the long term? Data could just be passed forward from function to function through the event queue and never actually persisted, relying on the event queuing service for data protection. But, of course, there's still storage in there somewhere.