Databricks enables Delta Live Tables in data lakehouse
Databricks is looking to make it easier for users to build data pipelines to extract, transform and load data from any source using a Spark SQL data query.
Data lakehouse platform provider Databricks is expanding its capabilities with the addition of Delta Live Tables, in general availability on Tuesday.
Databricks, founded in 2013 and based in San Francisco, develops a data lakehouse platform that brings structure and data governance capabilities to data lakes. In May 2021 at the Databricks virtual Data + AI Summit, the company first revealed its plans to develop Delta Live Tables (DLTs), technology to help get data in and out of a Delta Lake deployment. With the new feature, users can write a Spark SQL query that creates an ETL data pipeline to bring data into Delta Live Tables.
At a time when companies want access to data faster than ever, the ability to focus on data purely as a digital asset is important, according to Hyoun Park, CEO and principal analyst at Amalgam Insights.
"Databricks is simplifying the work necessary to create enterprise data pipelines by allowing data teams to focus on the SQL, and not on the software engineering and infrastructure support needed to support data pipelines in production," Park said. "This will allow data engineers to focus on bringing in new data and dealing with new formatting challenges, rather than spending time on fixing and monitoring already-existing data pipelines."
How Delta Live Tables affects the data lakehouse
The goal of DLT is to make it easier for users to manage the flow of data into a data lake, explained Michael Armbrust, a distinguished software engineer at Databricks.
"There's always this problem with data sets, where you need to prepare them, you need to filter them, augment them and do the process of ETL [extract, transform and load] to get them ready for consumption," Armbrust said.
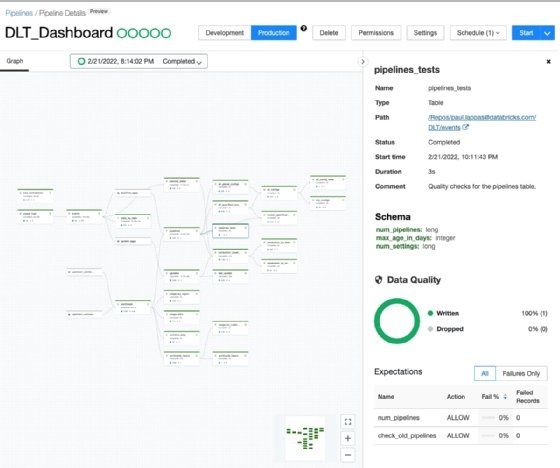
Databricks Delta Live Tables provides a dashboard view that helps users build and visualize data pipelines.
He noted that he's seen people who are very good at writing SQL queries face challenges when trying to turn a query into a data pipeline that moves data. Armbrust explained that Delta Live Tables provides users with a declarative language to specify statements defining what tables should exist, what the contents should be and what the dependency is among those statements. With DLT there is a complete description of all the tables that exist in the data lakehouse, he added, with version control that provides visibility into data lineage.
"A key idea here is that you should be able to treat all of your data as code," Armbrust said.
Databricks is simplifying the work necessary to create enterprise data pipelines by allowing data teams to focus on the SQL.
Hyoun ParkChief analyst, Amalgam Insights
Delta Live Tables make use of Spark SQL to allow users to build a data query as a data pipeline. As an example, Armbrust said that if a user wanted to create a Delta Live Table from a streaming data source such as Apache Kafka, that can all be done with a Spark SQL query. The user would first write a Spark SQL query to get the data; the query could define what data transformation is required and then put the data into the right tables in the data lakehouse.
Delta Live Tables integrate data quality and change data capture capabilities
Simply ingesting and transforming data isn't enough to ensure a useful data pipeline. What's also needed is some kind of data quality functionality to help ensure that the data is accurate, complete and up to date.
Data quality is part of the release of DLT according to Armbrust, enabling users to set what he referred to as expectations for a given data set. Databricks is not currently using the popular open source Great Expectations data quality technology, which is backed by commercial vendor Superconductive to set expectations in Delta Live Tables. Looking forward, though, Armbrust said that there is a plan to provide some form of future integration with Great Expectations.
change data capture (CDC) is also part of the general availability release of Delta Live Tables. With CDC, Databricks is able to get data coming from a database and ensure that it's all put in the right format in the table. CDC is also a bidirectional capability that can let users stream data updates from a Delta Live Table to another data source.
The goal for Armbrust and Databricks moving forward is to continue to improve the scalability and performance of Delta Live Tables.
"I think we have some really cool ideas about how we're going to continue to improve Delta Live Tables to make pipelines operate more cost effectively," he said.