Troubleshoot Linux kernel panic with the kdump crash tool
Kernel panic renders your system useless. With an NFS server and kdump crash tool, you can easily perform a root cause analysis and figure out how to bring a system back online.
Kernel panic is a critical issue that manifests as a system freeze. If you're not familiar with what a kernel does, it is the core of an OS. Linux itself is a kernel, which enables developers to create numerous distributions.
A serious enough error at the kernel can cause an event known as kernel panic. This is similar to Window's blue screen of death, but instead of seeing a blue screen, you simply see a log output on a black screen.
Kernel panic can occur due to bad memory, driver crashes, malware or software bugs. To identify the cause of kernel panic, you can use the kdump service to collect crash dumps, perform a root cause analysis and troubleshoot the system.
To get started, you should have two VMs that run CentOS. This tutorial uses CentOS 8 as the Linux distribution for both the Network File System (NFS) server and client.
If you configure the client to send the crash dumps to an NFS share, you can centrally gather and analyze a crash dump without using the system that is affected by kernel panic.
Below are the IP addresses of the NFS server and client. Your addresses may differ depending on your subnet configuration, but both addresses are necessary.
NFS server
192.168.99.1
Client
192.168.99.71
At publication, the kernel version on CentOS 8 is 4.18.0-147.5.1.el8_1.x86_64. To find the distribution's Linux kernel version, use the uname-r command.
Install NFS
After you've set up your VMs and have the IP addresses for the intended NFS server and client, it's time to install everything with the following steps:
Use the yum install -y nfs-utils command to connect to the NFS server and install the NFS package.
Create a directory that will be used by NFS with mkdir /nfs-share.
Edit the /etc/exports file to allow the client to connect to the NFS share. The supplied IP address belongs to the client.
/nfs-share 192.168.99.71(rw,sync,no_root_squash)
Connect to the client, and create a directory to store the crash dump files; the default for kdump is /var/crash. You can make a directory with the name crash-dump in the root directory with a mkdir/crash-dump prompt.
Mount the new NFS share to the client's file system. The supplied IP address is to the NFS server.
mount -t nfs 192.168.99.1:/nfs-share /crash-dump
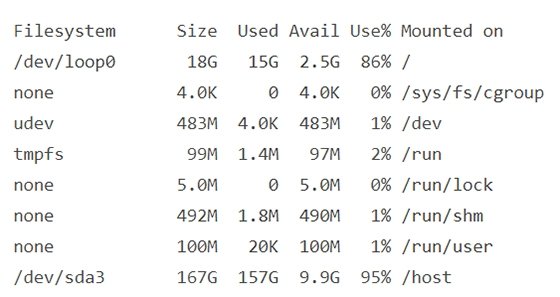
To verify NFS is correctly set up, run the df -h command. If the setup is successful, your screen should have the following output:
Verify and install kdump and crash tool
Now that you've designated a server to receive all the crash files, you should install the kdump tool and clarify what files will store all the crash info.
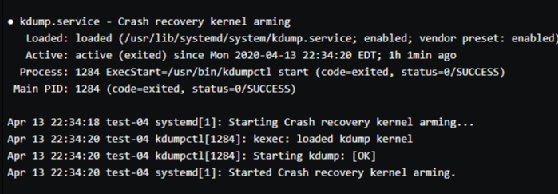
Verify the kdump service is running on the client.
Kdump is automatically installed on CentOS 7 and 8. Issue the systemctl status kdump command to check the status.
The following output should appear:
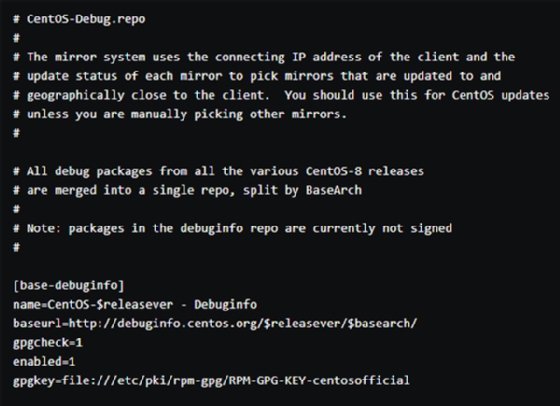
To install the kernel-debuginfo package on both the client and server, edit /etc/yum.repos.d/CentOS-Debuginfo.repowith a text editor. Set it to enabled=1.
The kernel-debuginfo package lets you inspect the crash dumps with the crash tool. Install the package with yum install -y kernel-debuginfo. Your interface should look like the following:
Then, modify kdump's default file upload location. To do this, edit /etc/kdump.conf, and change the default path from /var/crash to /crash-dump.
Crash the Linux kernel
Now comes the fun part: You must crash the kernel on the client.
Enter both echo commands below on the client:
echo 1 > /proc/sys/kernel/sysrq echo c > /proc/sysrq-trigger
echo 1 > /proc/sys/kernel/sysrq allows for all functions of SysRq. These prompts let you send low-level commands to the Linux kernel.
echo c > /proc/sysrq-trigger sends a sysrq command to trigger a crash.
Because you trigger the kernel panic with echo commands, kdump should send the dump files to the NFS share.
Connect back to the NFS server, and you can conduct a postmortem to find out what happened to the client.
Check to see if the dump files upload to the NFS server.
Within the /crash-dump directory, you should see a new directory when using the ls -lh command.
This new directory -- 192.168.99.71-2020-04-14-12:20:47 -- originated from the client and was created during the time of the crash.
Inside of the directory, locate the following two files: vmcore and vmcore-dmesg.text. Vmcore-dmesg.txt is the log file for dmesg during the time of the crash in plain text. Vmcore helps you use the crash utility to further investigate what processes and files potentially caused the crash.
Here is how you locate these files:
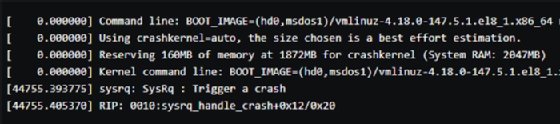
Inspect vmcore-dmesg.txt.
To quickly view the contents of vmcore-dmesg.txt, open the file in a text editor or grep for the word crash with the cat vmcore-dmesg.txt | grep -i crash command.
As you can see, SysRq triggered a crash when you issued the echo commands.
Use the crash tool
The crash tool helps you analyze a crash dump file. It comes preinstalled on CentOS 8. There are also commands to run and figure out what processes and files were live at the time of the crash.
On the NFS server, initialize the crash utility, and supply the following vmcore file: crash /nfs-share/vmcore /usr/lib/debug/lib/modules/4.18.0-147.5.1.el8_1.x86_64/vmlinux.
This changes the shell prompt to the crash prompt.
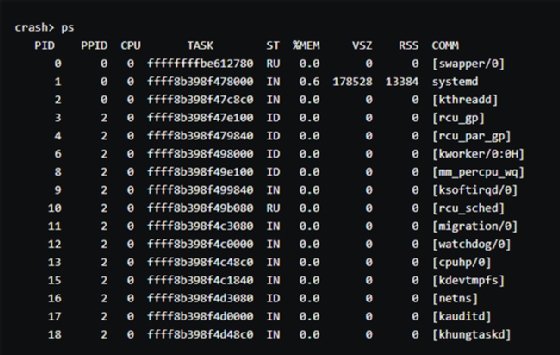
Then, use ps to check what processes ran.
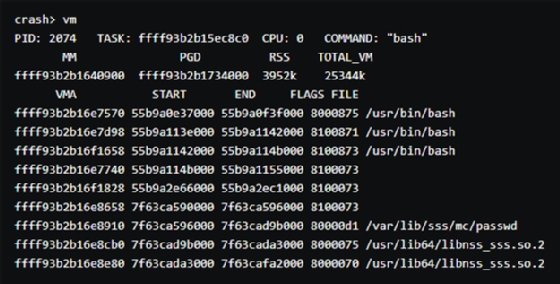
The vm command shows anything loaded in the virtual memory at the time of the crash.
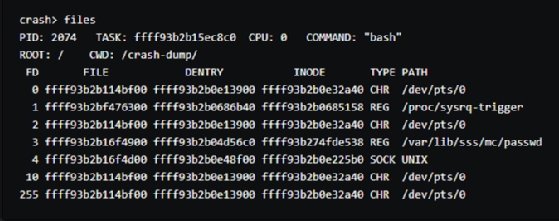
You can then use files to further examine what files were open at the time of the crash.
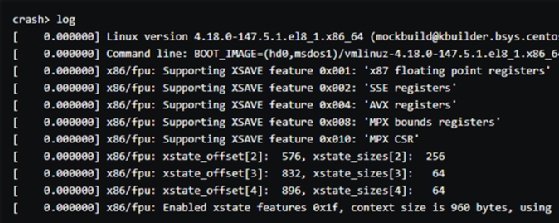
Run the log command to see any logs again; this prompt shows the same contents as vmcore-dmesg.txt.
With the information from the ps, vm, files and log commands, you can figure out what caused the Linux kernel panic with the kdump crash dump tool. The NFS server lets you upload crash dump files to a server independent of the affected server. Both vmcore-dmesg.txt and vmcore files can provide a glimpse of what was going on in the system when the crash occurred.
Dig Deeper on Data center ops, monitoring and management