
Getty Images
When and how to run databases on Kubernetes
Deciding whether to move your database onto Kubernetes requires careful consideration, especially when choosing among deployment options. Here's what to keep in mind.

Although Kubernetes is best known for running applications, it's also capable of running databases. But it's important to carefully evaluate whether your database is a good fit for Kubernetes and how best to make it work in a Kubernetes environment.
There are two primary options for deploying a database on Kubernetes: StatefulSets and custom operators. Although a range of options exists, StatefulSets and custom operators are among the most popular choices, and which method to use largely depends on the type of database you're running.
When to use StatefulSets to run databases on Kubernetes
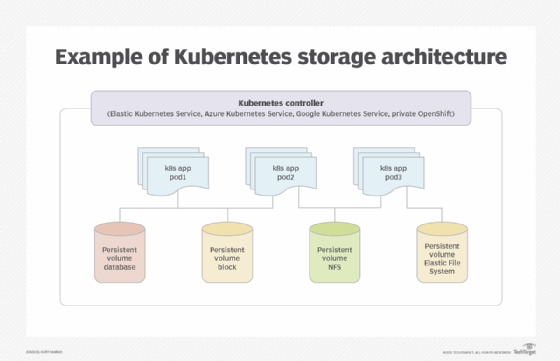
StatefulSets are a type of Kubernetes controller. They're well suited for databases because each StatefulSet can have an associated persistent storage volume with an assigned, unique network identity. This makes them handy for use with stateful applications, but they often require more work and planning than other Kubernetes controllers.
Because Kubernetes pods are dynamically created, scaled and deleted, an individual pod's permanence is not guaranteed. However, StatefulSets enable persistent storage, which lets the database application run in a pod while the data resides on the persistent storage volume.
This means that even if a pod is deleted, its data will remain. In addition, because the persistent storage volume has a known network identity, pods created in the future due to scaling will know where to find the application data.
The most important thing to keep in mind when using StatefulSets for hosting databases is that pods are not persistent. In fact, regard the pods as transient -- there is no expectation for any one pod to have a long lifetime. For that reason, choose a database platform that can handle constant creation and deletion of pods and that supports synchronous writes to the database.
In addition, some databases rely heavily on caching, which stores writes in memory or transaction logs until those write operations can be committed to a disk. The problem with this approach is that if Kubernetes scales down a workload, a given pod could be deleted before its transactions are committed to persistent storage, meaning that those transactions would disappear. Conversely, writing transactions directly to the database ensures data persists even if individual pods come and go.
StatefulSets vs. custom operators for Kubernetes databases
If you decide to run your database on Kubernetes, using StatefulSets is typically the easiest option, as long as your database adheres to the basic requirements for doing so. Conversely, using custom operators involves a lot more work but enables greater flexibility compared with StatefulSets.
When to use custom operators to run databases on Kubernetes
Like StatefulSets, operators are a type of Kubernetes controller. However, custom operators function as an abstraction layer, enabling applications not originally designed for Kubernetes to function in the Kubernetes environment.
While custom operators are closely associated with database management, they can also contribute to the database deployment process. Database applications often include multiple tiers and numerous components. Therefore, you might use a custom operator to ensure all the necessary components exist and start in the correct order.
The disadvantage of using a custom operator is that you must either use the Kubernetes Operator SDK to build your own custom operator or download an existing operator for your database platform. For those looking to build their own custom operator, the Kubernetes Operator SDK essentially functions as a development framework to create the logic necessary for managing database resources.
The functions that this framework enables vary widely from one database deployment to another. Some of the most common functions include creating and scaling database instances and facilitating database backups.




