
WavebreakmediaMicro - Fotolia
Learn from these real-world AWS serverless examples
Check out how Equinox Media and BMW use AWS serverless tools and technologies to process and analyze data as part of their IT strategies.

Serverless computing continues to rise in popularity as IT teams seek to build more agile applications. Developers use it to focus more on code and less on the software and hardware, and they view serverless as a must for scalability and cost savings.
AWS has a robust serverless portfolio, with tools such as AWS Lambda, AWS Fargate and AWS Step Functions. In the two real-world serverless examples below, we'll look at how companies are using AWS -- and serverless architecture patterns -- to process and analyze data.
Serverless infrastructure and analytics at Equinox Media
As explored in the 2020 AWS re:Invent session "Serverless analytics at Equinox Media: Handling growth during disruption," Equinox used a data lake strategy and serverless resources to launch a new fitness platform VARIS and a stay-at-home SoulCycle bike.
Equinox built these technologies from the ground up, so it made sense to use serverless cloud technologies, said Elliott Cordo, who was VP of technology insights at Equinox Media at the time of the talk. The company decided to use Amazon Kinesis for real-time data streaming, AWS Lambda for its event-driven architecture, AWS Glue to load data, Amazon DynamoDB to house the data and Amazon Athena to analyze it.
Equinox chose serverless because of its scalability and cost. When dealing with an unknown usage pattern, serverless is more cost-effective because you don't have to guess and provision infrastructure you might not use, Cordo said. In terms of data analytics, serverless was the best fit because VARIS relies on machine learning recommendations to drive its user experience. Serverless data analytics continuously feeds the platform's recommendation APIs.
Let's dig into some of the AWS serverless architecture patterns at work in this example.
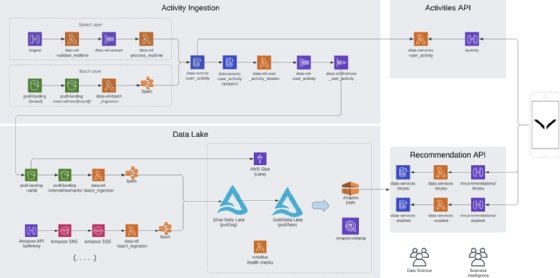
This design includes four interconnected elements: activities ingestion, data lake, activities API and recommendation API. These elements connect to each other, as well as to user devices. Cordo calls it a "data-lake-first strategy." The data lake is the sole version of truth and is built to ingest both raw and processed data, as well as accommodate multiple processing engines.
In Figure 1, data is ingested in two ways:
Speed layer. This is for scalable, event-based extract, transform, load (ETL) storage. Amazon API Gateway ingests the data and a Lambda API validates it. Data is then moved through the ETL stream and enters the DynamoDB activities layer, where it's processed through Kinesis Data Firehose and ultimately enters the data lake.
Batch layer. This layer handles flat and JSON files. Equinox set up a queuing system called Queubrew to handle the data. Queubrew uses API Gateway, Lambda and a PostgreSQL version of Amazon Relational Database Service (RDS) for persistence -- the RDS instance being the only nonephemeral resource in the data platform.
The RDS files enter the batch layer from an external landing Amazon S3 bucket, then they're copied via Lambda, run through Queubrew and moved through the DynamoDB activities layer, like the speed layer.
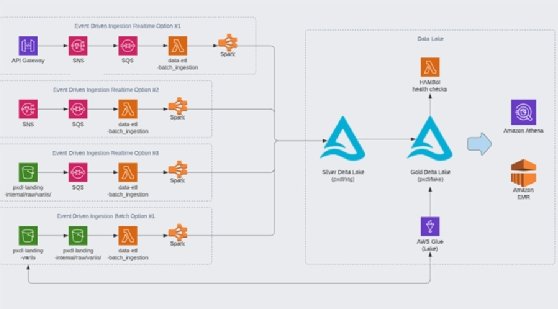
However, developers ran into a potential bottleneck with ingesting a high number of large files, which can result in poor performance in the data processing engines. To solve this, Equinox built its data lake with the Delta Lake open source file format for its underlying storage engine. Delta Lake supports upsert operations and native compaction, both of which reduce file size.
By integrating with Glue, Delta Lake acts as a central repository for all data. From there, data analysts and business intelligence teams can query the data they need and analyze it with Athena.
With this event-driven setup, Equinox launched VARIS with a predictable, low-cost profile without any scalability issues.
Event-driven analytics with BMW
Global organizations like BMW can struggle to store and centralize all the data they receive. BMW's ConnectedDrive back-end service processes over 1 billion requests per day from its vehicles. Analysts need to access this data for modeling or use cases, whether they're in Germany or Japan. The re:Invent session "How BMW Group uses AWS serverless analytics for a data-driven ecosystem" digs into the company's data pipeline.
BMW's Cloud Data Hub is a central data lake that ingests, orchestrates and analyzes data. This serves BMW's own global IT group, as well as its data scientists and business analysts who build use cases and machine learning models. BMW uses AWS Glue and Kinesis Data Firehouse to ingest data; Amazon S3 and Glue for organization and orchestration; and Amazon SageMaker, Athena and Amazon EMR to analyze it.
Let's look at the setup.
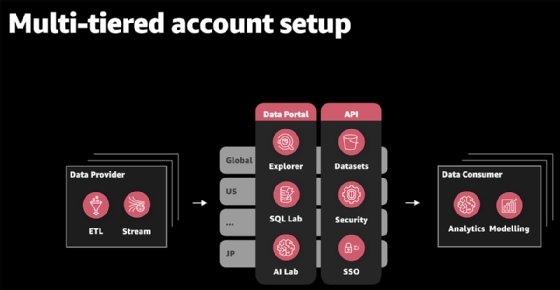
This is a multi-tiered account setup, which means every data provider or consumer has its own AWS account -- more than 500 in total. There are three main components to this setup:
- data ingestion through Glue and Kinesis stream providers;
- data orchestration through the data portal and API layer; and
- data analysis through data consumer.
BMW software and data engineers run the automaker's data marketplace, where they build both global and local data ingests. On the other end of the pipeline, analysts can access data under their AWS account.
"The single most important feature [of Cloud Data Hub] is the central data portal," said Simon Kern, lead DevOps engineer at BMW Group. "It's really the single point of contact for you if you want to get data from the BMW Group or if you want to build a new use case."
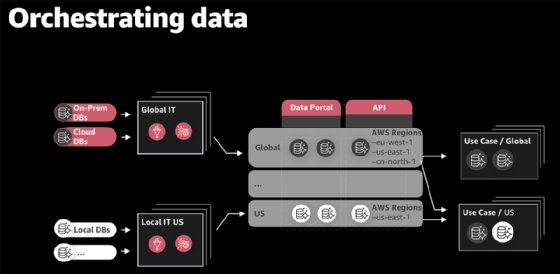
Within the central data portal, analysts can explore and query data sets through SQL, manage metadata and deploy any necessary infrastructure. Data sets are made up of S3 buckets and Glue, which stores the metadata and is specific to either its global or a local hub. These data sets rest on universal APIs that handle the management of data sets, as well as security, compliance and single sign-on.
Ingestion and analysis are relatively simple. As we previously mentioned, there are two ways data enters the Cloud Data Hub:
- AWS Glue. Data can be processed from relational databases.
- Amazon Kinesis. Data can stream in from BMW's connected vehicle fleet.
The data then moves through the data portal and API, where it can be used in AWS services such as Amazon SageMaker, for building machine learning models, and Athena, for data analysis.
Like Equinox, BMW ran into a file problem after ingestion. To solve this, it built a compaction module running on Glue. This module crawls, finds small files and compacts them into bigger ones.
BMW started this project in 2019 and has since ingested 15 systems and 1 PB of data.





