Aparavi update adds better data classification, more clouds
Aparavi updates Active Archive with customizable data classification and tagging capabilities for easier future retrieval and improved metadata search.
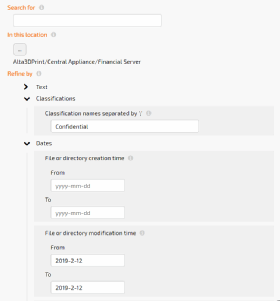
Aparavi is trying to shine light on dark data with its Active Archive product, adding the ability to tag and classify data based on words, phrases, dates, file types and patterns.
Aparavi Active Archive's updated search engine can locate files by their metadata, including by the new, user-determined tagging and classification. This search is done across the entire archive, whether on premises or on a cloud, even if the user doesn't know where the data resides.
This feature gives customers a tool to make their unstructured data searchable, so it doesn't just get lost in a growing bank of dark data. Victoria Grey, chief marketing officer at Aparavi, said many organizations face the problem of sifting through millions of files in a massive, opaque pool to find specific data.
"They don't really know what they have, and the IT department is tasked with managing, retaining, making available and finding this data," Grey said. "They have no way to really organize it or find specific data. Meanwhile, it's filling up expensive on-premises storage."
Grey said Aparavi's goal is to give customers a way to get a handle on long-term data management by allowing them to organize it and then easily find and retrieve it.
Aparavi was founded in 2016 and launched Active Archive in May 2018. Active Archive is a cloud data management platform with cloud data protection and disaster-recovery-as-a-service capabilities. It is Aparavi's only product.
A 'meta' solution to a growing issue
Unstructured data growth is a known problem in the storage world, but according to Steven Hill, senior analyst at 451 Research, there hasn't been an industry-wide standard way of dealing with it. He thinks the proper use of metadata will be the answer, which is how Aparavi is attacking the problem.
To me, metadata is the tool that will save us. It provides a mechanism by which you can do policy-based management. This is the evolution toward more intelligent storage.
Steven Hill Senior analyst, 451 Research
"To me, metadata is the tool that will save us. It provides a mechanism by which you can do policy-based management," Hill said. "This is the evolution toward more intelligent storage."
Hill said that most organizations have a tendency to hoard data, driven by a combination of compliance, recordkeeping and fear of losing anything that may prove useful in the future. "No one wants to be the guy who deleted something," Hill said.
This means everything gets stored, unlabeled in any meaningful way, in a big repository. "Storage was just a big old place you threw your crap into," Hill said, describing how unstructured data grew out of control. The problem with using storage as a dumping ground, he said, is having to sift through it.
Sifting through it becomes necessary for e-discovery, or to comply with a GDPR "right to be forgotten" request. Hill said being able to trawl through oceans of data to find the right files starts with proper classification and tagging of metadata.
Active Archive can search by classification.
However, even though Aparavi has provided a tool to bring structure to unstructured data, Hill said there is little chance an IT team is trained on proper metadata tagging and classification methods. This is because there are few, if any, established best practices for doing so.
"What these guys give you is the tools to do it, but they don't tell you how," Hill said. He said he believes the industry will eventually come up with a basic set of business metadata that should be stored with every piece of data, but we're not there yet. In the meantime, individual organizations will have to come up with methods that work for them. Aparavi Active Archive includes preset classifications to help start the process.
Aparavi added a handful of other features in this update. Active Archive can now archive data from a source system directly to a cloud, and Aparavi added additional cloud destinations. Altogether, Active Archive now supports AWS, Backblaze B2, Caringo, Cloudian, IBM Cloud, Microsoft Azure, Oracle Cloud, Scality and Wasabi.
Active Archive is sold as a service, which means the new features are available for all customers.