Part of:Key components of a cloud compliance strategy
Guard information in cloud with a data classification policy
The cloud's need for special data classification attention arises from a combination of risk factors. With proper care, classification and compliance can limit these risks.
When IT teams assess if information should be stored in the cloud, data classification should be an essential concern.
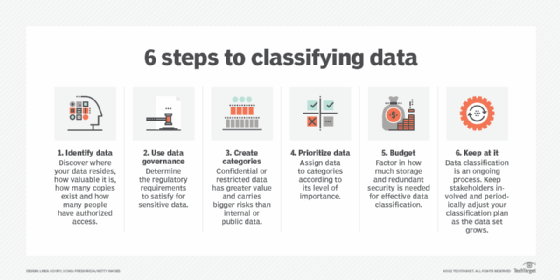
A cloud data classification policy should start with the data classification policies already in place for the company. Most policies divide data into two categories, such as public and protected. Cloud data classification should be more granular to reflect questions of risk tolerance.
Since the General Data Protection Regulation (GDPR) is almost universally mandated, we'll use it as an example. GPDR arises out of the fact that online business relationships allow companies to find out a lot about their users. This data collection could compromise privacy and even security if not controlled. The primary principle of GDPR is that it protects anything that picks an individual out of the masses, even if it doesn't name them. If a data element, or a combination of linkable elements, allows for direct or indirect identification, then it's regulated. That's the major step that separates cloud and traditional data classification.
Create more classification categories
To adapt your current data classification strategy for a cloud computing environment, understand that public and protected categories aren't enough. At the minimum, cloud data classification needs a category that consists of data that is specifically linked to someone and that, if combined with other such data, might be enough to let someone profile an individual. This would include information such as location, sales, calls or messages sent or received. Note that even vertical-specific regulations such as HIPAA in the U.S. can also be mapped to this personal category, making this approach universal.
GDPR and other privacy regulations applied regularly to online and cloud activity also generate a second new category, one that can be labeled as highly sensitive. This information is enough in itself to present a risk of identifying an individual. A person's name, address, government ID and similar information fall into this category.
Review the current data classification policies and assign some of the data in each to one of the new categories. At the same time, review how you record data classification for each of the data elements. If classification assignments aren't firmly tied to the data, there's little chance the process of classification will be effective. That can result in your company facing legal action.
Implement a tagging strategy
The next step is to decide how you will maintain classification tags for data if it's moved to the cloud. All major cloud providers support some mechanism for resource tagging, and you should define that mechanism -- or multiple mechanisms, in the case of multi-cloud -- for each category. Be as granular as possible here -- a database could have data with multiple classifications. If no per-field classification is possible, assign a tag that represents the most stringent protection level for any field and also if the data includes anything in the GDPR-linked personal classification.
For personal classification, there is a unique risk that a collection of nonspecific data will combine and can indirectly identify individuals.
Data classification tools, such as Spirion, Netwrix and Ground Labs are essential. These tools can identify likely classifications for data elements, record classifications at a varied level of granularity and map the linkage between elements that may be the same or derivatives.
If data deduplication has been implemented, it should be possible to identify and tag each data element and ensure that all data is tagged correctly. Otherwise, some form of data identification and element linkage can ensure that all copies of the same data are tagged the same way. Some organizations may need to employ data discovery procedures or tools to handle this step.
Adjust data management practices for cloud
Generally, enterprises can handle all categories -- except the personal classification -- the same in the cloud as in the data center. However, you will need to double check any classifications that represent restricted storage or access for security if they're hosted in the cloud. Enterprise should never move or store data in the cloud without reviewing the classifications associated with it and ensure that cloud security of the data is adequate.
For personal classification, there is a unique risk that a collection of nonspecific data will combine and can indirectly identify individuals. Move this data type only when combination-based identification is not possible, or when the combinations that might permit identification are prevented.
In many cases, cloud applications use a series of databases that may collectively pose a risk to personal data, depending on how they are accessed. Stateful components -- ones that store data internally -- may also pose a risk, so this type of data should be considered a database from a compliance perspective.