
Denned - Fotolia
Essential serverless concepts to master before deployment
Serverless computing can be incredibly beneficial -- but easily misunderstood. Before adoption, have a clear understanding of proper use cases and app design principles.

Initially, cloud services merely mirrored the virtual compute, storage and network resources of enterprise data centers. But cloud providers have increasingly abstracted away resources from their users through new packaged platforms and application services -- most recently, serverless computing.
Each rung on the ladder of software abstraction gives development and IT teams more flexibility, features and convenience. IT shops that are open to a potential change in their underlying application architecture can adopt serverless to reduce costs and increase scalability.
However, to reap these benefits, IT admins and DevOps practitioners first need to understand some overarching serverless concepts -- in terms of application requirements, key use cases and more. This article fills in some common knowledge gaps and provides general guidelines to incorporate serverless into application workflows.
First, what does serverless mean?
The term serverless is both a misnomer -- there are always servers involved in any cloud service -- and one that's conflated mistakenly with event-driven functions as a service (FaaS), such as AWS Lambda and Google Cloud Functions. While FaaS is the most familiar example of a serverless product, it's just one type. As AWS details in a paper on serverless architectures, any cloud service that meets the following criteria is, from the user's perspective, effectively serverless:
- Requires no server management. The cloud provider handles server provisioning, software installation, updates and maintenance.
- Provides flexible scaling. The service automatically provides more capacity -- whether in CPU, I/O, transaction throughput or memory and storage space -- in response to increased demand. The service scales capacity down automatically as demand wanes.
- Is highly available. The service has a fault-tolerant underlying infrastructure and design.
- Offers usage-based pricing. The user doesn't provision and pay for unused capacity. Instead, the cloud provider charges based on granular measurements of resource usage over a given time period.
This broader definition of serverless encompasses many types of cloud services, including compute via serverless functions, such as AWS Lambda, Azure Functions and Google Cloud Functions. Functions execute on demand in response to some event or preset schedule.
When IT organizations combine serverless offerings to build cloud-optimized applications, they can provide reliable, scalable capacity on demand at a much lower cost than traditional virtual infrastructure.
Serverless use cases
IT teams are still in the early stages of serverless usage and experimentation. However, in several scenarios, serverless has already proven to be a compelling alternative to traditional application design methods. These include:
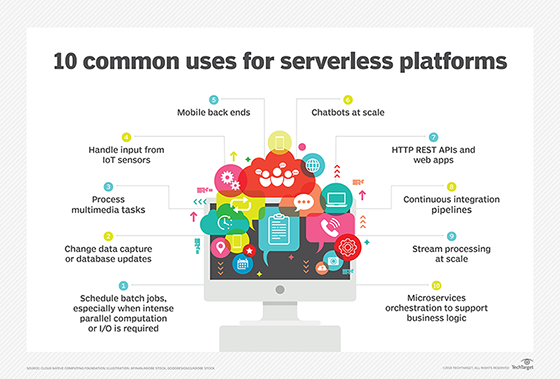
- RESTful microservices accessed via external API gateways or load balancers.
- Web applications that use FaaS for dynamic content, serverless storage for static content, a serverless database for transactions and persistence, an API gateway, and/or an application delivery controller to broker client access.
- Streaming data ingestion and analytic processing through a service like Amazon Kinesis to read and aggregate real-time data asynchronously from smart devices or other external sources. In this use case, serverless functions handle application logic and call analytics services for processing before passing results to a serverless database or data warehouse.
- Batch processing, such as cron for the cloud.
- Event workflows and process automation to sequence and coordinate microservices in an application or a set of administrative tasks, such as application patching or code testing and deployment.
- Chatbots and smart device back ends that use serverless functions to respond to a chat or deliver services.
- Mobile app back ends that use techniques such as those for smart devices or web applications to implement application logic, process transactions and interface with storage and other services.
Serverless concepts for application design
As a general rule, event-driven applications are the best fit for serverless deployments. To extend the model to other applications, rethink workflows to focus on the sequence of application events and processing steps.
First, decompose applications into a set of independent RESTful functions, or microservices. Make these microservices as small as possible, focused on only one task or capability. Expose functions via APIs that respond to incoming requests -- i.e., events -- and provide results asynchronously. Treat code functions as the basic unit of compute deployment and scaling to minimize, or eliminate, static VMs or containers for application logic.
Parallelize long-running algorithms or functions to enable simultaneous execution across multiple FaaS instances with results aggregated to external storage. Use the aggregator, proxy or chained microservices design pattern as a model.
Microservices design patterns for serverless apps
Serverless applications typically use one of the following microservices design patterns:
- Simple web service or Gatekeeper
- Scalable webhook
- Internal API broker
- Aggregator or a similar service proxy
- Stream processor
- State machine
- Router
- Fan-out/fan-in
- Circuit breaker
Don't write custom code when there is a comparable cloud service available. For example, outside of AI research or data science, developers shouldn't write custom functions for natural language processing, image recognition, speech transcription, chatbots or email processing. Likewise, IT admins shouldn't worry about redundancy, service distribution and load balancing, as the underlying serverless platform incorporates high availability and fault tolerance.
Decouple executable code and storage via APIs to external storage or database services for persistence. Keep code agnostic to the hardware platform or CPU instruction set. Don't rely on hardware affinity, because the cloud provider can -- and will -- move compute, storage, databases and API platforms between systems and data centers.
Lastly, build telemetry and measurability into all modules and use APIs for monitoring services, such as AWS CloudWatch or Azure Monitor, to collect results for later analysis.
Manage serverless apps
Other essential serverless concepts apply to how IT teams manage functions. For example, define function service limits -- such as memory allocation, timeouts, concurrent executions and execution time -- and determine how serverless apps will handle data input, connections and persistence. In addition, establish security privileges and interface serverless apps to an external user directory, such as Active Directory, or identity and access management service.





