polyglot programming
What is polyglot programming?
Polyglot programming is the practice of writing code in multiple languages to capture additional functionality and efficiency not available in a single language.
In a broad sense, a polyglot (Greek for many tongues) is a person who can speak and use at least four languages. They might also be able to understand other languages. The idea of polyglot can be extended to the practice of programming.
Thus, polyglot programming is an approach in which programmers write code in more than one language to capture the benefits or efficiencies of all these languages, as well as extend the functionality of the software product being built. For the same reasons, they might also use multiple frameworks, services, databases, and modularity approaches like object-oriented programming (OOP) and functional programming to develop an application.
The need for polyglot programming and polyglot programmers
Polyglot programming is considered necessary when a single, general-purpose language cannot offer the desired level of functionality or speed, interact properly with the database or the desired delivery platform, or meet end-user expectations.
Focusing on a single language can be beneficial in some ways. For instance, programmers who specialize in Python or Java can build their expertise in developing application back ends. Similarly, programmers specializing in HTML or cascading style sheets (CSS) tend to be experts at building websites and web applications.
But in some cases, it might be necessary to use the paradigms and ideas from different languages to build a more useful application. Here's where polyglot programming and polyglot programmers come in.
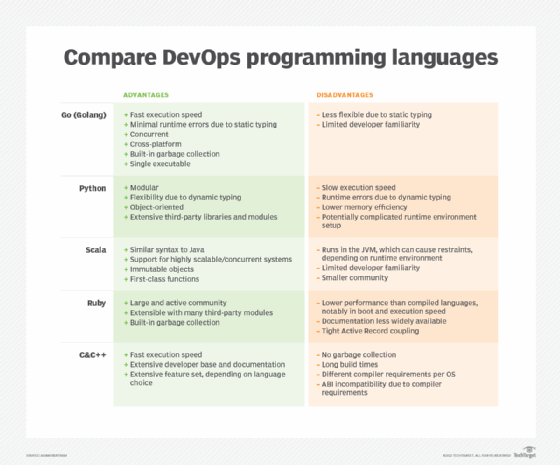
Polyglot programming in the real world
The use of domain specific languages (DSLs) has become a standard practice for enterprise application development. For example, a mobile development team might employ Java, JavaScript and HTML5 to create a fully functional application. Other DSLs -- such as Structured Query Language or SQL (for data queries), Extensible Markup Language or XML (embedded configuration), and CSS (document formatting) -- are often built into enterprise applications as well.
But when there is a need to combine some or all these languages into an application, polyglot programming is required. One developer might be proficient in multiple languages, or a team with varying language skills might work together to perform polyglot programming. Either way, polyglot programming provides more choices of languages so teams can select the ones that suit them (and the application) best.
What are the benefits of polyglot programming?
Proponents of polyglot programming contend that using the most effective language for each aspect of a program enables faster development, greater comprehension for business stakeholders, and a more optimal end product. In addition, shorter development timelines often means a simplified codebase, which streamlines code maintenance and updates. It also improves communication and collaboration among developers during the software development lifecycle (SDLC).
Polyglot programming means adopting a technology-agnostic approach to software development. This approach enables businesses to not get weighed down by a particular language or tool but choose the best language and tool -- or languages and tools -- for their requirements.
The approach also allows developers to be more flexible when choosing languages. Such flexibility means that they don't have to restrict themselves to working with only one language to build a product or solve a problem. Removing these restrictions improves their creativity, efficiency, and productivity, which ultimately enables them to build a better product.
Polyglot programming is also essential for organizations looking to benefit from infrastructure as code (IaC). IaC is the idea of provisioning and managing enterprise infrastructure through code, specifically using configuration files. Codifying the infrastructure brings automation into provisioning workflows, making it easier to manage the infrastructure. Also, eliminating manual processes brings greater transparency and version control into provisioning and prevents ad hoc configuration changes. However, implementing IaC requires system admins and site reliability engineers (SREs) to know multiple programming languages. In other words, they need to be polyglot programmers.
Drawbacks of polyglot programming
Integrating a wide variety of languages into a single application might entail added complexity. Resource consumption might increase in terms of training, testing and maintenance. Polyglot programming might also make code difficult to deploy if operations is not familiar with the same languages used in development.
But in general, the benefits of polyglot programming outweigh its drawbacks. And teams comprised of skilled polyglot programmers tend to create better quality software products than teams comprised of language specialists.
What is the future of polyglot programming?
The emergence and increasing adoption of Agile development practices have contributed to the growth of polyglot programming. Due to the dominance of Agile, more software engineers now work across the stack -- an idea known as full-stack development -- instead of limiting themselves to a specific part of it. And this is only possible if they are comfortable using multiple languages and frameworks, that is, being polyglot programmers. If development teams and organizations adopt Agile practices, they will be open to the idea and benefits of polyglot programming.
The availability of low-code development platforms also facilitates polyglot programming. These platforms enable developers who previously specialized in a front-end or back-end language to easily adjust to a new language and create full-stack applications using both kinds of languages. They can also build and test an application faster and accelerate its time-to-market and time-to-value.
Read about in-demand programming languages devs should get to know and compare six top programming languages. Check out this brief breakdown of declarative vs. imperative programming and the top four best practices to secure the SDLC.







