
Sergey Nivens - Fotolia
Try this data science experiment for deep learning insights
Deep learning professionals require a specific set of skills and tools. Follow this simple example of a data science project to learn more about the technology and related careers.

Many of the machine and deep learning services available in the cloud are based on the same common algorithms and neural networks that arose from academia. And while cloud providers, including Amazon, have made these technologies more accessible to the enterprise, IT teams still need a basic understanding of data science tools before they use them.
Kaggle, a data science and machine learning technology provider, issued a survey to 16,807 IT professionals who work with deep learning. It asked 290 questions pertaining to job skills, salary, work benefits and more.
Let's take a look at this raw survey data as the basis for a simple data science experiment -- though, you can use any data set for this type of work. The Kaggle data is far too large to load into a spreadsheet, unless your computer has lots of memory. And even if you could do that, you could not ask specific questions as you could with data science tools.
Databases are a better fit for this type of task, and below is all the code and instructions you need to conduct a data science project on this survey data. You just pick from any of the fields in the schema and change the questions to what interests you.
Dig into this data science experiment
Let's use Apache Spark and Databricks to convert a CSV file into a data frame, which is similar to an SQL table. It's easier to work with this type of data structure, as almost every programmer understands SQL.
Follow these instructions to install Spark, Databricks and the Kaggle data. These commands are for Linux, but the commands for Mac will be the same. For Windows, follow the instructions of each individual product vendor. However, most data scientists don't use Windows because it doesn't have all the built-in command-line tools that programmers use.
These instructions are for Spark version 2.1.1, which was built with Scala version 2.11.8. If you want to use a different version of Spark, you need to use a different version of Databricks.
sudo mkdir /usr/share/spark
cd /usr/share/spark
sudo wget https://archive.apache.org/dist/spark/spark-2.1.1/spark-2.1.1-bin-hadoop2.7.tgz
sudo tar xvfz spark-2.1.1-bin-hadoop2.7.tgz
cd spark-2.1.1-bin-hadoop2.7/bin
set PATH=$PATH:/usr/share/spark/spark-2.1.1-bin-hadoop2.7
Now, download and unzip the data from Kaggle:
wget https://www.kaggle.com/kaggle/kaggle-survey-2017/downloads/kaggle-survey-2017.zip/4
unzip kaggle-survey-2017.zip
Then, download the Databricks JAR file:
wget http://central.maven.org/maven2/com/databricks/spark-csv_2.11/1.5.0/spark-csv_2.11-1.5.0.jar
Next, you want to run the Spark Scala shell, but first, load the Databricks CSV file parser. Copy the Databricks JAR file and Kaggle data to the same directory so that, when you run the spark-shell command below, you do not need to give it any path directives to tell it where to look for either one.
spark-shell --packages com.databricks:spark-csv_2.11:1.5.0
Copy and paste the following code right into the Spark command-line shell. It only takes three lines of code to read the multipleChoiceResponses.csv text file into the data frame.
import org.apache.spark.sql.SQLContext
val sqlContext = new SQLContext(sc)
val df = sqlContext.read.format("com.databricks.spark.csv").option("header", "true").option("inferSchema", "true").load("multipleChoiceResponses.csv")
Now that we've set up this data science experiment, you can run queries with select(), show() and other data frame commands. Below, we see that the average salary for people working in data science is $70,787 via the mean() data frame function.

You can also show the survey participants' college area of study. Add an integer value, like 3,000, to show() -- otherwise, it will only show the first 20 results. We use groupBy() and count() to collect and count common values, which enables us to see that 2,200 data scientists studied mathematics. Consequently, many programmers struggle with machine learning, and it helps to have knowledge of multivariable calculus, linear algebra and statistics.

You can also sort which computer programming language you should learn first. Python is the most popular language. Spark is written in Scala, another helpful language to learn. While Scala is far more complicated than Python, many programmers write in Scala because it is a functional language -- meaning it is written like math equations.
Many programmers suggest R, but I would avoid that. The R programming language is mainly for statisticians -- not strictly big data scientists -- which means it is used in purely scientific fields, such as pharmaceutical research, more than with business applications.

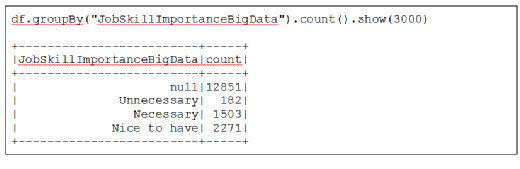
Now, we will use this data science experiment to ascertain the importance of certification. As you can see, most programmers did not respond. As with other technologies, certifications are rarely as valuable as demonstrated ability, such as GitHub projects and work experience.
Finally, we ask how many women are in the data science field.

Now that you have the tools, you can run different queries to change the fields to ask different questions and return results from the schema.





