
Getty Images
A beginner's guide to cloud-native application development
Cloud-native applications have become ubiquitous in IT environments. Review key principles, patterns and developmental factors to keep in mind before creating a cloud-native app.

Not all organizations define cloud-native applications the same way. At its core, cloud-native means that developers design, develop and deliver a specific application with the scalability and ephemeral nature of the cloud in mind.
Microservices and containers are often associated with cloud-native application development because apps created in the cloud tend to follow modern development practices. In contrast to the traditional Waterfall software development lifecycle, cloud-native applications are developed with a more Agile methodology. Changes are frequently released into a production environment through automated delivery pipelines, and infrastructure is managed at the code level.
The ephemeral nature of the cloud demands automated development workflows that can deploy and redeploy as needed. Developers must design cloud-native applications with infrastructure ambiguity in mind.
Cloud-native architecture principles
Before diving into development, let's break down some of the most common architecture principles that cloud-native organizations rely on.
Containerization
Most frequently associated with Docker, containerization is a form of virtualization where applications are configured to run in isolated environments, called containers, while still using the host OS' kernel. Containers are much more lightweight than traditional virtualization. They rely on the host OS to do much of the heavy lifting, rather than a hypervisor or other VM layer.
The advantage of containerization in a cloud-native environment is that containers are lightweight, portable and -- most importantly -- repeatable. This enables developers to write, test and deploy applications in consistent environments while minimizing cost.
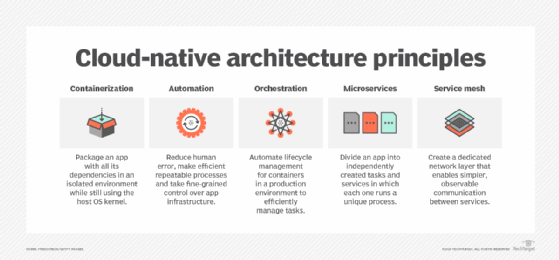
Automation
Cloud-native organizations use automation to reduce human error, make repeatable processes more efficient and take fine-grained control over their application infrastructure.
While it is possible to manually build, test, deploy and manage your application infrastructure, cloud providers offer tools to abstract away many of those manual processes. This enables cloud-native organizations to be more efficient in everything from their hiring to their infrastructure needs.
Orchestration
While containerization can reduce costs by packaging lightweight services, getting the most out of them in a production environment requires a strategy called orchestration. In a nutshell, orchestration is the process of automating the lifecycle management of all containers in a production environment to efficiently manage tasks like container creation and destruction, horizontal scaling, version control, and networking and dependency management.
Kubernetes is one of the most popular tools for container orchestration; however, there are alternatives. The more lightweight Docker Compose, for example, is often used for local orchestration. However, regardless of the tool, the successful management of production resources nearly always requires some sort of orchestration.
Microservices
When combined, the concepts of containerization and automation lend themselves well to an architecture pattern known as microservices architecture. This pattern is defined by the presence of complex applications that are composed of many small, independent services that can scale and change independently.
A microservices architecture is common in a cloud-native environment, as the inherent nature of orchestration and containerization lend themselves well to this pattern. This is in stark contrast to monolithic architectures, which are more tightly coupled and, consequently, require more resources and are more difficult to scale in the same way.
Service mesh
In a cloud-native environment, the service mesh is the glue that holds all the disparate services together. As applications scale, especially in a microservices architecture, monitoring and managing the different components can be particularly challenging. The service mesh creates a dedicated network layer that enables simpler, observable communication between services. It generally supports several features, including load balancing, encryption and disaster recovery.
Cloud-native patterns and best practices
While the tools and architectural standards of a cloud-native environment are important, using them effectively requires following commonly accepted best practices and patterns. Many of these practices fall under the umbrella of DevOps, a software development approach that emphasizes continuous improvement, automation, collaboration and shared ownership in order to improve the speed, quality and reliability of the resulting products.
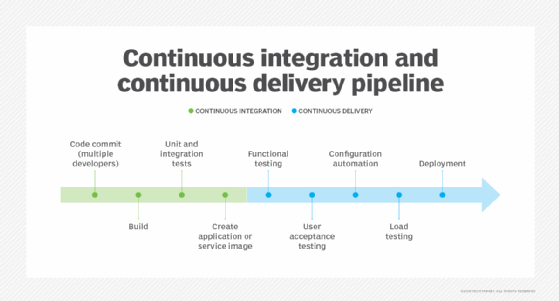
Continuous integration
One of the primary advantages to a cloud-native application development strategy is the incentive to release changes early and often. Because of the tooling and other automation inherently available within the typical cloud environment, the practice of CI is particularly valuable, as it enables developers to test and release their code frequently.
CI adds a tighter feedback loop, wherein code changes are built, packaged and tested automatically following Agile principles. This enables earlier and more reliable detection of issues, since the underlying infrastructure and its management ensure that all changes are run in the same way and on the same infrastructure.
Immutability
What makes cloud-native infrastructure so predictable is its inherent immutability. Immutability means that the infrastructure itself cannot be changed once deployed. For example, in containerization, this means that, once a container is built, it doesn't change over time. Its definition file manages its configuration, the orchestrator manages its lifecycle and the service mesh connects any dependencies.
Rather than mutable infrastructure, such as hand-managed bare-metal services, the immutability of cloud-native infrastructure ensures higher reliability. In the event of an unexpected failure, immutable resources can be recreated in an identical way, which can reduce downtime. This also helps increase security. Reducing the potential for configuration changes means that version control manages resources. Each released version is not only distinct from the others, but it can be programmatically verified.
Infrastructure as code
Infrastructure as code (IaC) is at the heart of a well-defined cloud-native strategy. Rather than using physical or interactive configuration tools, IaC takes from standard software development practices and enables managing and provisioning infrastructure using machine-readable files.
This enables IT teams to manage underlying application infrastructure in the same way that all other source code files are managed. Concepts like version control, reproducibility, automation and end-to-end testing can be applied to the resources that application software runs on, in addition to the software itself.
Serverless
Taken to their extreme, containerization, orchestration and microservices can all be abstracted away by a concept known as serverless computing. While the name itself implies that there are no servers, the reality of serverless computing is that the servers are abstracted completely away.
Rather than long-running containers, serverless computing is characterized by its event-driven and stateless nature. While it can be a challenging transition from non-serverless computing methods, serverless computing enables cloud-native developers to focus almost entirely on code, rather than infrastructure. When implemented properly, this can help reduce costs by ensuring that only the resources used are billed.
GitOps
The vast majority of cloud-native applications are managed using a software development approach known as GitOps. As the name suggests, GitOps is a DevOps-inspired methodology that uses a version control system -- typically Git -- as the source of truth throughout the entire lifecycle of an application, from development to the infrastructure.
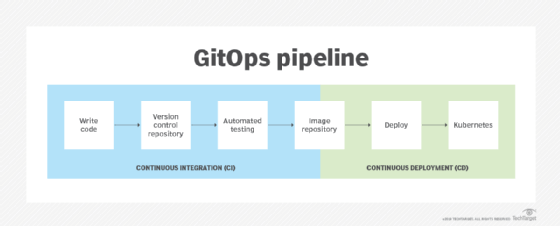
GitOps uses the software development best practices built into the Git ecosystem to enforce the review and validation of IaC files. This encourages the use of immutable infrastructure, uses existing automation tools and helps maintain effective change management.
It is an effective way to understand not only what is happening within an application's cloud-native infrastructure, but also how and why. Additionally, it creates a well-versioned history of changes, which enables more resiliency by eliminating the risk of any one change. In most cloud-native organizations, GitOps is the primary driver of evolution and innovation.
Cloud-native development methodologies
There are a few factors of the 12-factor app methodology -- a go-to reference for application developers -- that are foundational to cloud-native application development, which are detailed below.

Build, release, run
The build, release, run approach separates each stage of the development and deployment of cloud-native applications:
- Build. An application's codebase goes through the build state, where it's transformed from raw source code into an executable bundle known as the build.
- Release. The build is then combined with any necessary configuration values that are required to run in the targeted environment. This is known as the release.
- Run. The release executable is run in the targeted performance environment.
This well-defined workflow is often coupled with a deployment and CI tool, like Jenkins or Capistrano, which can run automated tests, roll back to previous builds and more. If something goes wrong, developers can rerun a prebuilt release in an environment or on a different infrastructure without having to redeploy the entire application.
Processes
In cloud computing, decoupled, stateless processes are far more scalable and manageable than stateful ones. While it can seem counterintuitive to develop a stateless process, it emphasizes the reliance on stateful backing services that enable the stateless processes to scale up and down -- or reboot altogether -- with minimal risk to the application's quality.
While you can execute cloud-native processes in any number of ways, some targeted environments, such as Heroku, offer their own runtimes that are based on configuration values provided by the developer. This is commonly done through a containerization technology, such as Docker or Kubernetes. Containers are an excellent way to encapsulate the single process required to run a given application and encourage the use of stateless applications.
Concurrency
Cloud-native applications are hardwired to be horizontally scalable. These apps isolate services into individual stateless processes that can handle specific workloads concurrently. Processes are efficiently scalable when they're stateless and unaware of the other independent processes.
Concurrency is a great example of why many cloud-native applications lean toward service-oriented architectures. Monolithic applications can only scale so far vertically. Each component can scale more effectively to handle a load when a developer breaks a monolithic app into multiple targeted processes. A host of tools are available to automate the management and scaling of these processes, including Kubernetes and other proprietary services from cloud service providers.
Disposability
Several cloud providers offer more volatile infrastructures at a reduced cost. This promotes cheaper scalability but comes with the risk of the sudden disposal of processes. While this isn't always the case, cloud-native applications designed for disposability emphasize the importance of self-healing applications.
Plan for unexpected failures to enable smoother shutdown procedures and store any stateful data outside of the isolation of the process. However, it is easier to design a self-repairing system using orchestration tools, like Kubernetes, and comprehensive queuing back ends, such as Amazon Simple Queue Service or RabbitMQ.
Zachary Flower, a freelance web developer, writer and polymath, strives to build products with end-user and business goals in mind and an eye toward simplicity and usability.







