DevOps overhauls app dev scripts
Applications don't run in a vacuum. Operations -- the last step of app development and maintenance -- actually belongs in every stage of the cycle.

A DevOps overhaul for application development and maintenance will pay off in app resiliency and performance. Better app performance can't begin with the operations team.
The application lifecycle starts with defining the purpose, scope and high-level constructs. This definition is refined into a software design that includes both architecture and user experience components. The engineering team develops the application based on the initial design. The operations team (in a traditional sense) then takes the finished application to deploy and operate on the enterprise's IT infrastructure.
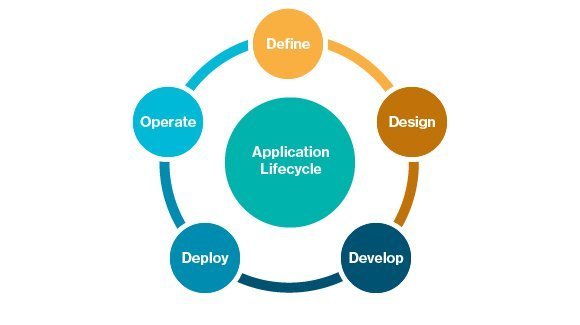 Figure 1. A traditional application lifecycle moves from definition through to operations.
Figure 1. A traditional application lifecycle moves from definition through to operations.
Along the way, the development teams tell the operations teams what is coming. A complex negotiation occurs over deployment architectures, service-level agreements (SLAs) and other factors. Once the application deploys, the traditional lifecycle model makes operations responsible for it.
All applications have this basic lifecycle (see Figure 1) from idea to development through maintenance. Integrating development and operations functions -- DevOps -- affects the way IT works in the enterprise, reshaping each stage of the application lifecycle.
Define with an eye on operations
In a product-centric culture, the application concept is a spin on the market requirements and product requirements documents (MRD/PRD). Rarely do MRD/PRD-style docs give any weight to operations; they are more focused on the feature, function and benefit statements of the application than on a holistic view of operations. With DevOps, however, any application definition that does not fully embrace operations is incomplete.
Design for scale
The design phase focuses on systems architecture and user experience. In a DevOps world, design integrates the deployment automation, performance management, monitoring and other aspects of operations.
Operations code is the responsibility of application developers.
A concept of design for operations is crucial: Design all components of the system to be manageable, recoverable and operated at scale. An application's design is not complete without a continuous delivery and operations model. Define the roles at this phase, specifically making the development team responsible for operations integration from the start.
The key design principles come from cloud-native operations: extensive use of services, infrastructure awareness, self-healing and recovery and distribution of data and storage, among others.
Application functionality should be delivered and operated as services. This goes beyond storage, compute, networking, database and so on. Account lookup? Service. Balance request? Service. Inventory update? All service.
Develop ops-ready code
During development, sprints include operations components inherently. Developers cannot check in code that is not ready for operations for quality assurance. Logging frameworks, resiliency hooks and other features are integrated into the code. Emerging operations and related services, such as Netflix open-source software, will be essential to a continuous integration and development model.
To support the rapid iteration and continuous deployment model, develop functionalities as fine-grained services that are loosely coupled through APIs and messaging middleware. Code failures must have a minimal "blast radius" so they do not harm the rest of the system.
Proper cloud-native coding follows the principles laid out in the design phase. Automated testing then catches code that doesn't adhere to these DevOps standards.
All of the operations scripting for deployment, management and related functions should be delivered during development. It's not acceptable to ship code and make the operations team responsible for automating its deployment. Operations code is the responsibility of application developers.
Deploy dynamically
In a traditional application model, deployment is infrequent and planned well in advance, emphasizing total control. In a modern DevOps model, successful deployment is equally important, but the model is very different. Developers test code themselves and check it in; the code progresses quickly through automated unit, system and integration tests.
Passed code deploys at various pre-defined windows, which could occur multiple times per day. Any code that is ready is deployed. This is where the fine-grained services and isolation implemented during development really pay dividends. Failure of a small service can make a big impact on the application, but rolling back to previously stable code is a lot easier if the service is compact and self-contained.
Operate with shared responsibility
Without DevOps, operations teams work in infrastructure silos and applications. There are storage, virtualization, networking and server management teams, and there are operations teams surrounding complete applications and systems.
The new model is to organize operations with their development counterparts in a model that is focused on services -- think back to our design phase. Each team member still needs expertise in key technologies, but this becomes a matrix model to distribute core skills where they are needed. Teams are responsible for service SLAs because the applications rely heavily on these services.
DevOps is often a difficult transition for IT organizations. Try using new incentives to align teams and individuals from very different perspectives and experiences. You can't make people change from an "us versus them" mentality to being jointly responsible for success or failure of entire systems and services without proper planning, communication and alignment.
About the Author:
John Treadway leads the products and software business at Cloud Technology Partners, with an entrepreneurial background. He first encountered shared resource pools playing computer games on an IBM mainframe using teletype terminals, and became an expert on on-demand, elastic, metered and shared resource pools and provisioning via cloud computing. Treadway is based in the Boston area.





